PortaSpeech
v0.2.0
Implementación de Pytorch de Portaspeech: texto de texto a voz portátil y de alta calidad.
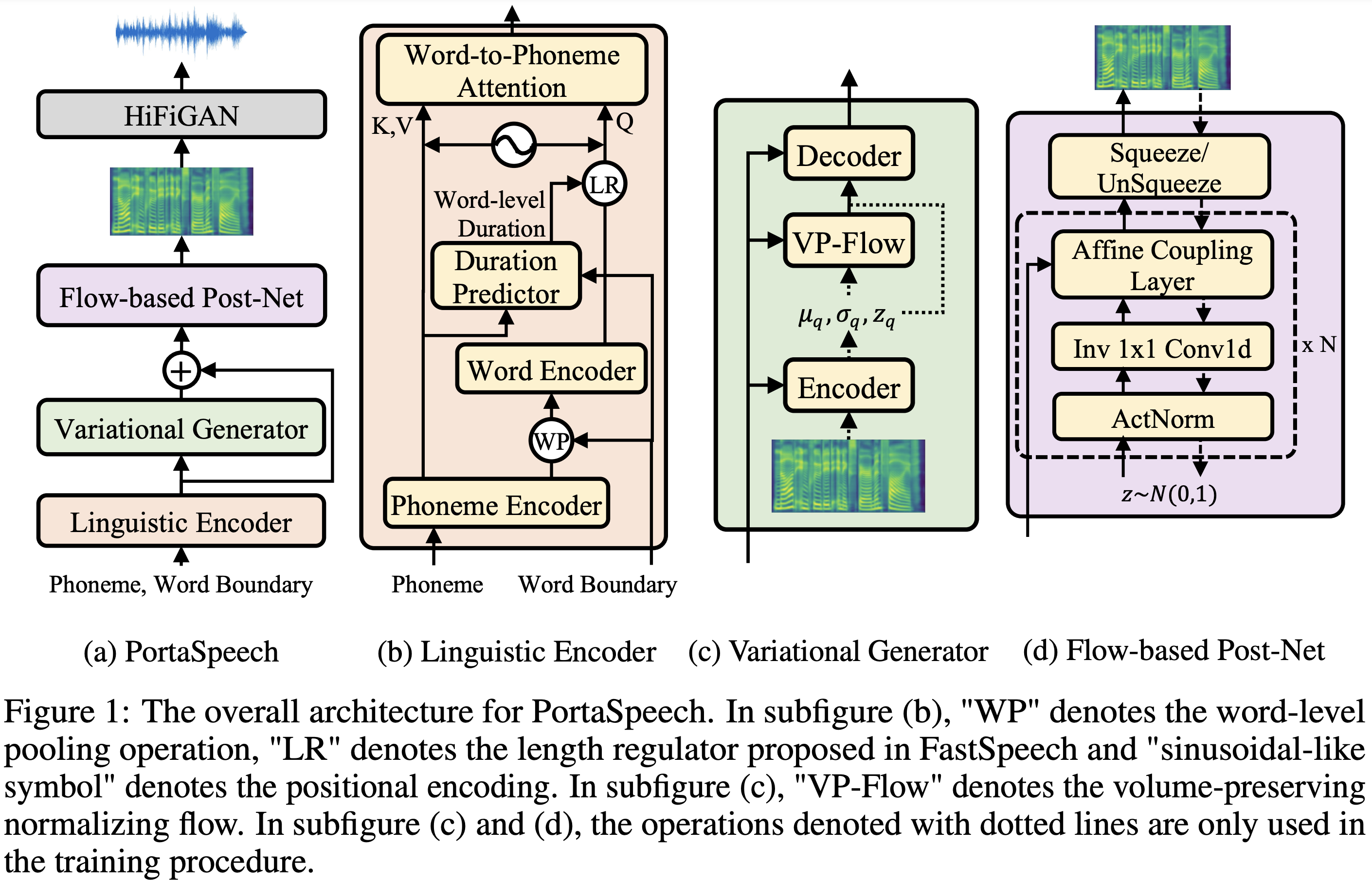
Las muestras de audio están disponibles en /demostración.
| Módulo | Normal | Pequeño | Normal (papel) | Pequeño (papel) |
|---|---|---|---|---|
| Total | 24m | 7.6m | 21.8m | 6.7m |
| Lingüística | 3.7m | 1.4m | - | - |
| Variacionalgenerador | 11m | 2.8m | - | - |
| Postón de flujo | 9.3m | 3.4m | - | - |
El conjunto de datos se refiere a los nombres de conjuntos de datos como LJSpeech en los siguientes documentos.
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Además, Dockerfile se proporciona para los usuarios Docker .
Debe descargar los modelos previos a la aparición y ponerlos en output/ckpt/DATASET/ .
Para un TTS de un solo hablante , ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todas las expresiones en preprocessed_data/DATASET/val.txt .
La tasa de habla de las expresiones sintetizadas se puede controlar especificando las relaciones de duración deseadas. Por ejemplo, uno puede aumentar la tasa de hablar por 20 por
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Tenga en cuenta que la capacidad de control se origina en FastSpeech2 y no es un interés vital de Portaspech.
Los conjuntos de datos compatibles son
Correr
python3 prepare_align.py --dataset DATASET
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/DATASET/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo.
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py --dataset DATASET
Entrena tu modelo con
python3 train.py --dataset DATASET
Opciones útiles:
--use_amp al comando anterior.CUDA_VISIBLE_DEVICES=<GPU_IDs> al comienzo del comando anterior.Usar
tensorboard --logdir output/log
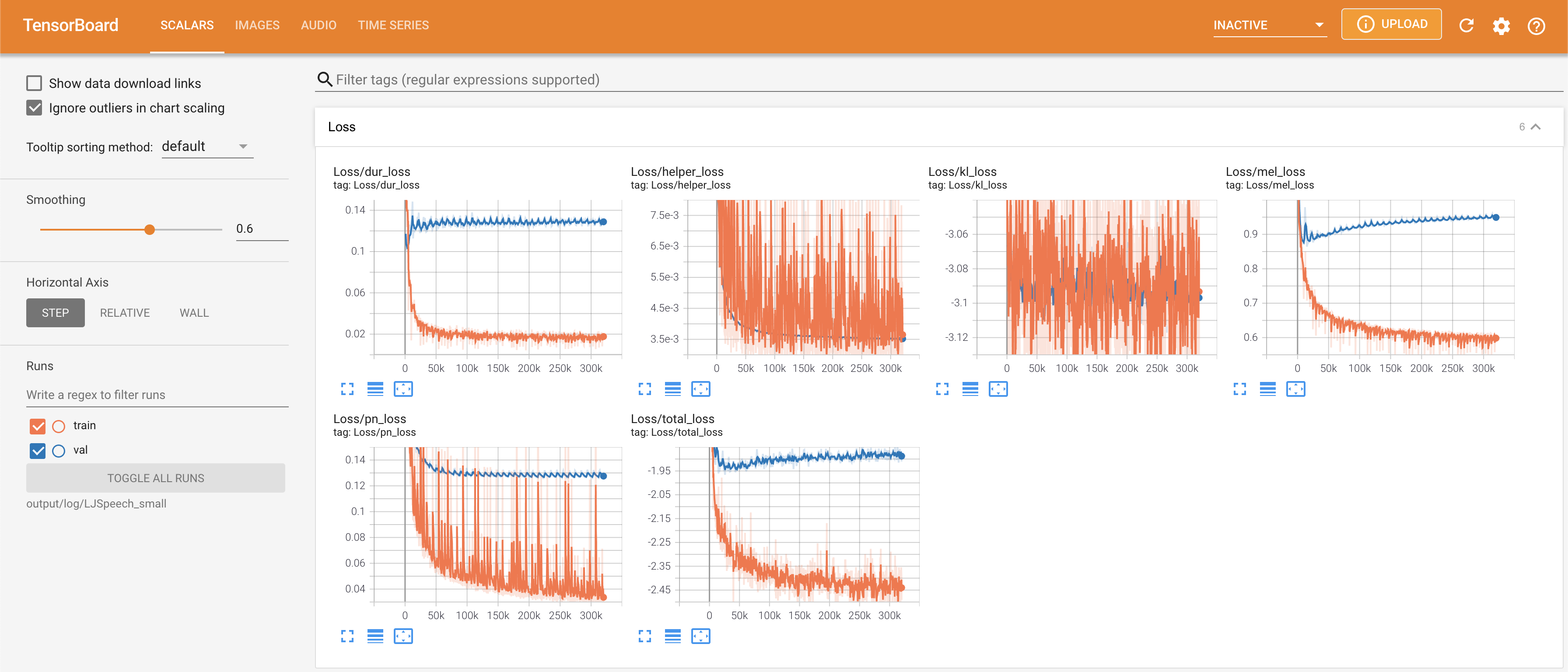
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
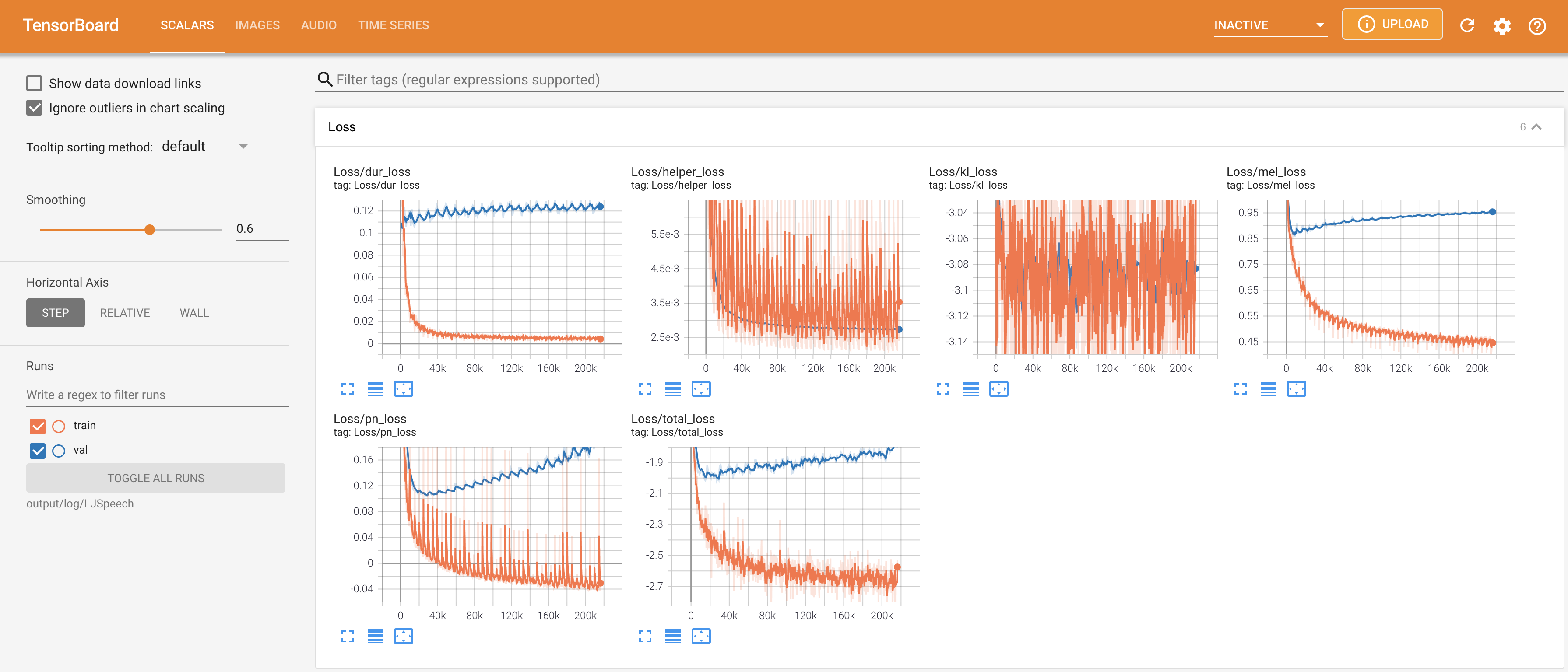
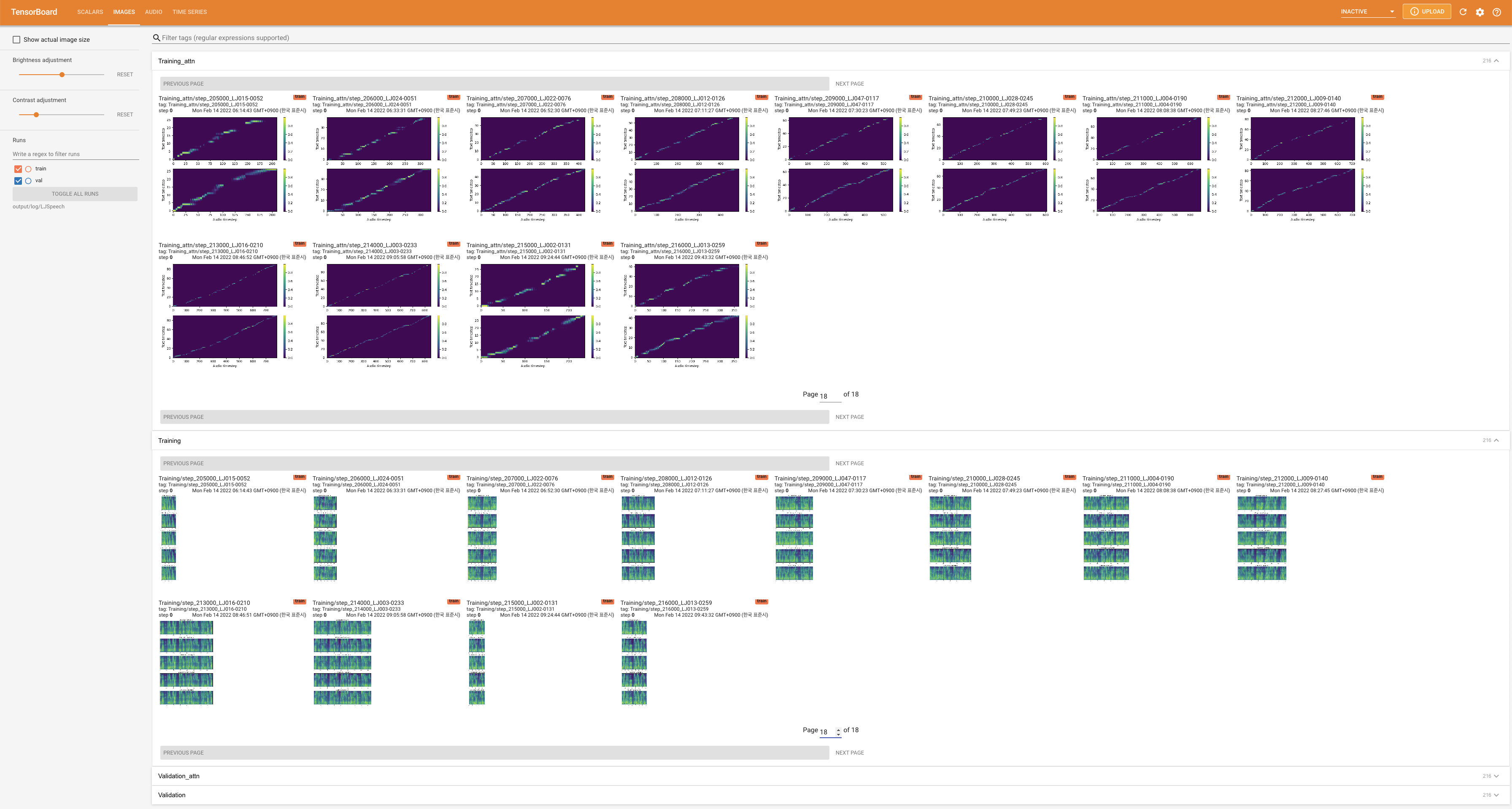
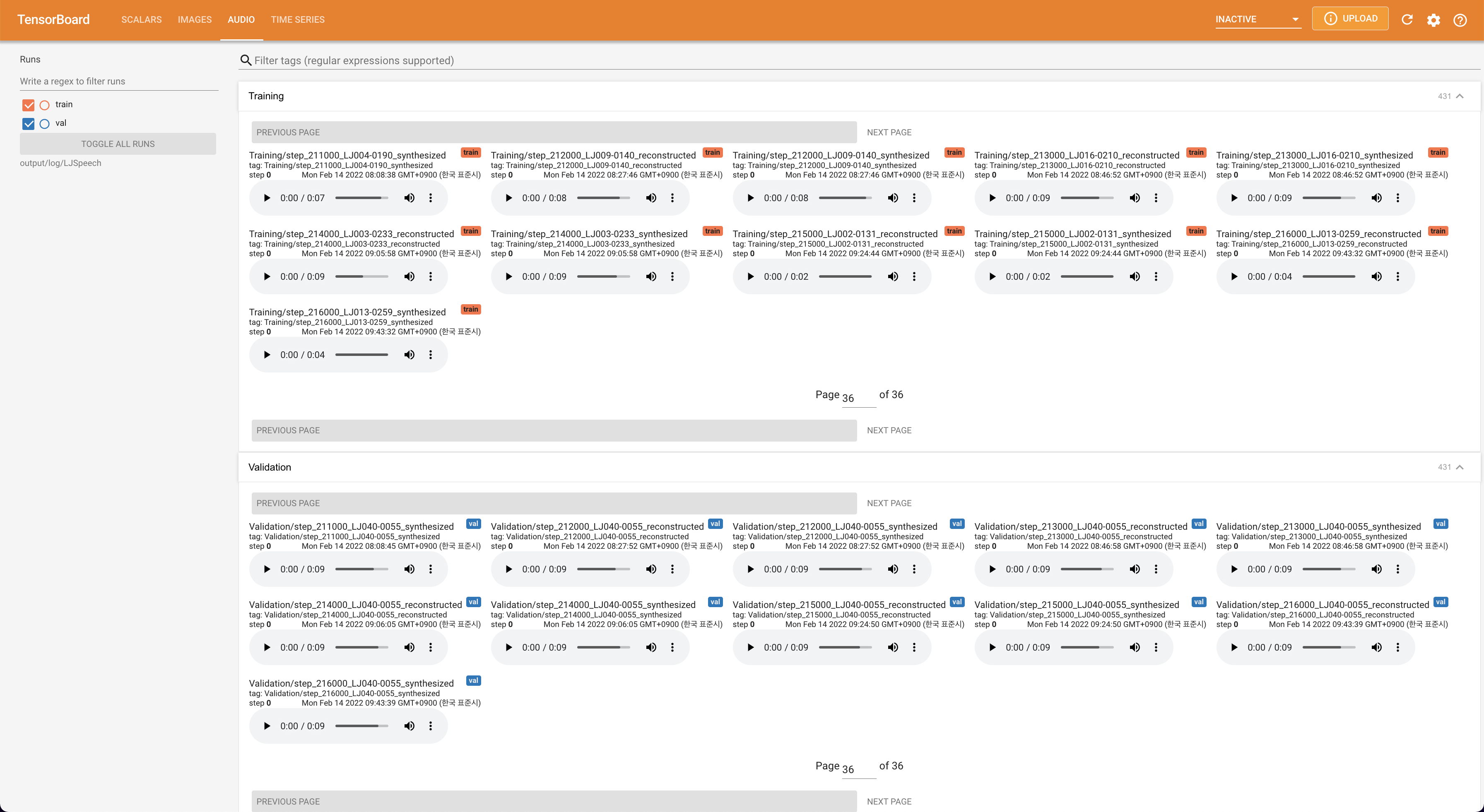
# In the train.yaml
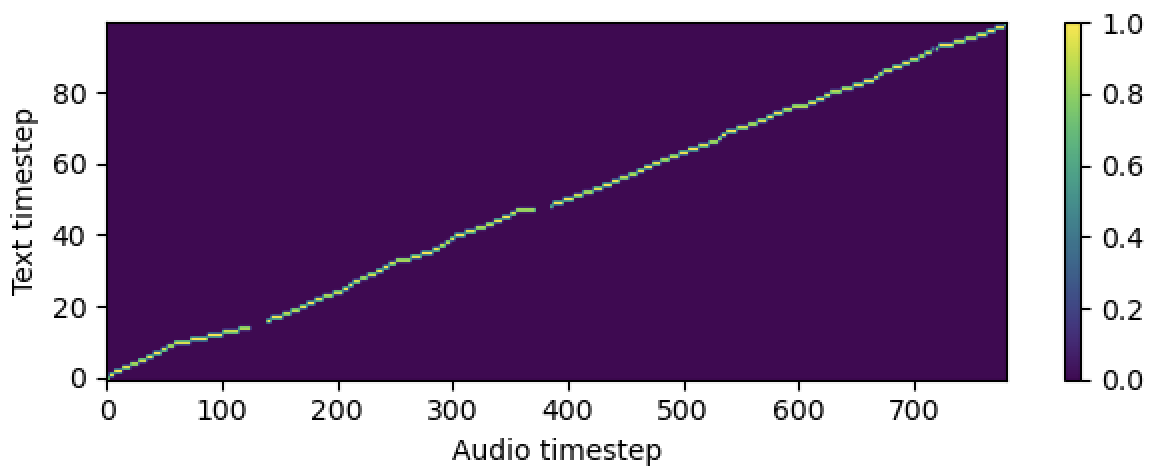
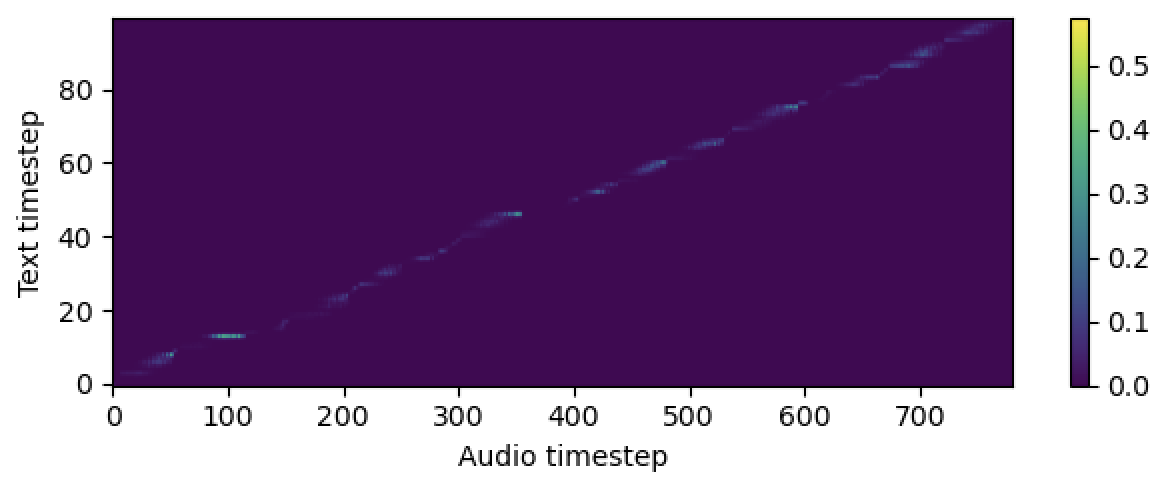
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]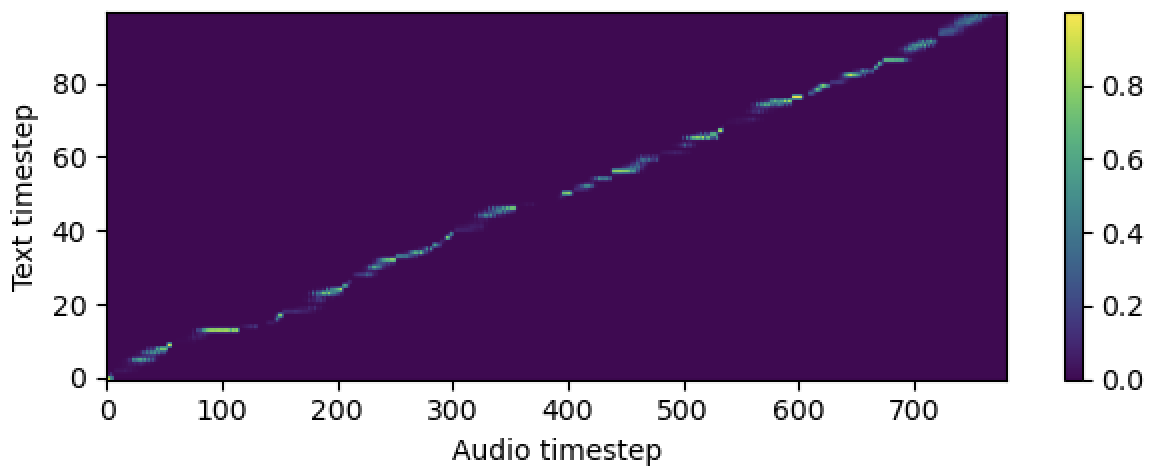
Cite este repositorio por el "cita este repositorio" de la sección Acerca de (arriba a la derecha de la página principal).


