PortaSpeech
v0.2.0
Pytorch-Implementierung von Portaspeech: tragbare und hochwertige generative Text-zu-Sprache.
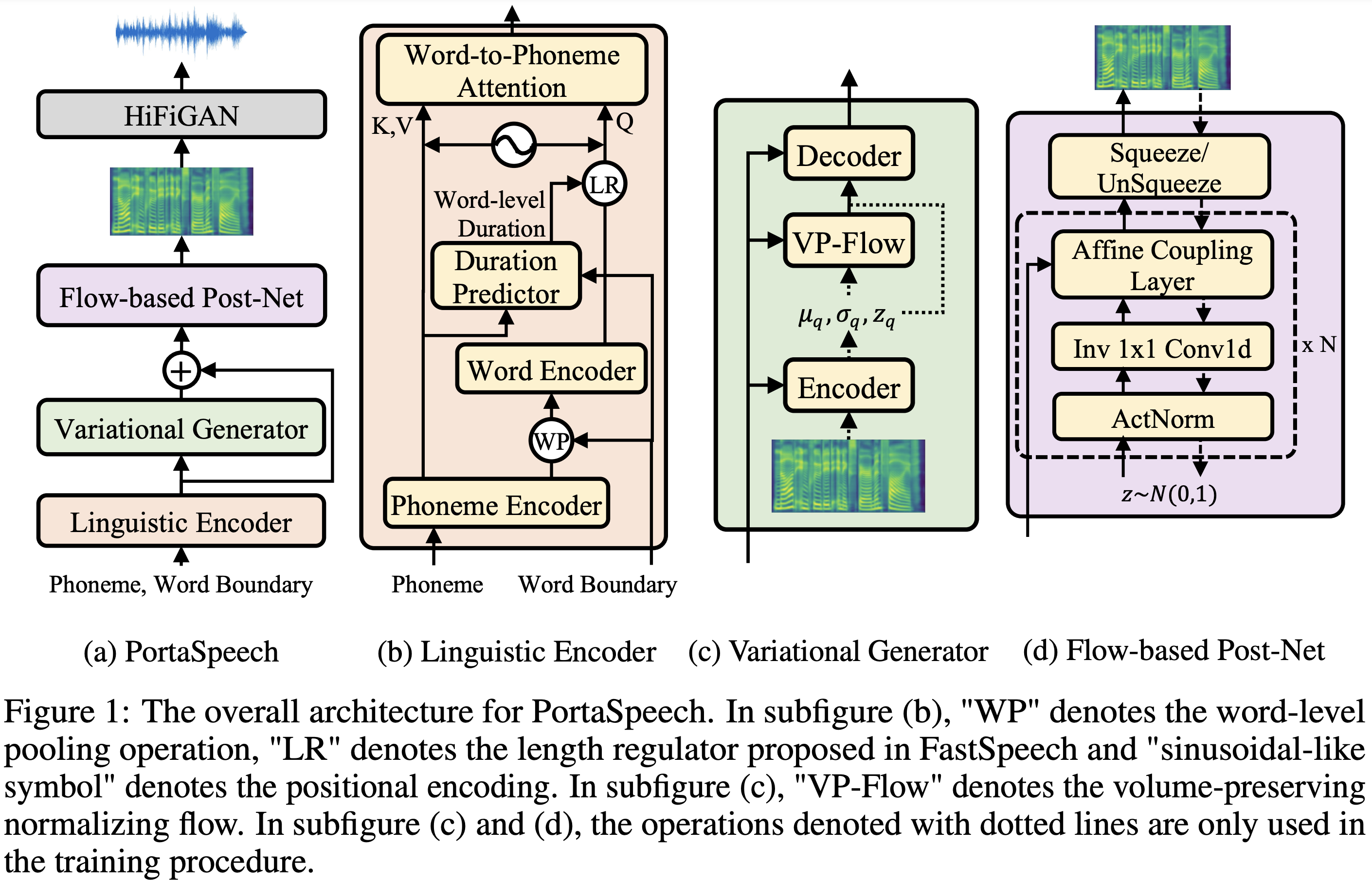
Audio -Samples sind bei /Demo erhältlich.
| Modul | Normal | Klein | Normal (Papier) | Klein (Papier) |
|---|---|---|---|---|
| Gesamt | 24m | 7,6 m | 21,8 m | 6,7 m |
| LinguisticCoder | 3,7 m | 1,4 m | - - | - - |
| Variationalgenerator | 11m | 2,8 m | - - | - - |
| FlowPostnet | 9,3 m | 3,4 m | - - | - - |
Datensatz bezieht sich auf die Namen von Datensätzen wie LJSpeech in den folgenden Dokumenten.
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Außerdem wird Dockerfile für Docker -Benutzer bereitgestellt.
Sie müssen die vorbereiteten Modelle herunterladen und in output/ckpt/DATASET/ einfügen.
Für einen TTS mit einem Lautsprecher laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Die erzeugten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
So synthetisieren Sie alle Äußerungen in preprocessed_data/DATASET/val.txt .
Die Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Dauerverhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 nach 20 erhöhen
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Bitte beachten Sie, dass die Steuerbarkeit aus Fastspeech2 und kein wesentliches Interesse an Portaspeech stammt.
Die unterstützten Datensätze sind
Laufen
python3 prepare_align.py --dataset DATASET
Für einige Vorbereitungen.
Für die erzwungene Ausrichtung wird Montreal erzwungene Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Vorextrahierte Ausrichtungen für die Datensätze werden hier bereitgestellt. Sie müssen die Dateien in preprocessed_data/DATASET/TextGrid/ entpacken. Alternativ können Sie den Aligner selbst ausführen.
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py --dataset DATASET
Trainieren Sie Ihr Modell mit
python3 train.py --dataset DATASET
Nützliche Optionen:
--use_amp Argument zum obigen Befehl.CUDA_VISIBLE_DEVICES=<GPU_IDs> an.Verwenden
tensorboard --logdir output/log
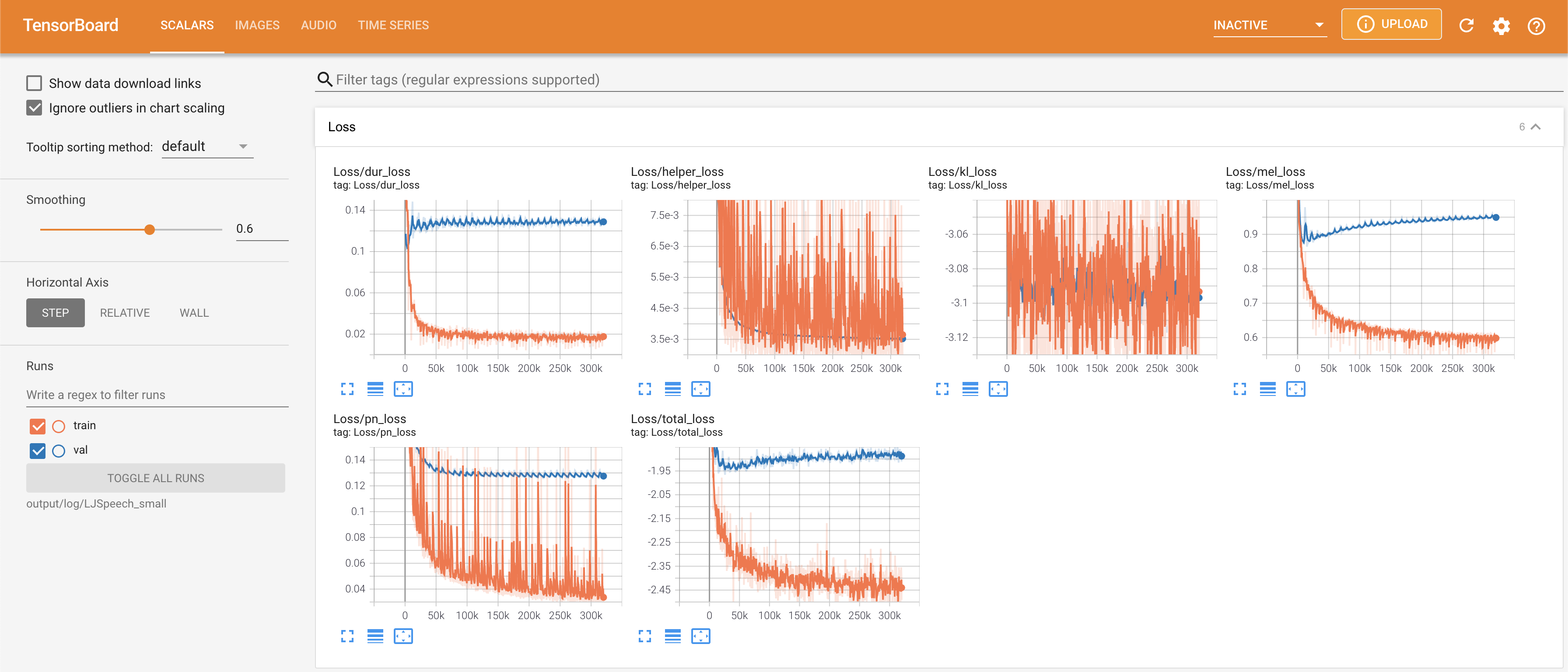
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
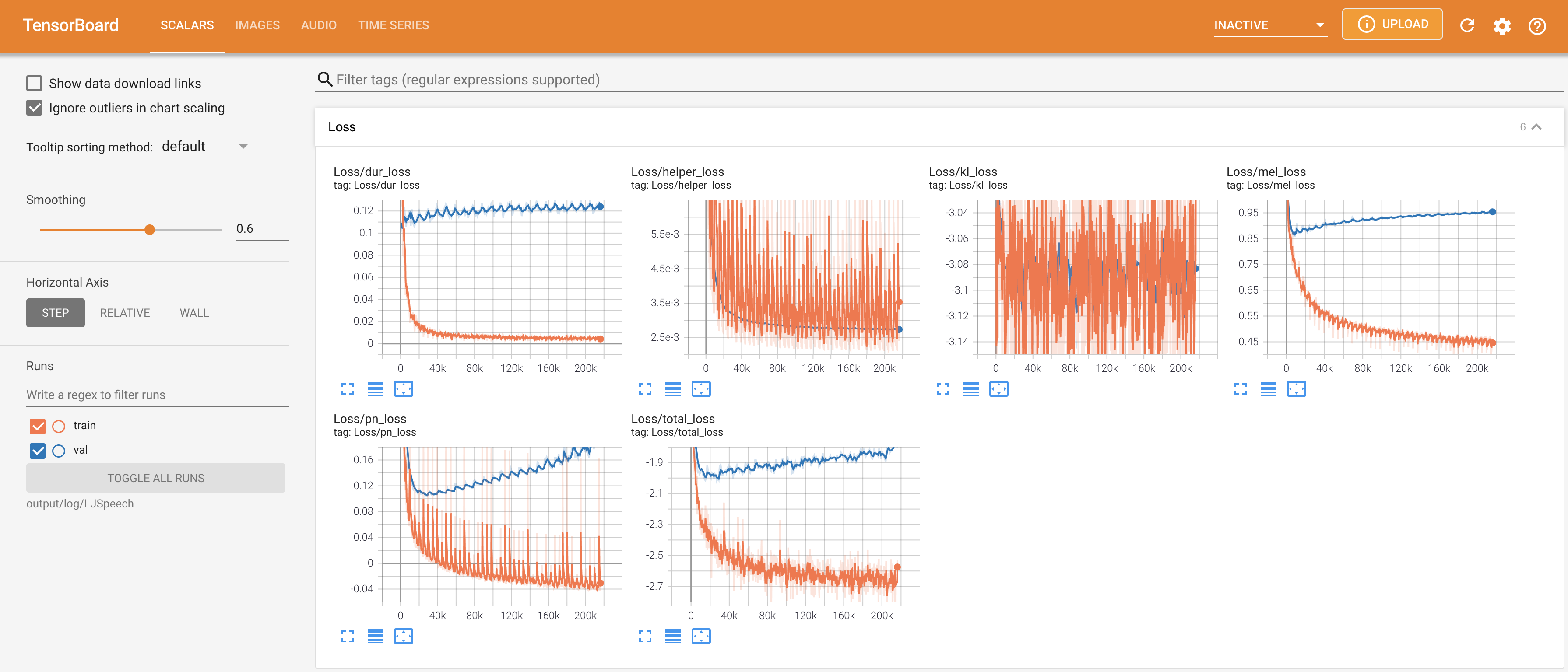
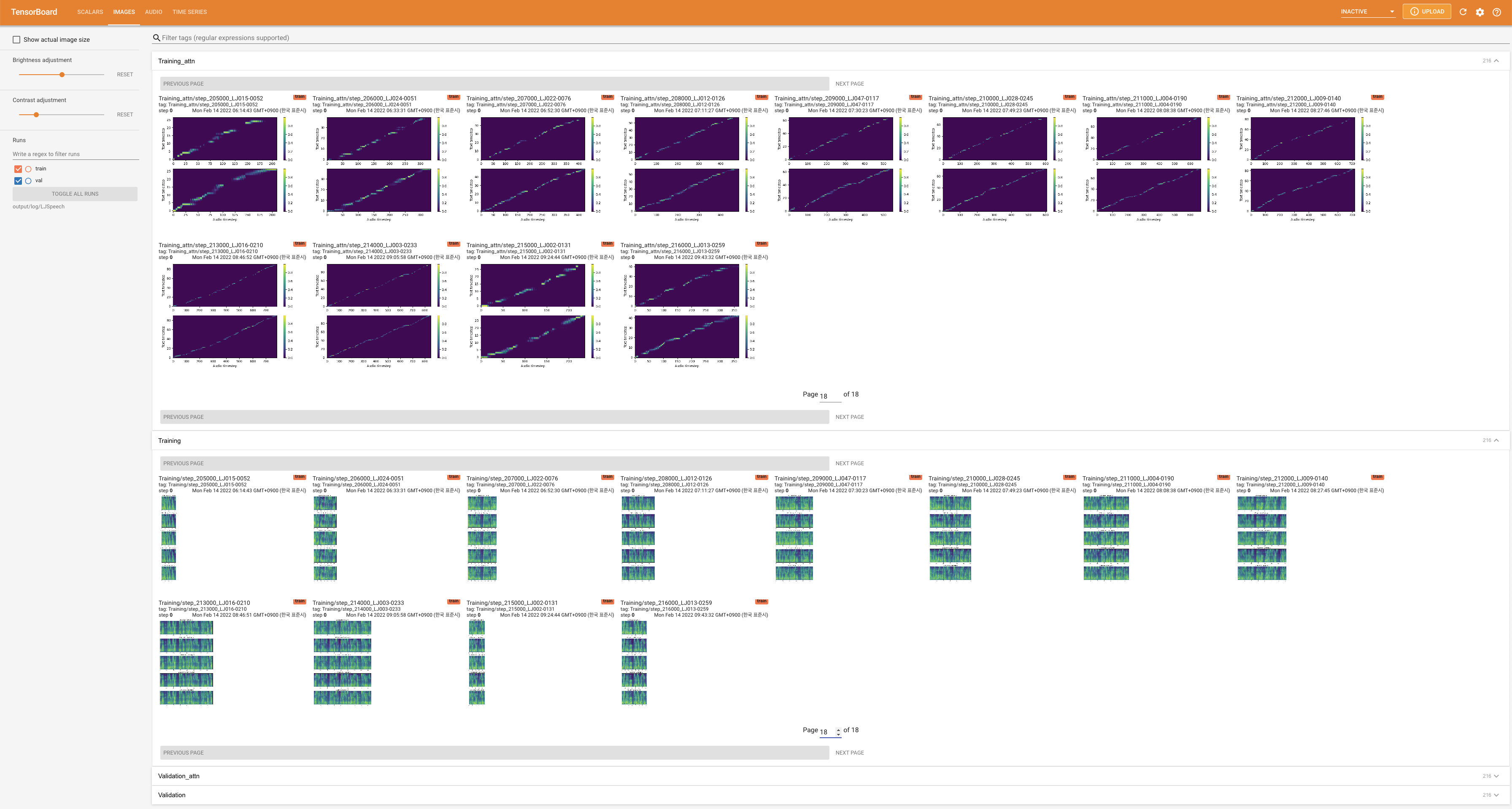
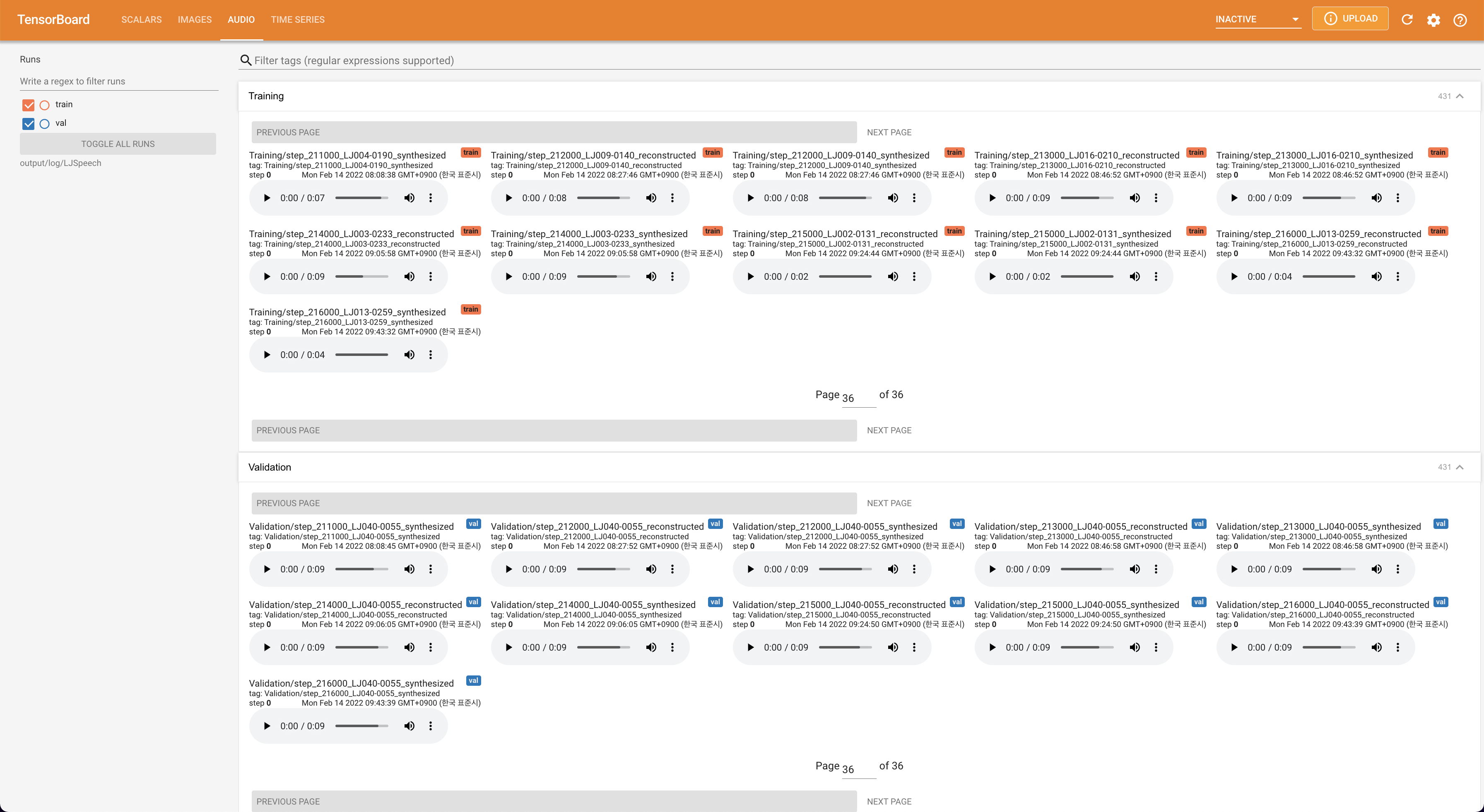
# In the train.yaml
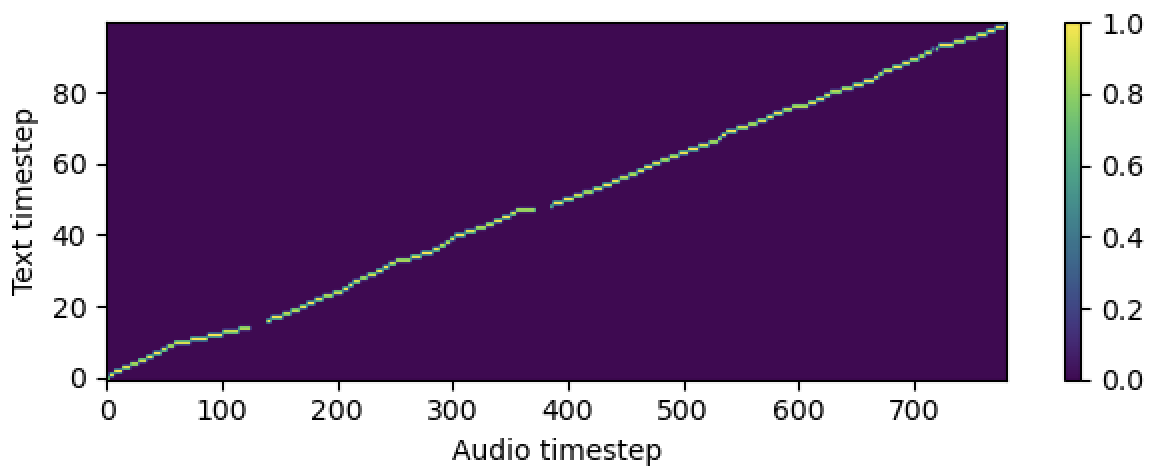
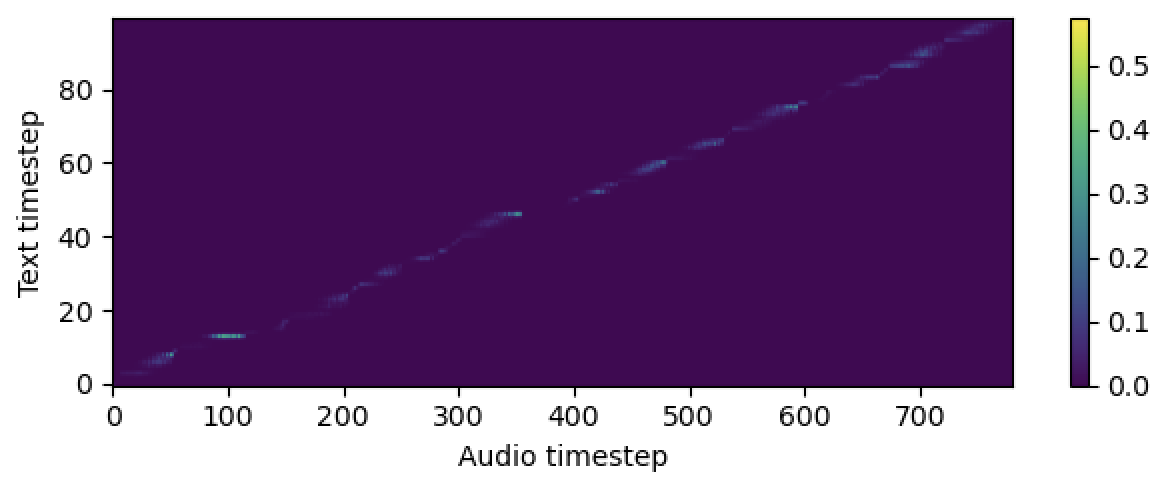
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]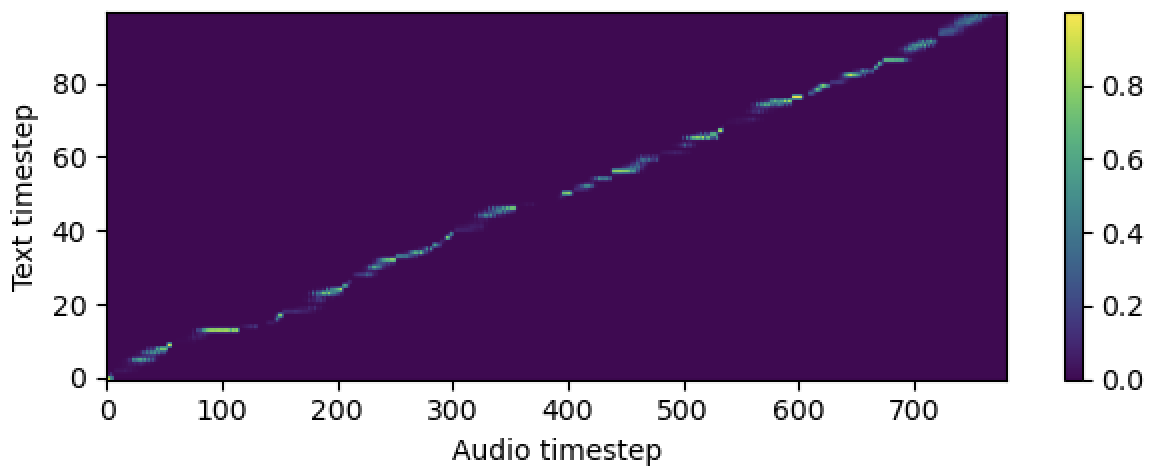
Bitte zitieren Sie dieses Repository durch das "Zitieren Sie dieses Repository" des Abschnitts (oben rechts auf der Hauptseite).


