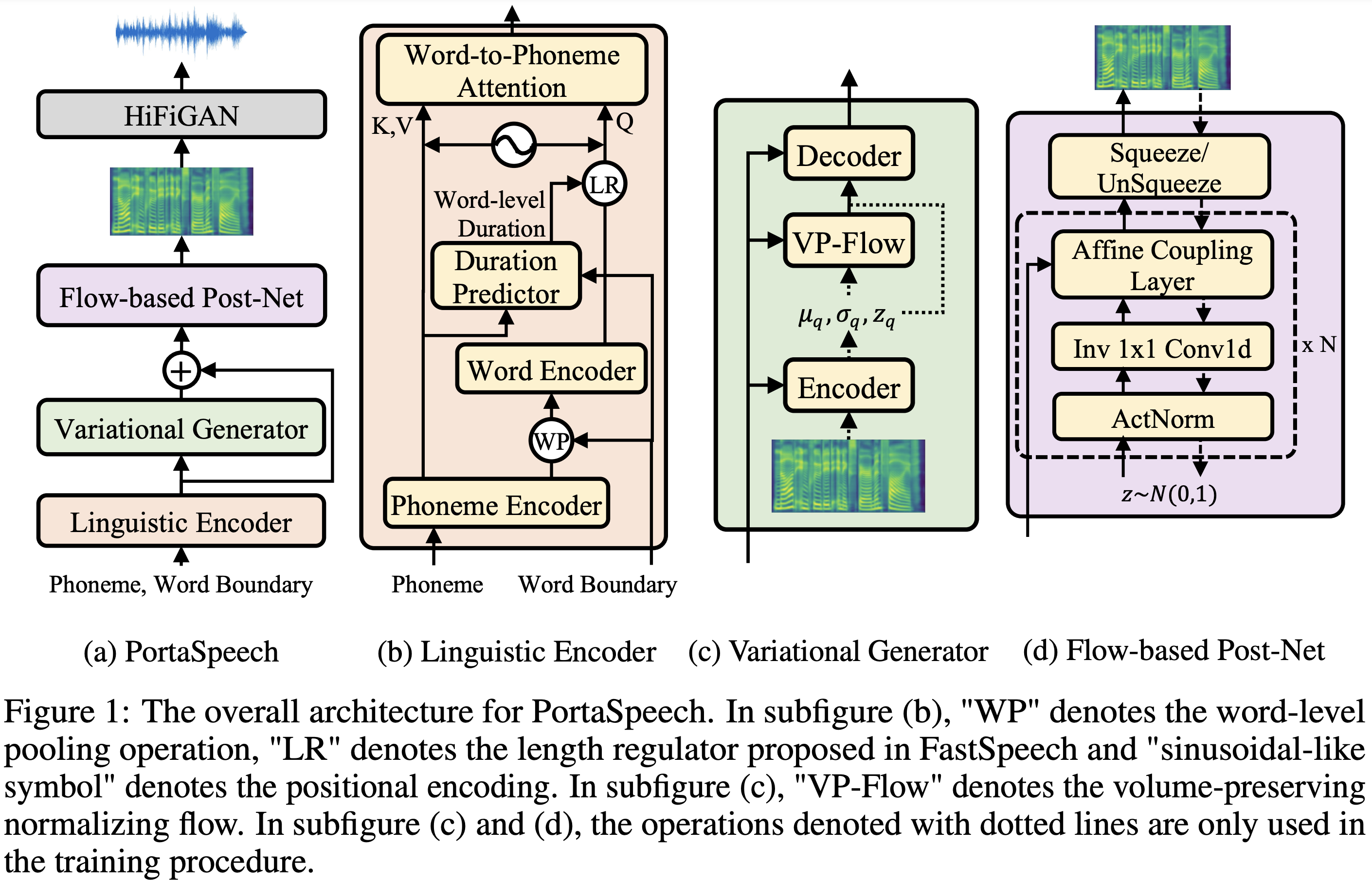
PortaSpeech
v0.2.0
PortaspeechのPytorch実装:ポータブルで高品質の生成テキストからスピーチ。
オーディオサンプルは /デモで利用できます。
| モジュール | 普通 | 小さい | 通常(紙) | 小(紙) |
|---|---|---|---|---|
| 合計 | 24m | 7.6m | 21.8m | 6.7m |
| 言語エンコーダー | 3.7m | 1.4m | - | - |
| VariationGenerator | 11m | 2.8m | - | - |
| FlowPostNet | 9.3m | 3.4m | - | - |
データセットとは、次のドキュメントでLJSpeechなどのデータセットの名前を指します。
Python依存関係をインストールできます
pip3 install -r requirements.txt
また、 DockerfileはDockerユーザーに提供されています。
事前に保護されたモデルをダウンロードして、それらをoutput/ckpt/DATASET/に配置する必要があります。
単一スピーカーのTTSの場合、実行します
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
生成された発話はoutput/result/に配置されます。
バッチ推論もサポートされています
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
preprocessed_data/DATASET/val.txtのすべての発話を合成します。
合成された発話の発話レートは、目的の持続時間比を指定することで制御できます。たとえば、発話レートを20で増やすことができます
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
制御可能性はfastspeech2に由来し、Partaspeechの重要な関心ではないことに注意してください。
サポートされているデータセットは次のとおりです
走る
python3 prepare_align.py --dataset DATASET
いくつかの準備のために。
強制アライメントのために、モントリオールの強制アライナー(MFA)を使用して、発話と音素シーケンスの間のアライメントを取得します。データセットの事前に抽出されたアライメントはここに記載されています。 preprocessed_data/DATASET/TextGrid/でファイルを解凍する必要があります。または、自分でアライナーを実行できます。
その後、前処理スクリプトを実行します
python3 preprocess.py --dataset DATASET
モデルを訓練します
python3 train.py --dataset DATASET
有用なオプション:
--use_amp引数を追加します。CUDA_VISIBLE_DEVICES=<GPU_IDs>を指定します。使用
tensorboard --logdir output/log
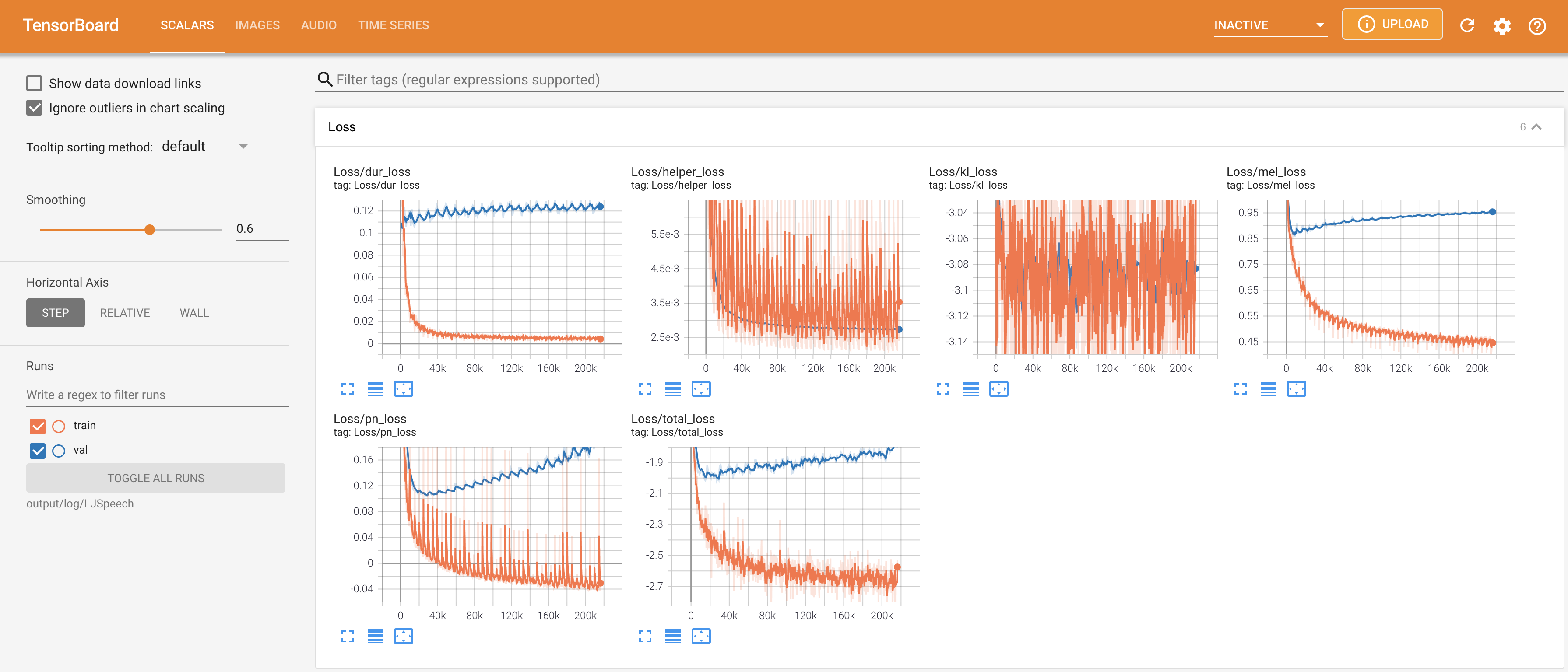
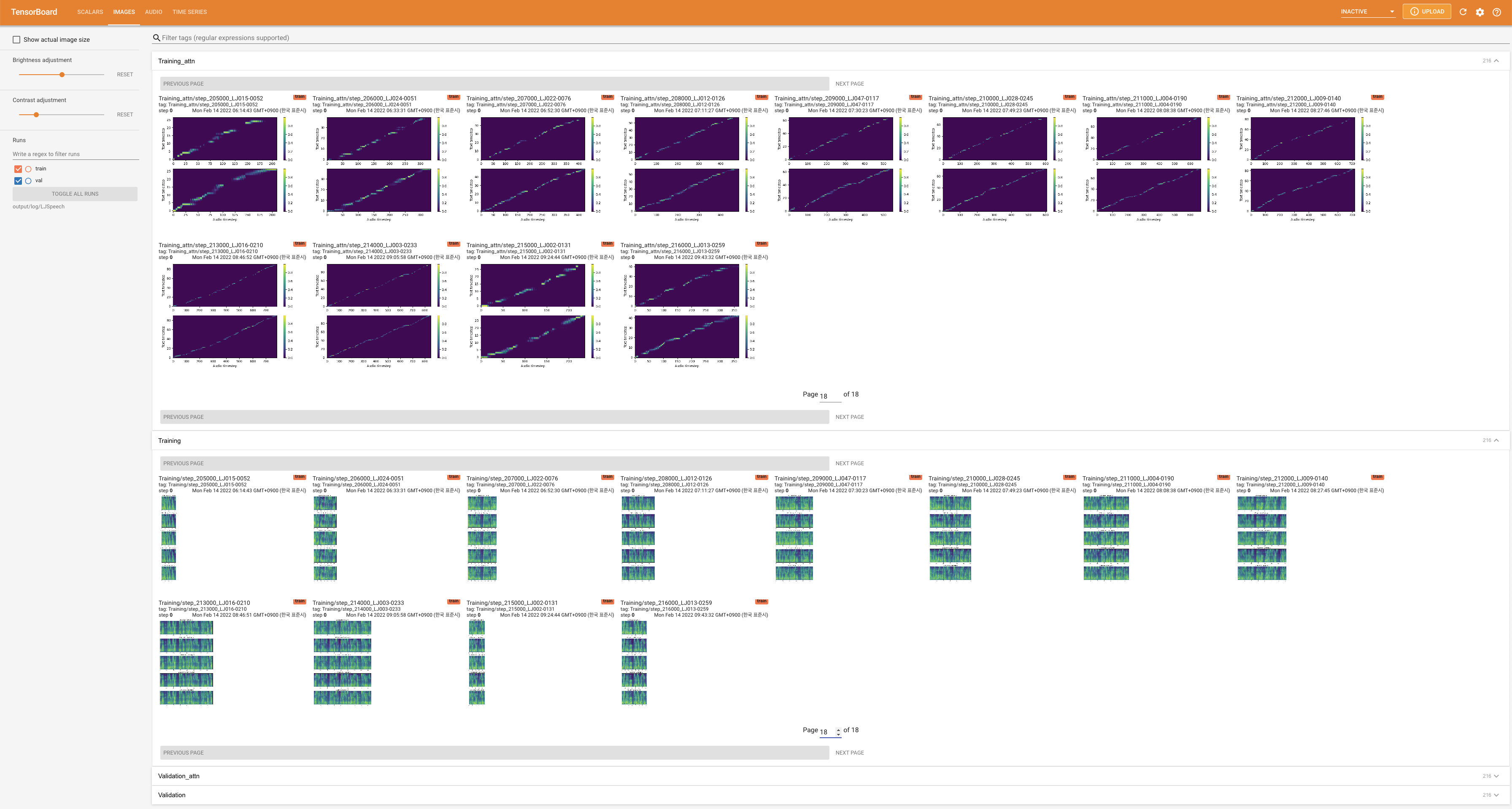
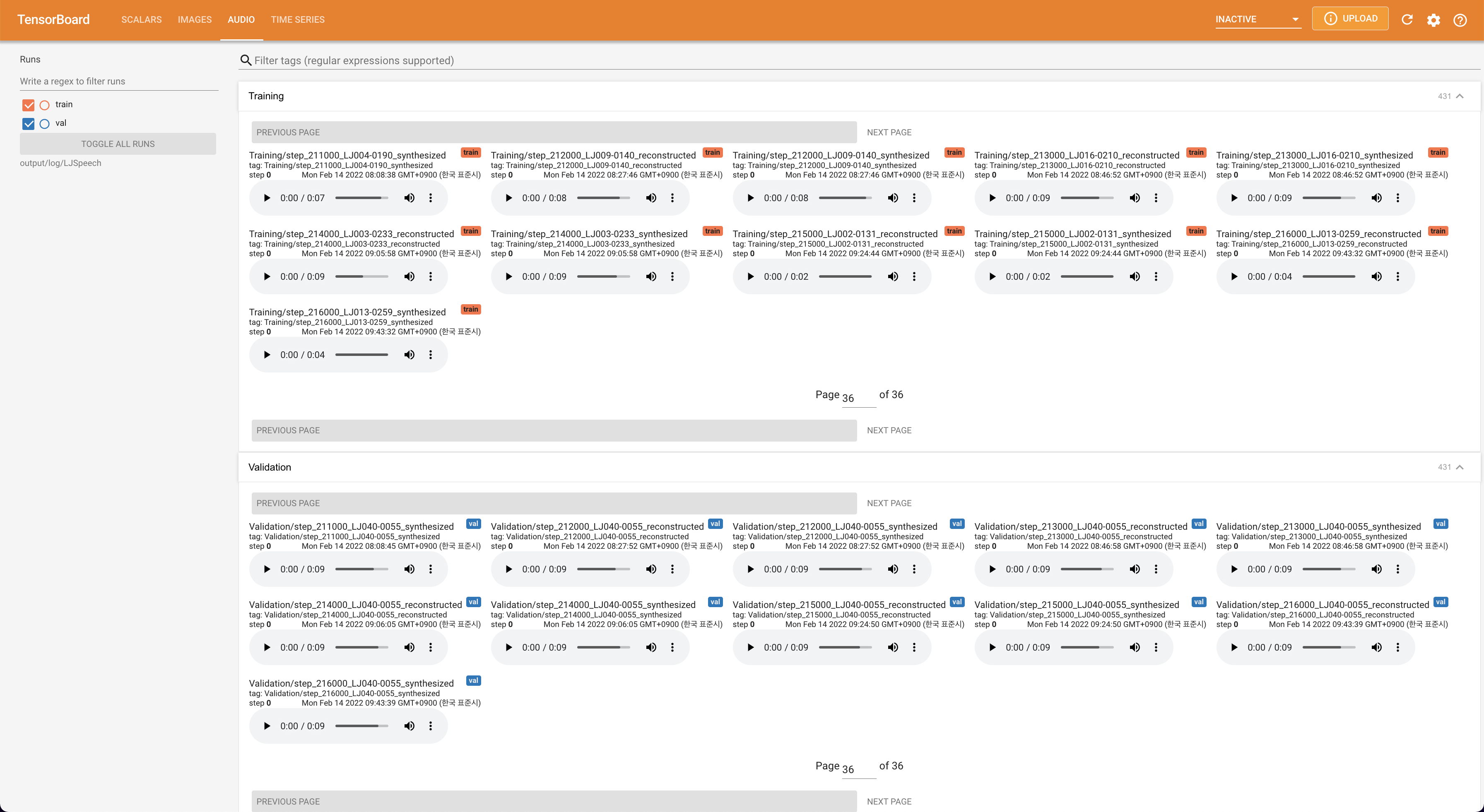
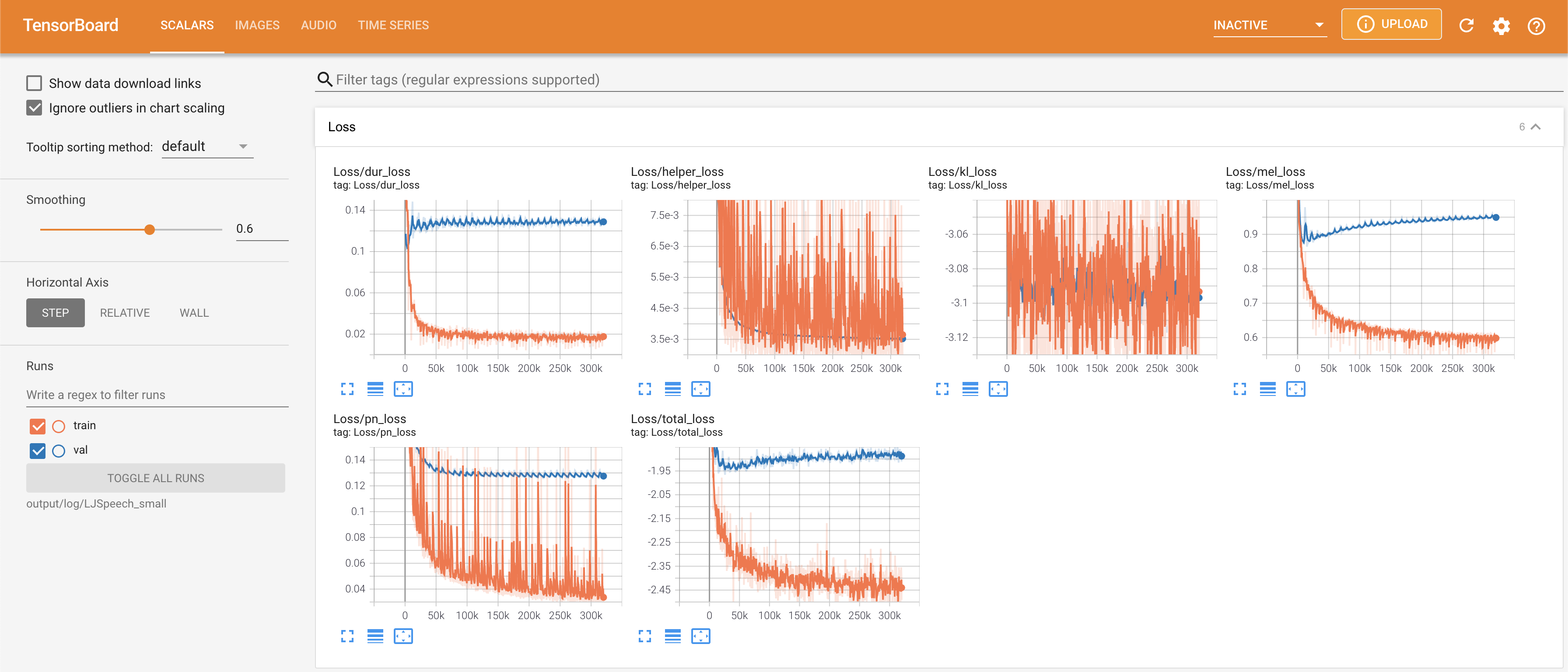
LocalHostでTensorboardを提供します。損失曲線、合成されたメルスペクトルグラム、およびオーディオが表示されます。
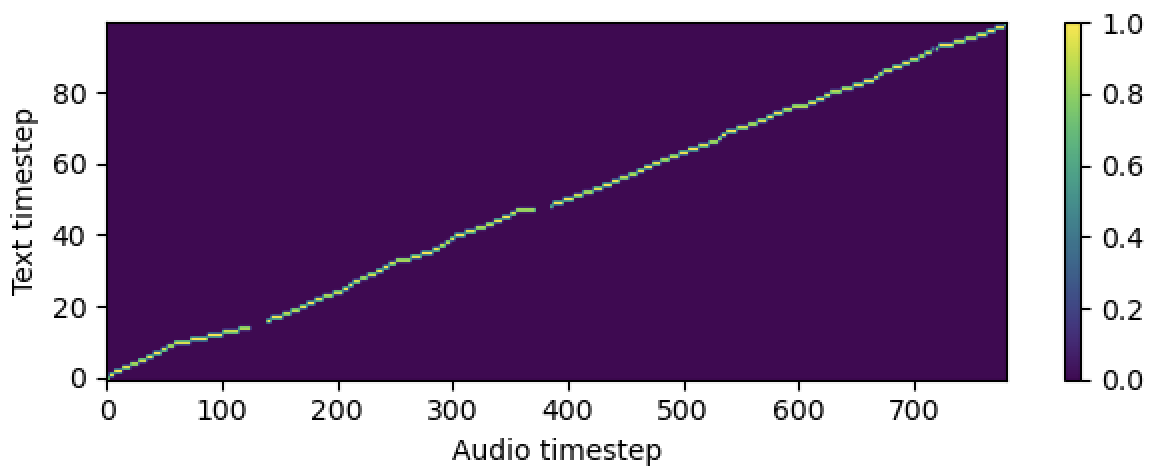
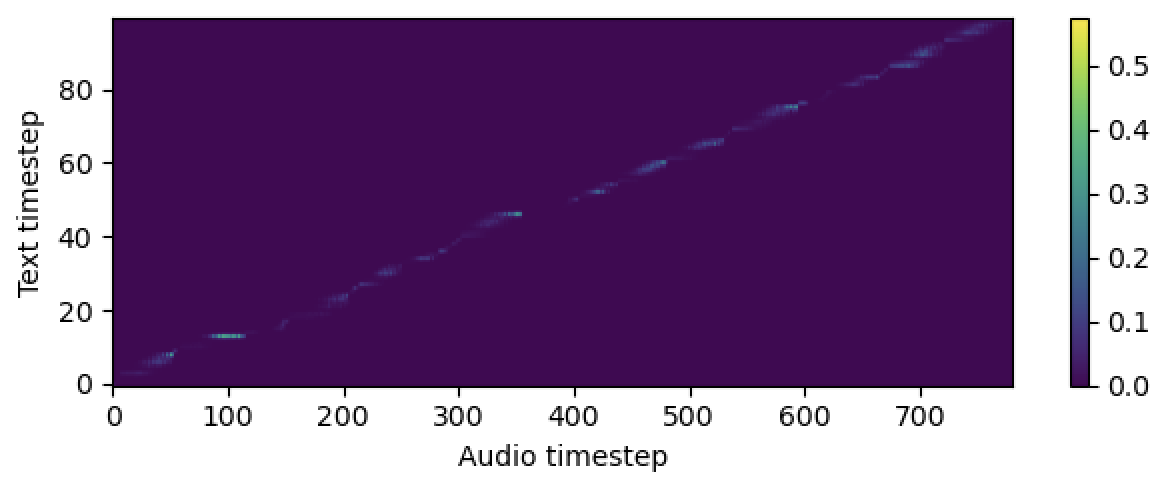
# In the train.yaml
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]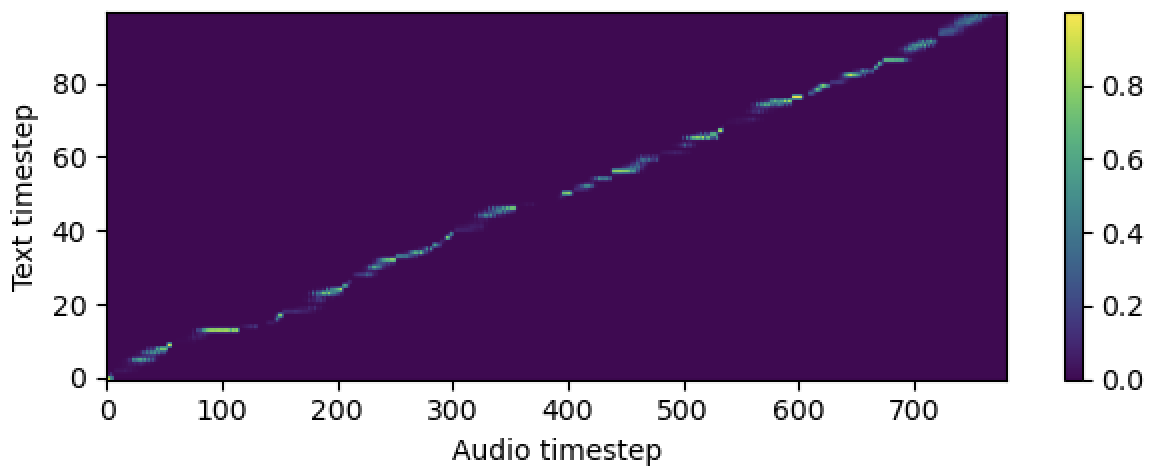
このリポジトリは、セクションについての「このリポジトリを引用」して引用してください(メインページの右上)。


