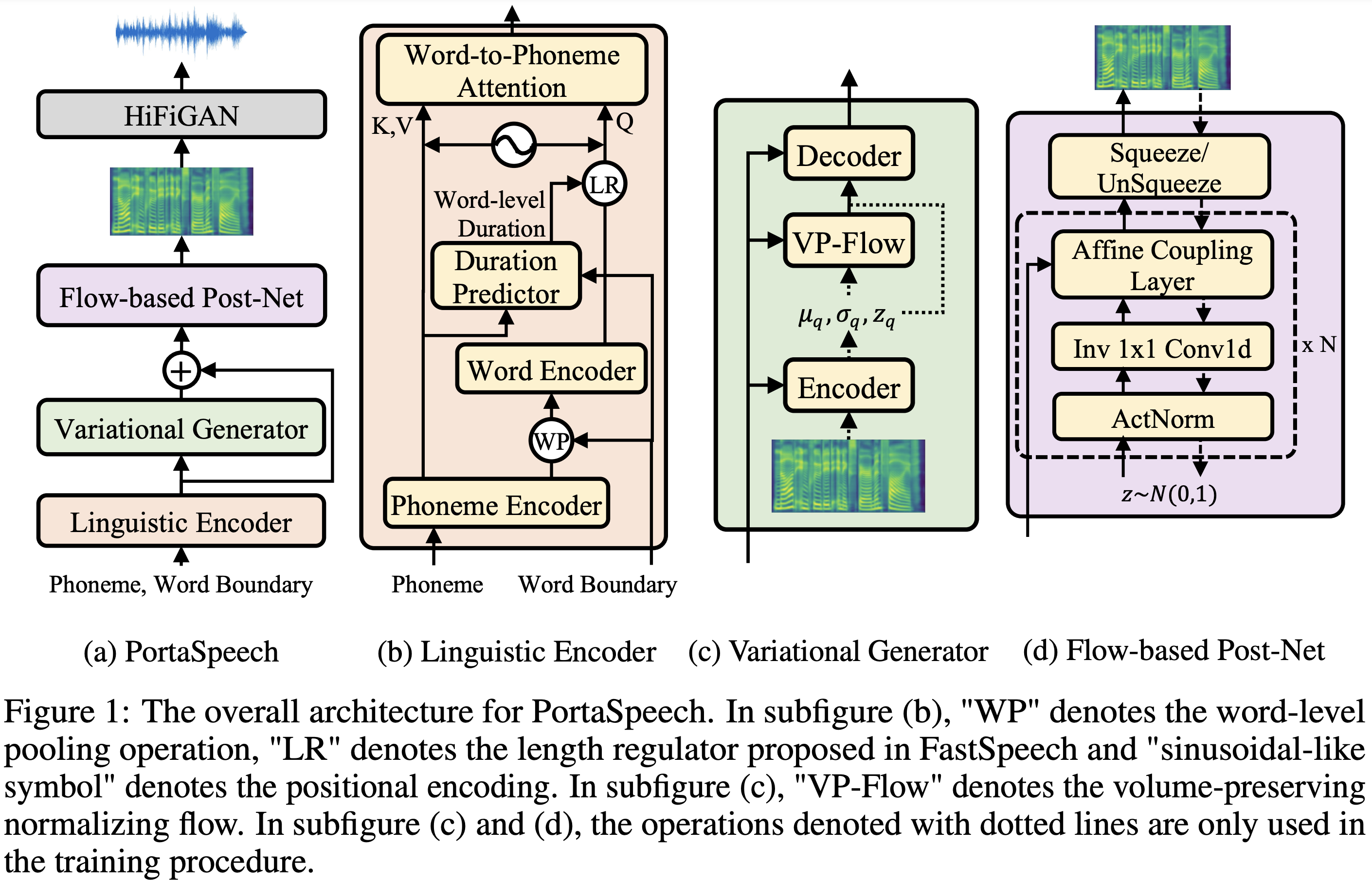
PortaSpeech
v0.2.0
การใช้งาน Pytorch ของ Portaspeech: ข้อความแบบพกพาและคุณภาพสูง
ตัวอย่างเสียงมีให้ที่ /สาธิต
| โมดูล | ปกติ | เล็ก | ปกติ (กระดาษ) | เล็ก (กระดาษ) |
|---|---|---|---|---|
| ทั้งหมด | 24 เมตร | 7.6m | 21.8m | 6.7m |
| ภาษาศาสตร์ | 3.7m | 1.4m | - | - |
| ตัวแปร | 11m | 2.8m | - | - |
| flowpostnet | 9.3m | 3.4m | - | - |
ชุดข้อมูล หมายถึงชื่อของชุดข้อมูลเช่น LJSpeech ในเอกสารต่อไปนี้
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
นอกจากนี้ Dockerfile ยังมีไว้สำหรับผู้ใช้ Docker
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและวางไว้ใน output/ckpt/DATASET/
สำหรับ TTS ลำโพงเดียว Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
คำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/DATASET/val.txt
อัตราการพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
โปรดทราบว่าความสามารถในการควบคุมนั้นมีต้นกำเนิดมาจาก FastSpeech2 และไม่ใช่ความสนใจที่สำคัญของ portaspeech
ชุดข้อมูลที่รองรับคือ
วิ่ง
python3 prepare_align.py --dataset DATASET
สำหรับการเตรียมการบางอย่าง
สำหรับการจัดตำแหน่งที่ถูกบังคับมอนทรีออลบังคับให้ผู้จัดตำแหน่ง (MFA) ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งที่สกัดไว้ล่วงหน้าสำหรับชุดข้อมูลมีให้ที่นี่ คุณต้องคลายซิปไฟล์ใน preprocessed_data/DATASET/TextGrid/ อีกวิธีหนึ่งคุณสามารถเรียกใช้การจัดตำแหน่งด้วยตัวเอง
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py --dataset DATASET
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py --dataset DATASET
ตัวเลือกที่มีประโยชน์:
--use_amp อาร์กิวเมนต์ไปยังคำสั่งด้านบนCUDA_VISIBLE_DEVICES=<GPU_IDs> ที่จุดเริ่มต้นของคำสั่งด้านบนใช้
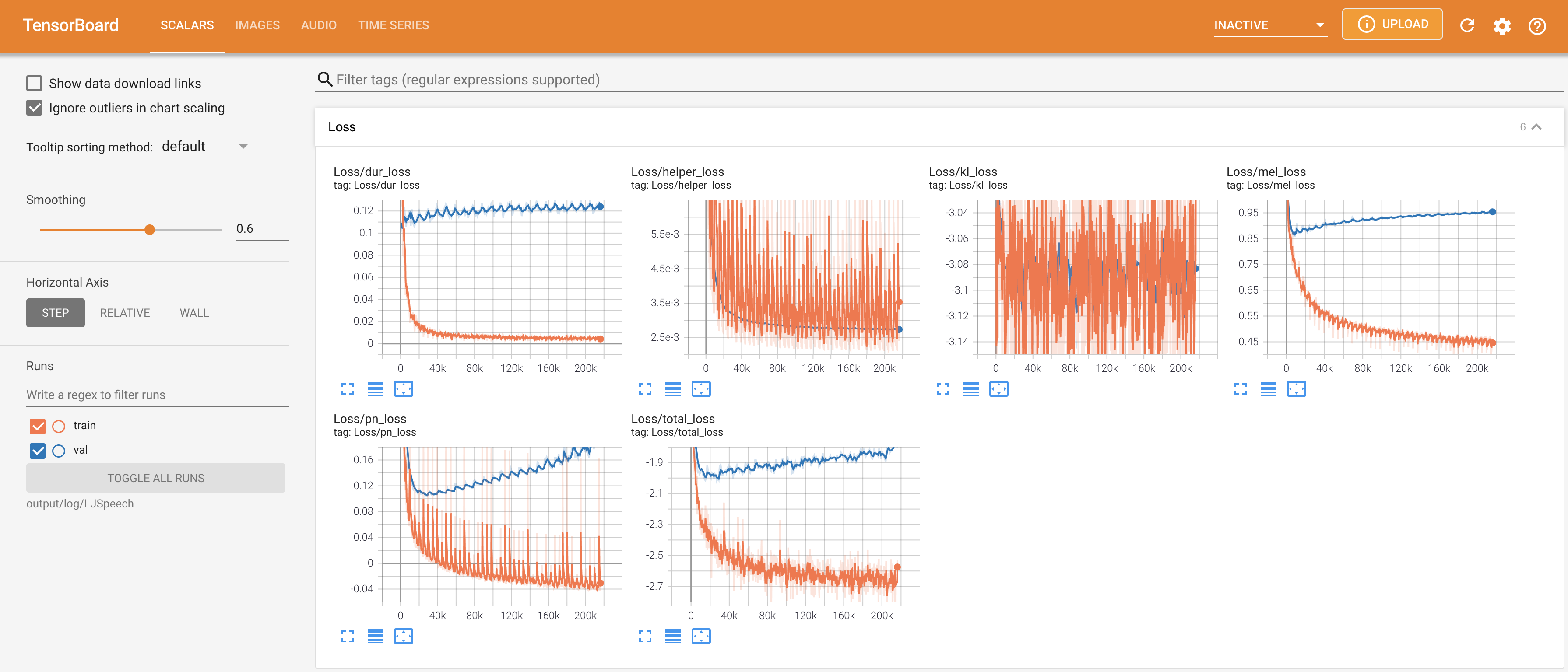
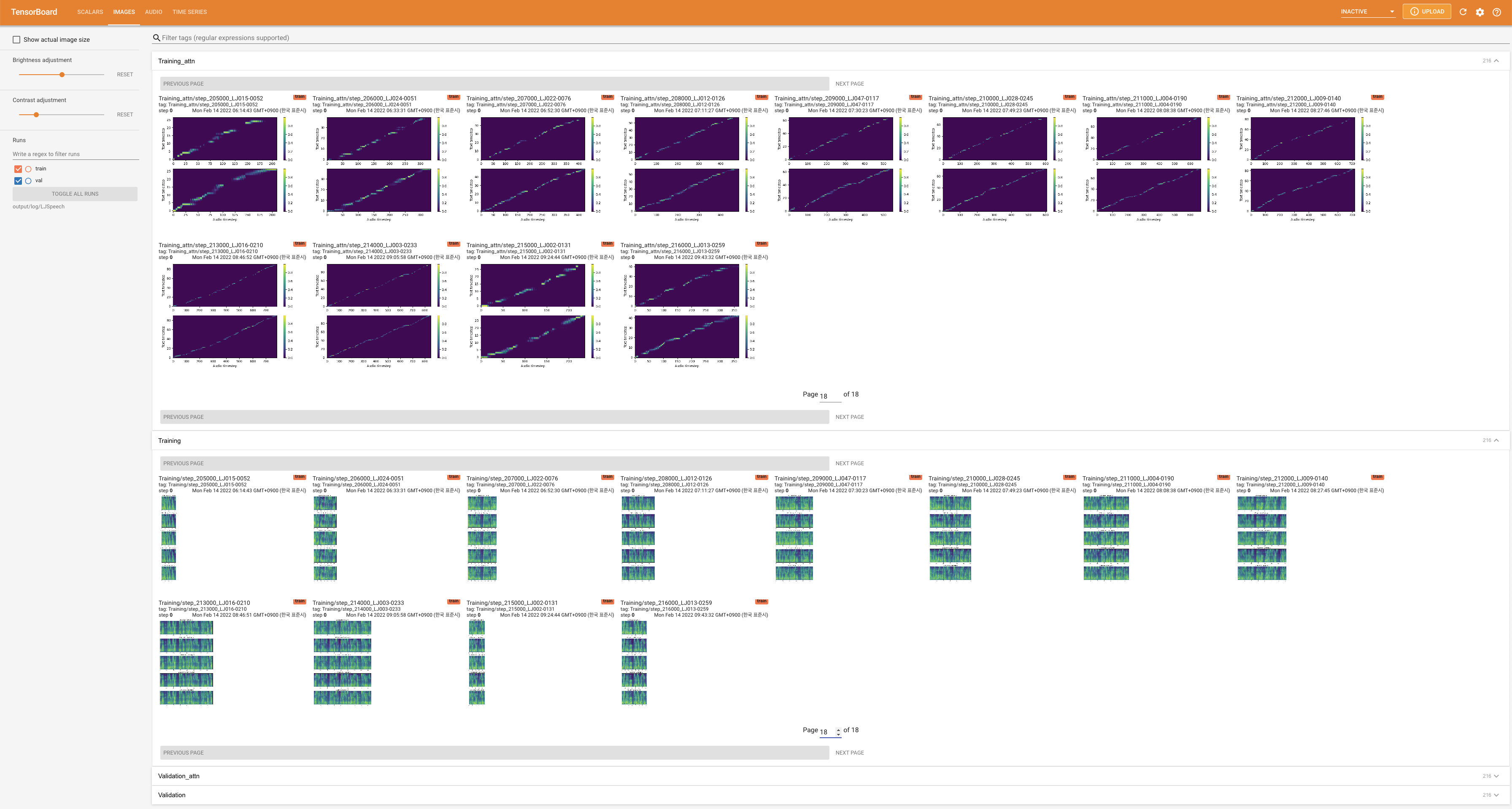
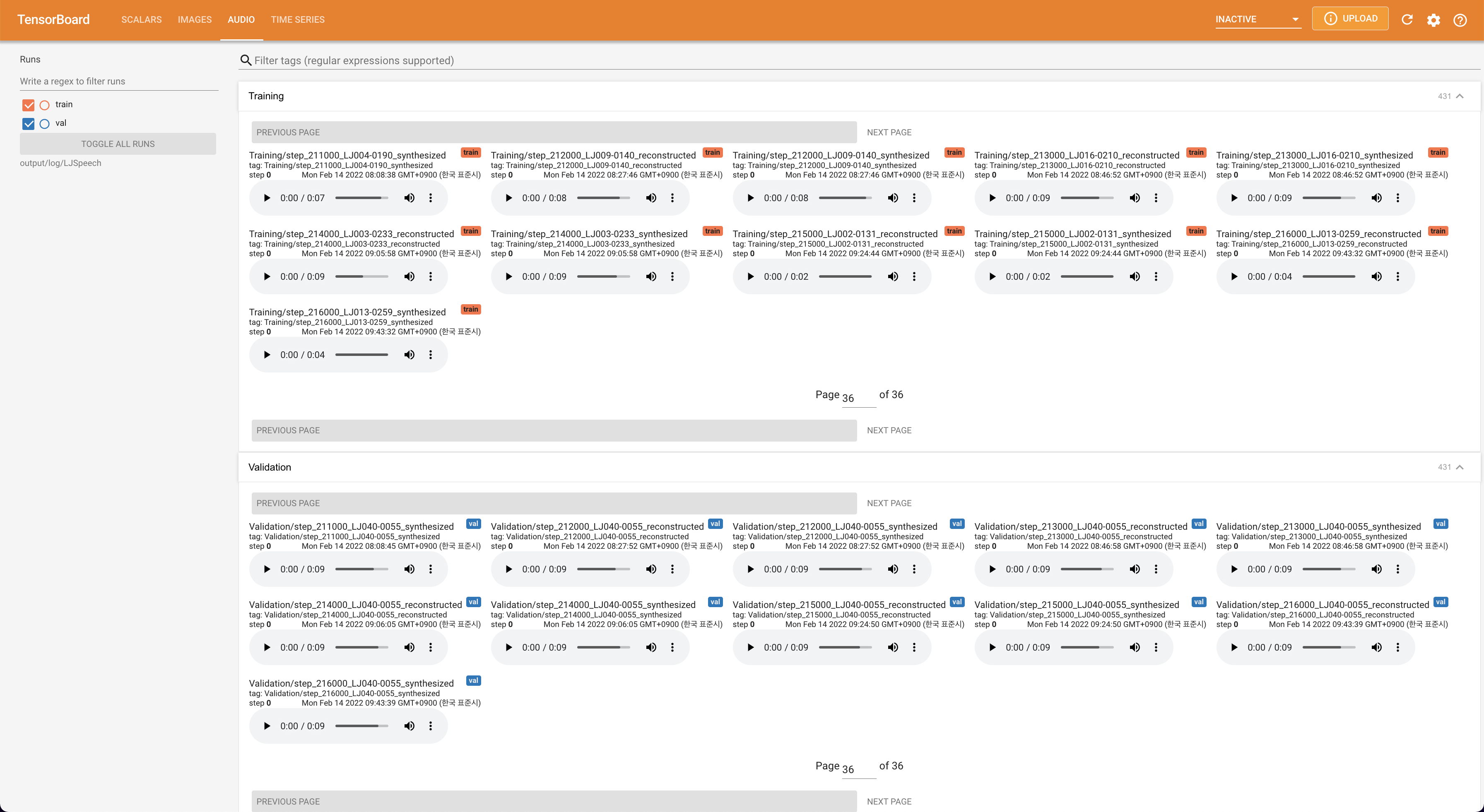
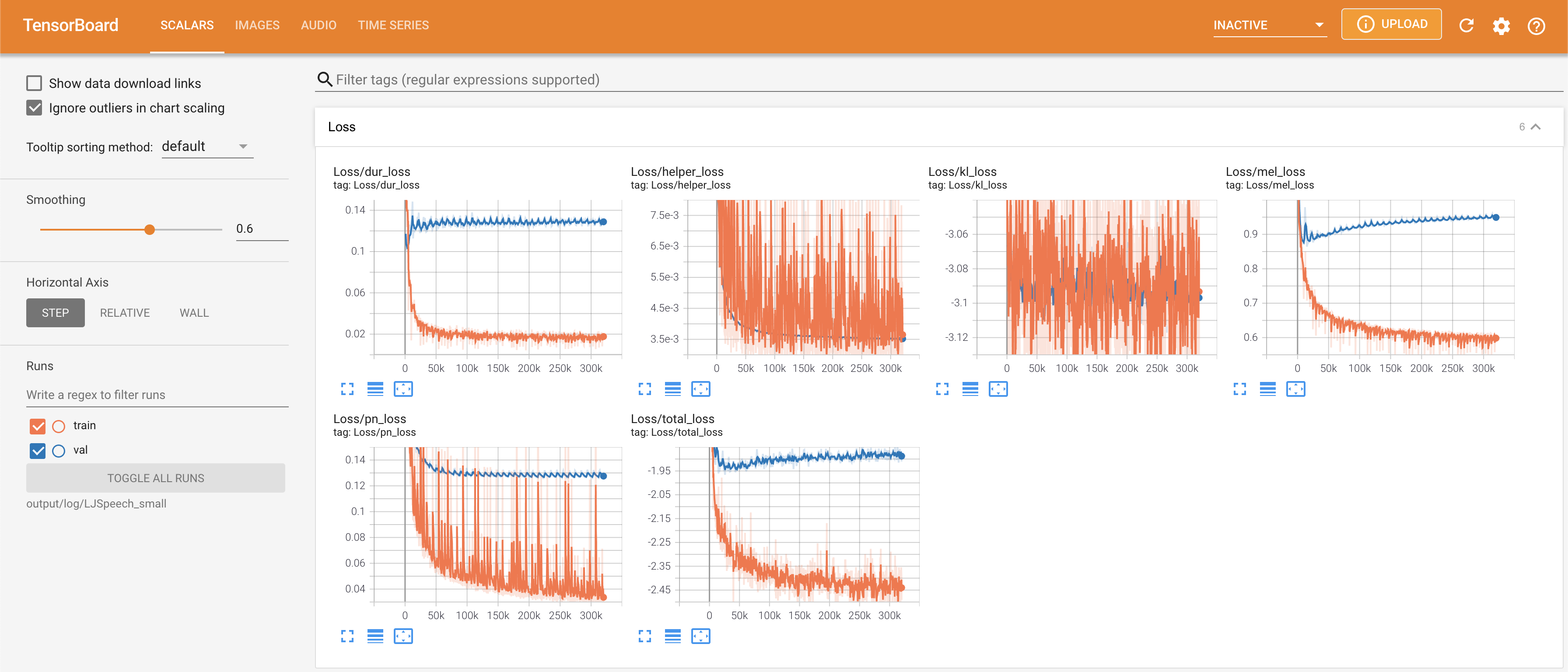
tensorboard --logdir output/log
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
# In the train.yaml
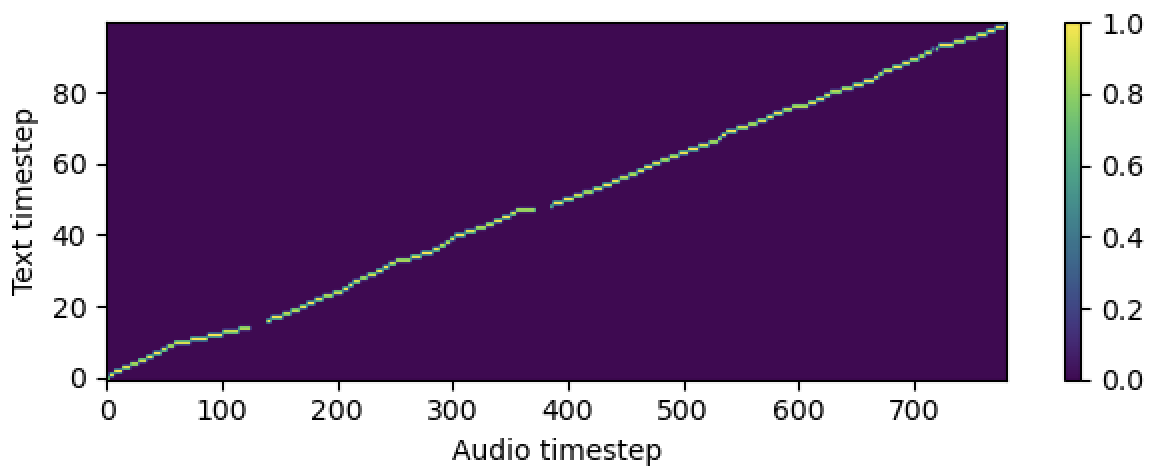
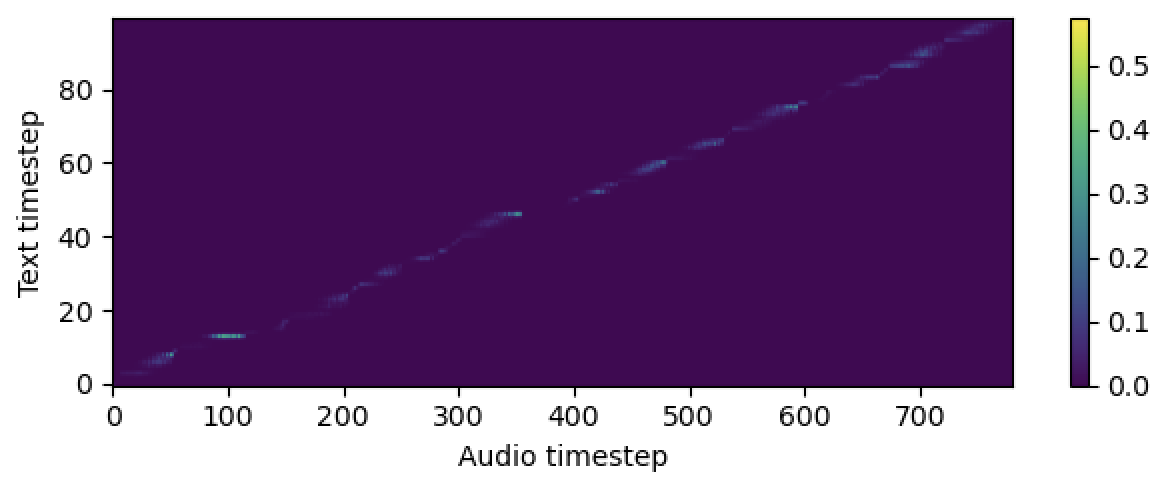
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]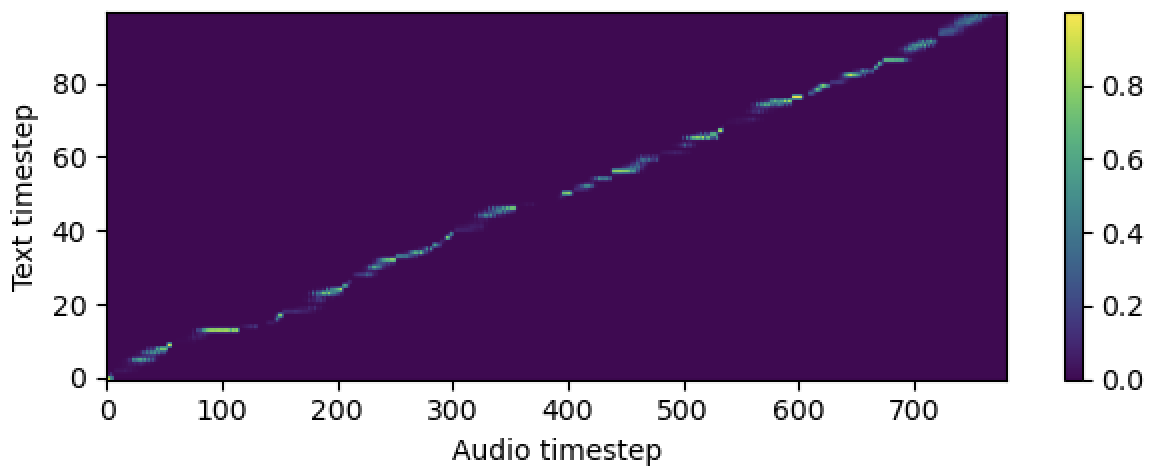
โปรดอ้างอิงพื้นที่เก็บข้อมูลนี้โดย "อ้างอิงที่เก็บนี้" ของส่วน เกี่ยวกับ (ขวาบนของหน้าหลัก)


