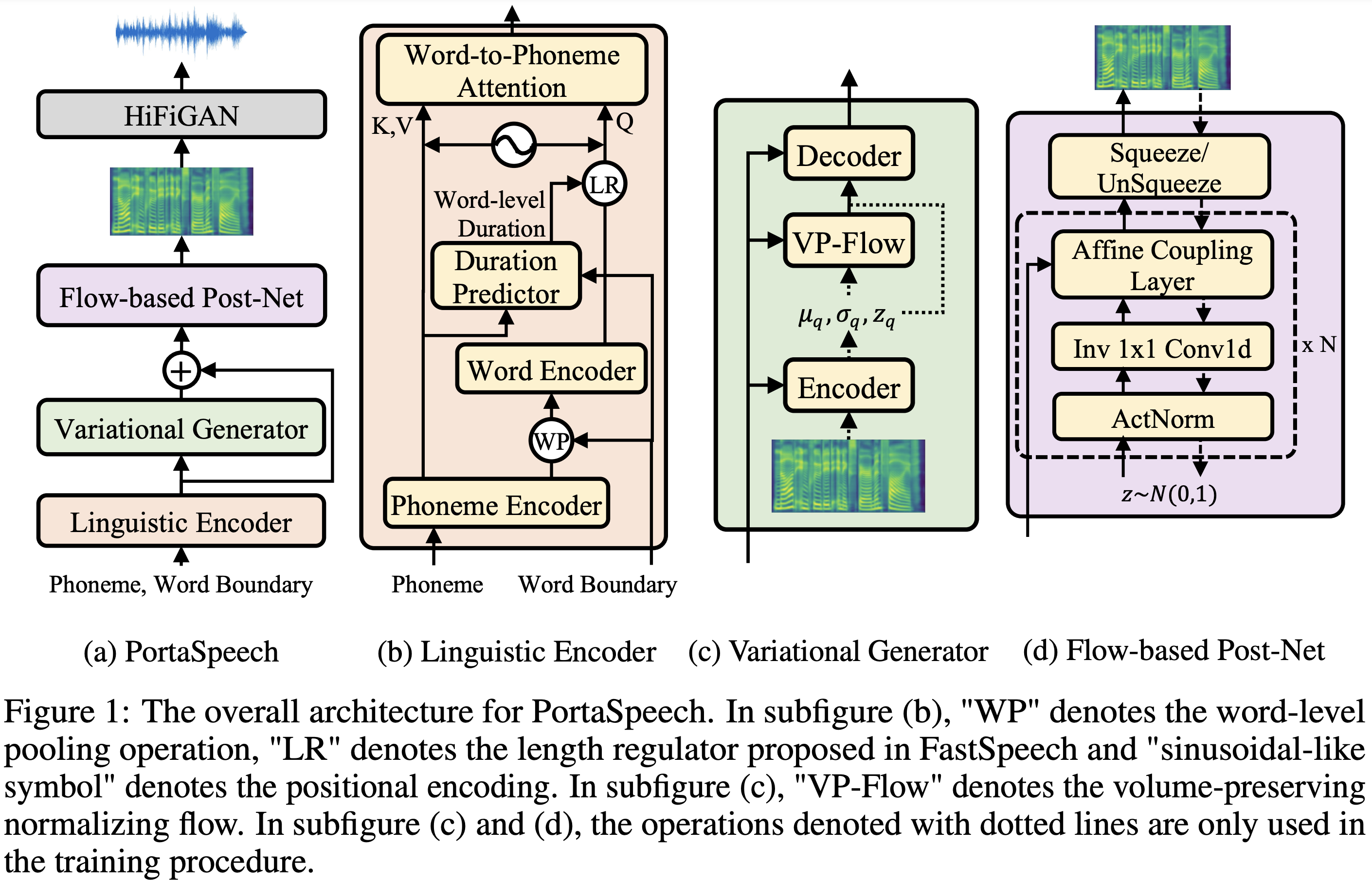
PortaSpeech
v0.2.0
Implementação de Pytorch da PortasPasech: Texto-para-fala portátil e de alta qualidade.
Amostras de áudio estão disponíveis em /demonstração.
| Módulo | Normal | Pequeno | Normal (papel) | Pequeno (papel) |
|---|---|---|---|---|
| Total | 24m | 7.6m | 21,8m | 6.7m |
| LinguisticEncoder | 3,7m | 1.4m | - | - |
| VariationalGenerator | 11m | 2,8m | - | - |
| FlowPostNet | 9,3m | 3,4m | - | - |
O conjunto de dados refere -se aos nomes de conjuntos de dados como LJSpeech nos documentos a seguir.
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Além disso, Dockerfile é fornecido para usuários Docker .
Você precisa baixar os modelos pré -tenhados e colocá -los em output/ckpt/DATASET/ .
Para um tts de alto-falante , execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todos os enunciados em preprocessed_data/DATASET/val.txt .
A taxa de fala dos enunciados sintetizados pode ser controlada especificando as taxas de duração desejadas. Por exemplo, pode -se aumentar a taxa de fala em 20 em
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Observe que a controlabilidade é originada no FastSpeech2 e não é um interesse vital do PortasPasech.
Os conjuntos de dados suportados são
Correr
python3 prepare_align.py --dataset DATASET
para alguns preparativos.
Para o alinhamento forçado, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Alinhamentos pré-extraídos para os conjuntos de dados são fornecidos aqui. Você precisa descompactar os arquivos em preprocessed_data/DATASET/TextGrid/ . Como alternativa, você pode executar o alinhador sozinho.
Depois disso, execute o script de pré -processamento por
python3 preprocess.py --dataset DATASET
Treine seu modelo com
python3 train.py --dataset DATASET
Opções úteis:
--use_amp do comando acima.CUDA_VISIBLE_DEVICES=<GPU_IDs> no início do comando acima.Usar
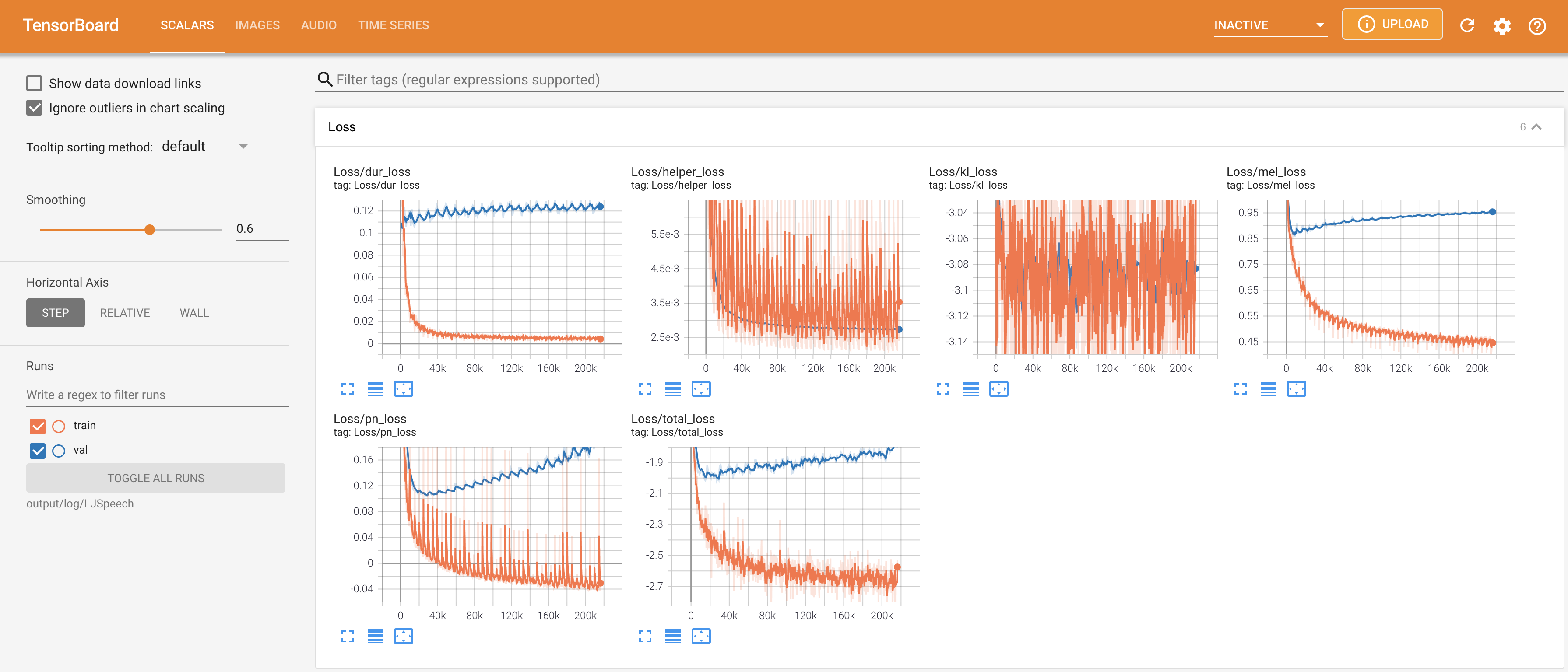
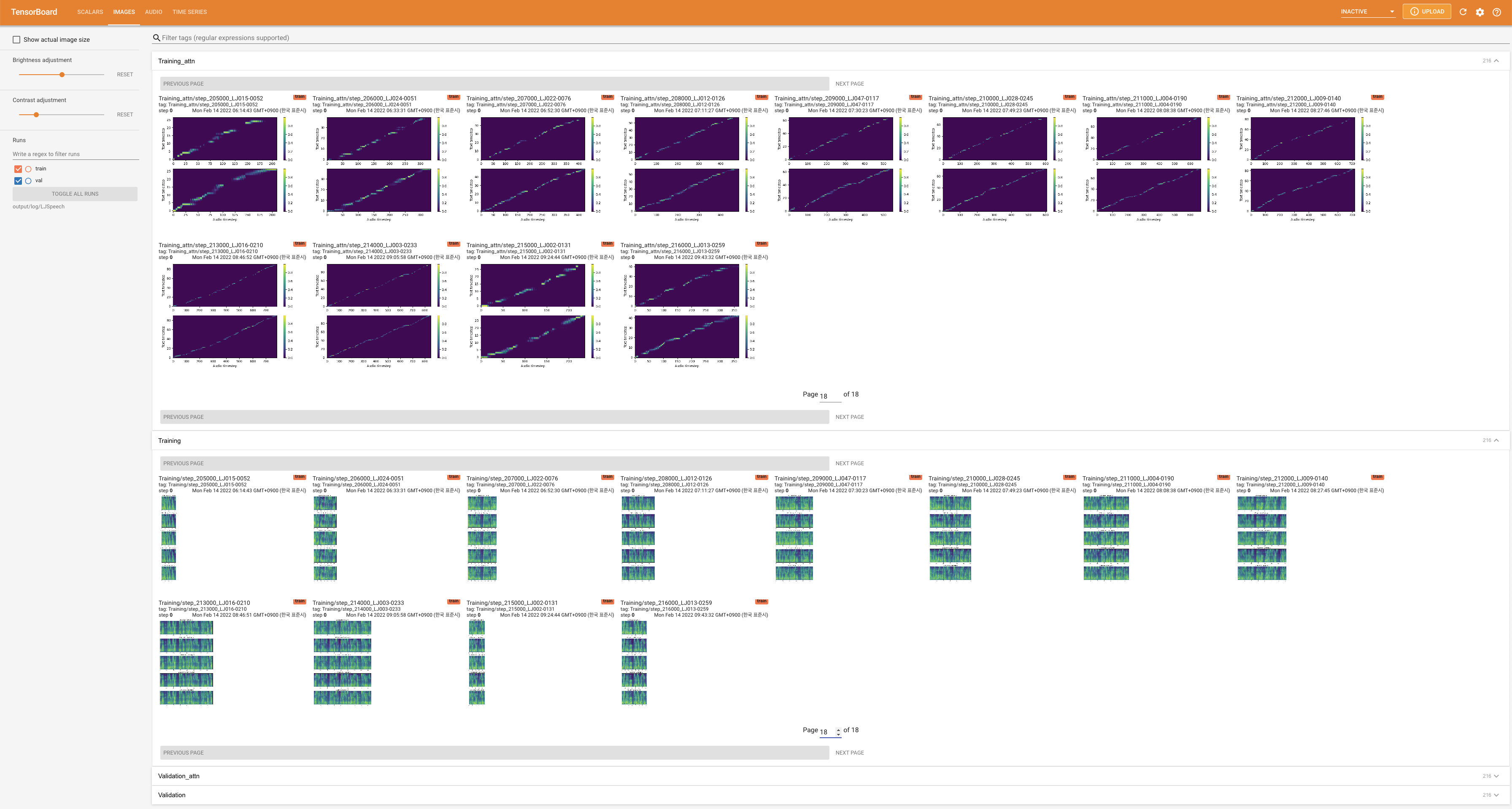
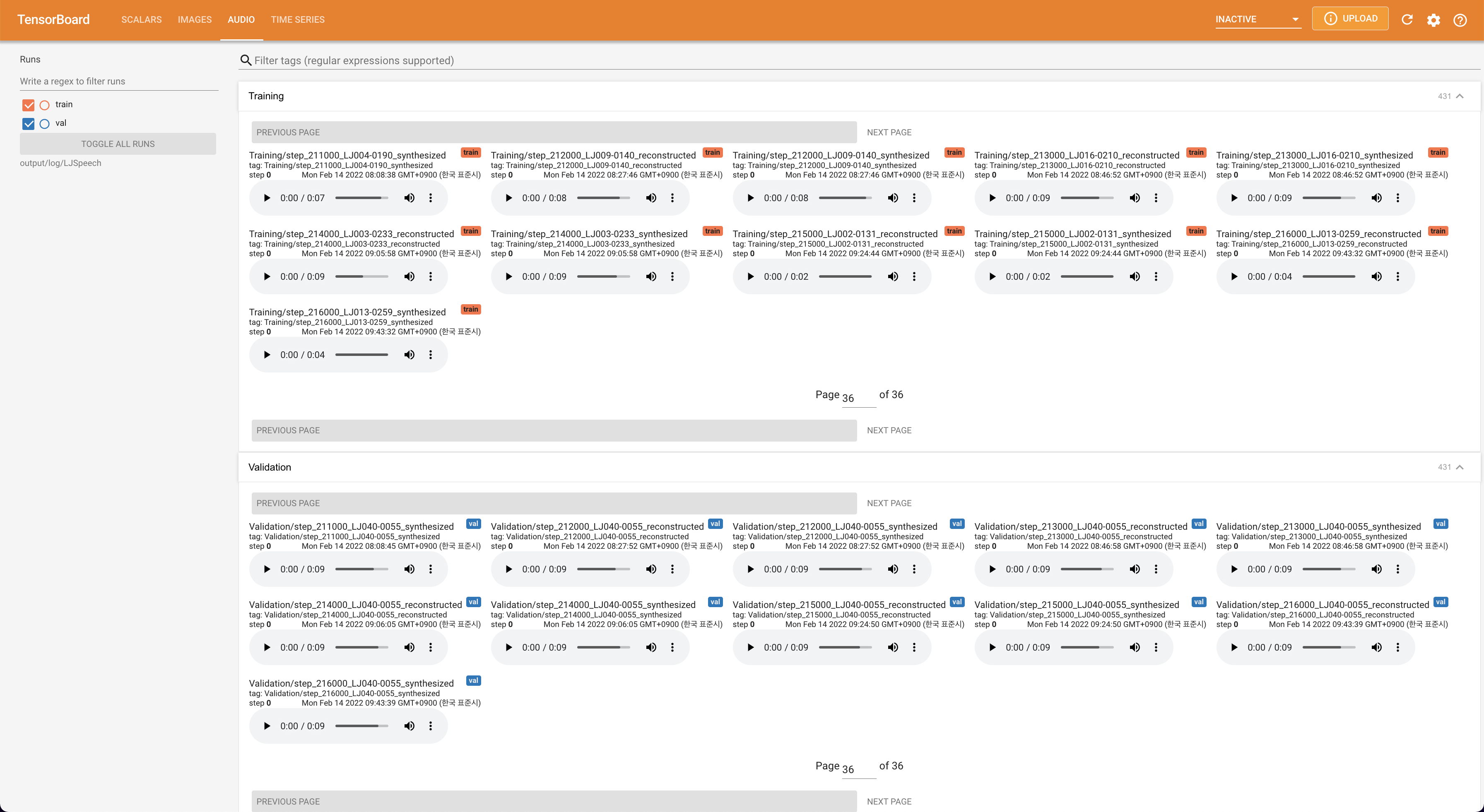
tensorboard --logdir output/log
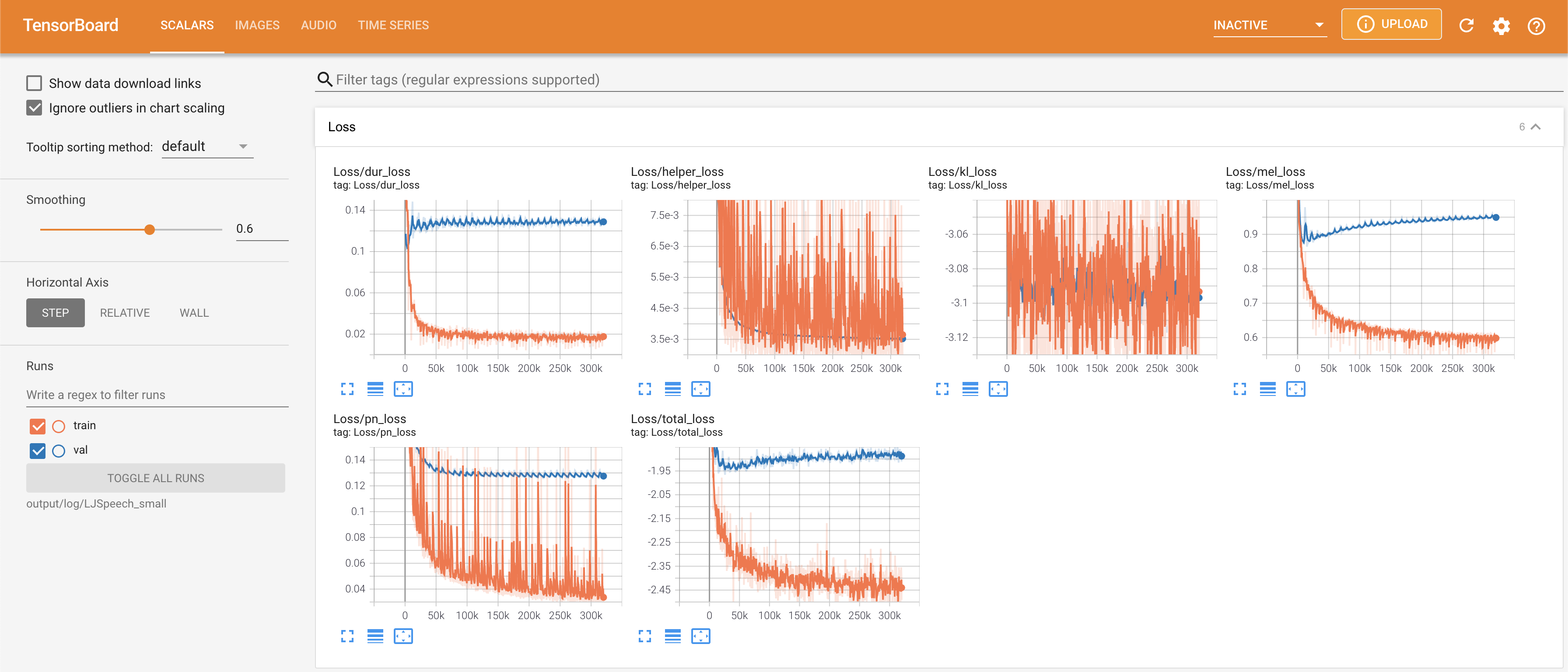
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
# In the train.yaml
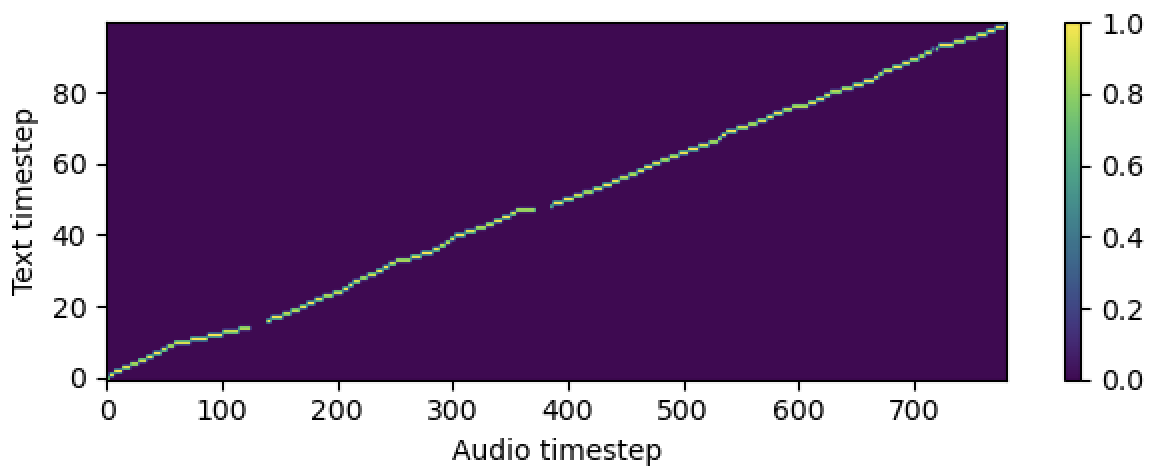
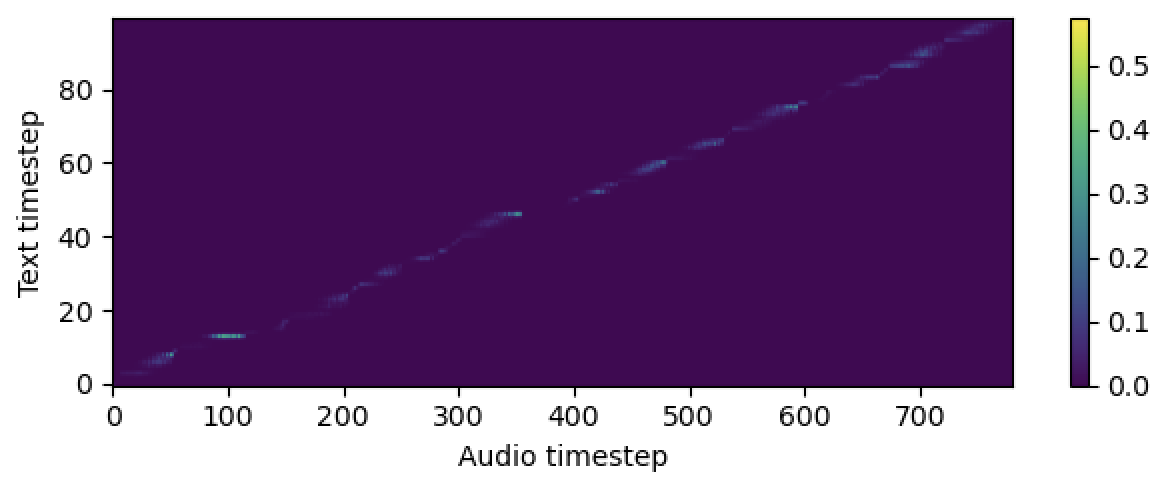
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]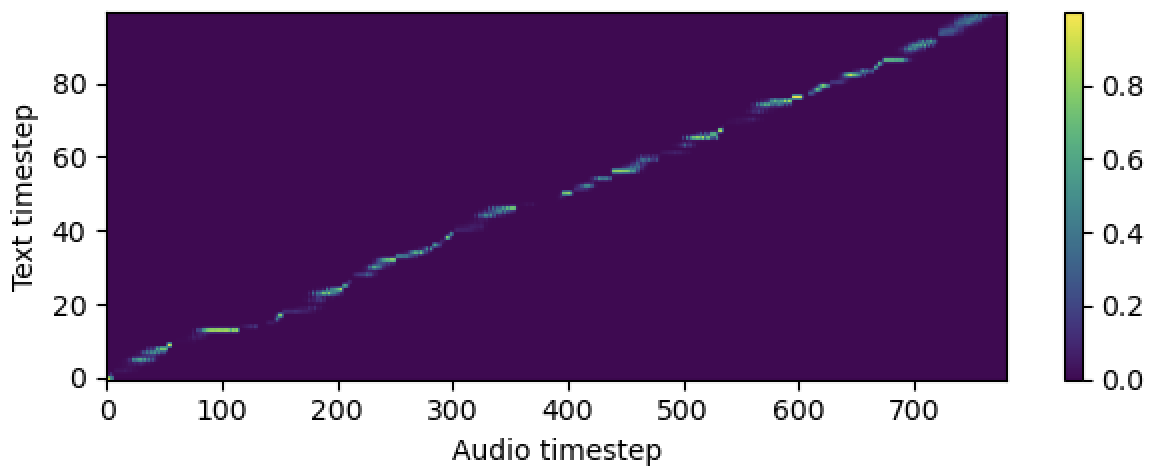
Cite este repositório pelo "citar este repositório" da seção Sobre (canto superior direito da página principal).


