TTS_Data_Maker
1.0.0
链接到TTS存储库-https://github.com/coqui-ai/tts
链接到PYPI中的TTS -https://pypi.org/project/tts/#description
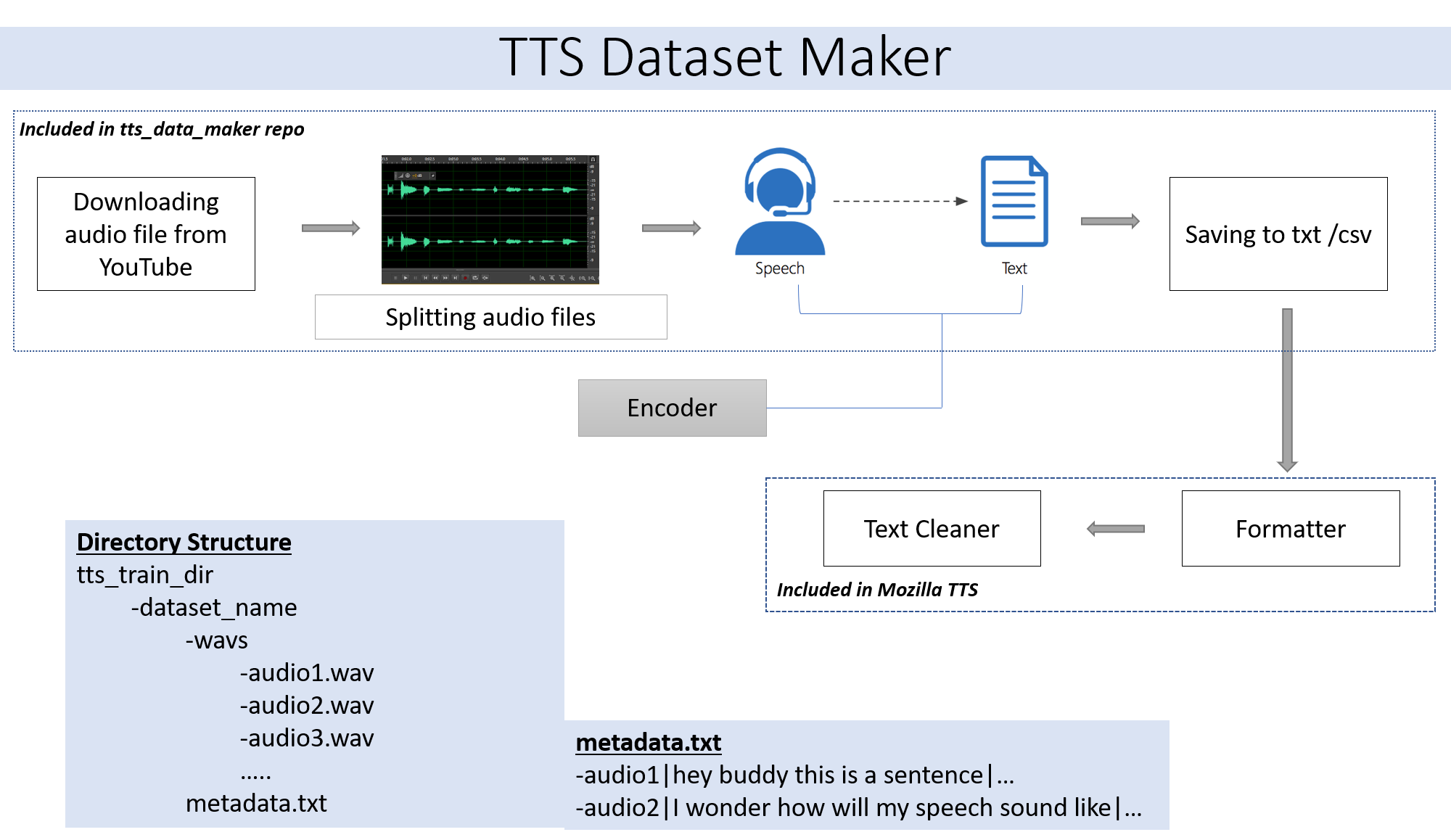
如果您想使用自己的跳过步骤2的音频文件。如果您想使用YouTube步骤2的各种扬声器的音频,则适合您。
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
要从YouTube视频CD下载音频,然后将视频目录中的YouTube视频CD下载到tts_data_maker目录中,以下是下面下载got视频的示例命令:) .) ... mp4文件将在main_audio目录中下载。必须将视频_link和扬声器/视频名称作为参数提供给以下Python文件。
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
要将下载的音频拆分为较小的部分,请使用extract_semt.py文件。
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
对于音频到语音,我们将选择许多文本到语音引擎,包括Google和IBM的文本引擎。运行以下代码段以从音频片段中提取文本。
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
最终数据集将具有metadata.txt和audio_split文件夹,其中所有音频文件(例如1.Wav,2.Wav,2.Wav,3.Wav和Suon Metadata.txt文件)将看起来像这样。
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
包含所有音频文件的WAV文件夹将看起来像这样
wav
-audio1.wav
-audio2.wav
-audio3.wav
最后,我们应该具有以下文件夹结构:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
从github readmes实施总是很痛苦。为了使事情变得更容易,整个过程已经在Google合作中实施 -
必须遵循使用TTS创建模型的数据集创建。可以从此笔记本中找到相同的详细信息 -
如果在合作或云上运行,请忽略。
该存储库中广泛使用的PYDUB模块使用FFMPEG处理WAV文件。因此,如果在本地计算机上运行,则需要下载FFMPEG,并且必须将BIN文件夹添加到路径。
链接-https://ffmpeg.org/download.html
从上述链接中的获取软件包和可执行文件部分下载。


