TTS_Data_Maker
1.0.0
TTS 리포지토리 링크 -https://github.com/coqui-ai/tts
pypi -https://pypi.org/project/tts/#description의 tts 링크
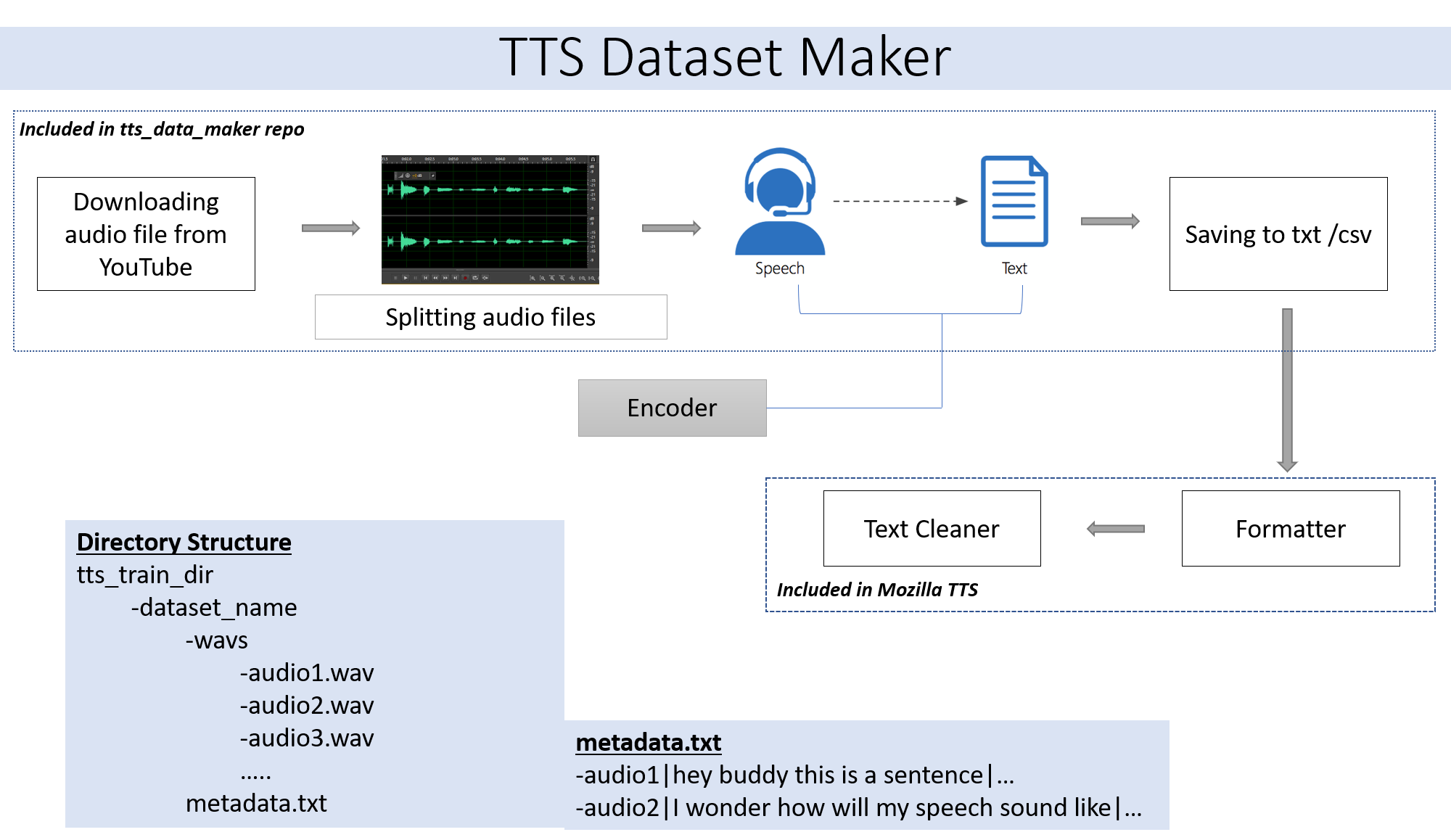
자신의 스킵 2 단계의 오디오 파일을 사용하려면 2 단계입니다. YouTube 2에서 사용할 수있는 광범위한 스피커에서 오디오를 사용하려면 귀하를위한 것입니다.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
YouTube Video CD에서 오디오를 TTS_DATA_MAKER 디렉토리로 다운로드하려면 Audio_Download.py를 사용하려면 GOT 비디오를 다운로드하기위한 샘플 명령입니다. : A MP4 파일은 main_audio 디렉토리에서 다운로드됩니다. video_link 및 스피커/비디오 이름을 아래 Python 파일에 대한 인수로 제공해야합니다.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
다운로드 된 오디오를 작은 부품으로 분할하려면 리포지토리의 Extrac_Segment.py 파일을 사용하십시오.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
오디오 대 음성을 위해 Google 및 IBM을 포함하여 많은 텍스트 To Speech Engine을 선택합니다. 아래 코드 스 니펫을 실행하여 오디오 스 니펫에서 텍스트를 추출하십시오.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
최종 데이터 세트에는 1.wav, 2.wav, 3.wav 및 곧 metadata.txt 파일과 같은 모든 오디오 파일이있는 Metadata.txt 및 Audio_split 폴더가 있습니다.
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
모든 오디오 파일을 포함하는 WAV 폴더는 다음과 같습니다.
wav
-audio1.wav
-audio2.wav
-audio3.wav
결국, 우리는 다음과 같은 폴더 구조를 가져야합니다.
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Github Readmes에서 구현하는 것은 항상 고통입니다. 상황을 쉽게하기 위해 전체 프로세스가 Google Collab에서 구현되었습니다.
데이터 세트 생성에 이어 TTS를 사용하여 모델을 작성해야합니다. 이에 대한 세부 사항에 대한 자세한 내용은이 노트북에서 찾을 수 있습니다.
Collab 또는 Cloud에서 실행 중인지 무시하십시오.
이 저장소에서 광범위하게 사용되는 Pydub 모듈은 FFMPEG를 사용하여 WAV 파일을 처리합니다. 따라서 로컬 컴퓨터에서 실행되면 FFMPEG를 다운로드해야하며 BIN 폴더를 경로에 추가해야합니다.
링크 -https://ffmpeg.org/download.html
위의 링크에서 Get Packages 및 실행 파일 섹션에서 다운로드하십시오.


