TTS_Data_Maker
1.0.0
ลิงก์ไปยังที่เก็บ TTS - https://github.com/coqui-ai/tts
ลิงก์ไปยัง TTS ใน pypi - https://pypi.org/project/tts/#description
หากคุณต้องการใช้ไฟล์เสียงของการข้ามขั้นตอนที่ 2 ของคุณเอง หากคุณต้องการใช้เสียงจากลำโพงที่หลากหลายจาก YouTube Step 2 เหมาะสำหรับคุณ
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
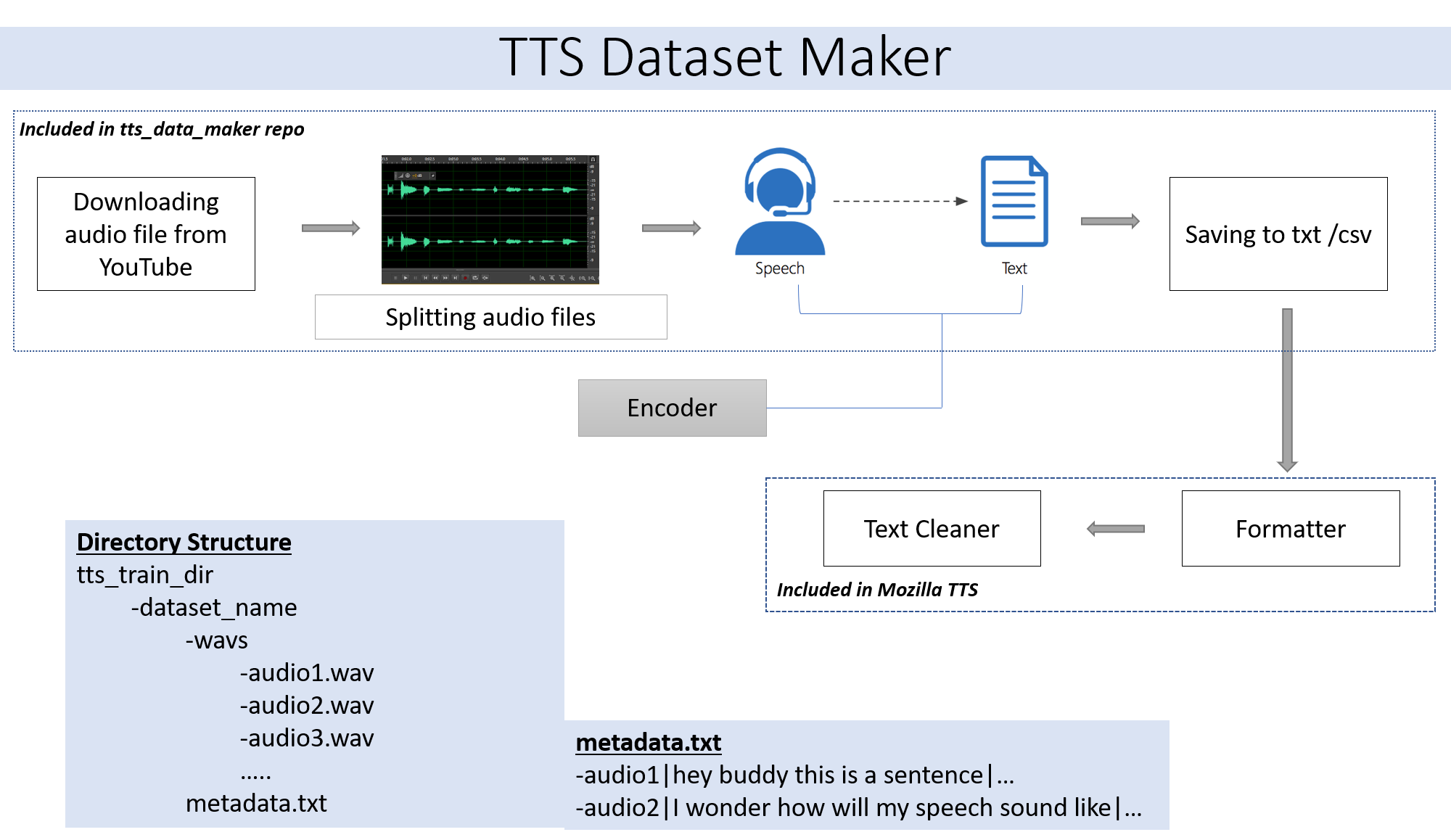
ในการดาวน์โหลดเสียงจากซีดีวิดีโอ YouTube ลงในไดเรกทอรี TTS_DATA_MAKER และใช้ AUDIO_DOWNLOAD.PY ด้านล่างเป็นคำสั่งตัวอย่างสำหรับการดาวน์โหลดวิดีโอ GOT :) ไฟล์ MP4 จะถูกดาวน์โหลดในไดเรกทอรี Main_audio จำเป็นต้องให้ Video_Link และชื่อลำโพง/วิดีโอเป็นอาร์กิวเมนต์ไปยังไฟล์ Python ด้านล่าง
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
ในการแยกเสียงที่ดาวน์โหลดออกเป็นชิ้นส่วนที่เล็กกว่าให้ใช้ไฟล์ extract_segment.py ของที่เก็บ
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
สำหรับเสียงในการพูดเราจะเลือกข้อความหลายข้อความเป็นเครื่องมือพูดรวมถึงของ Google และ IBM เรียกใช้ตัวอย่างโค้ดด้านล่างเพื่อแยกข้อความจากตัวอย่างเสียง
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
ชุดข้อมูลสุดท้ายจะมี metadata.txt และโฟลเดอร์ audio_split ที่มีไฟล์เสียงทั้งหมดเช่น 1.wav, 2.wav, 3.wav และไฟล์ metadata.txt ในไม่ช้าจะมีลักษณะเช่นนี้
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
โฟลเดอร์ WAV ที่มีไฟล์เสียงทั้งหมดจะเป็นแบบนี้
wav
-audio1.wav
-audio2.wav
-audio3.wav
ในท้ายที่สุดเราควรมีโครงสร้างโฟลเดอร์ต่อไปนี้:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
การใช้งานจากการอ่าน GitHub นั้นเป็นความเจ็บปวดเสมอ เพื่อให้สิ่งต่าง ๆ ง่ายขึ้นกระบวนการทั้งหมดได้ถูกนำไปใช้ใน Google Collab -
การสร้างชุดข้อมูลจะต้องตามมาด้วยการสร้างแบบจำลองโดยใช้ TTS รายละเอียดของเดียวกันสามารถพบได้จากสมุดบันทึกนี้ -
โปรดเพิกเฉยต่อการทำงานร่วมกันหรือคลาวด์
โมดูล PyDub ใช้อย่างกว้างขวางในที่เก็บนี้ใช้ FFMPEG เพื่อประมวลผลไฟล์ WAV ดังนั้นหากทำงานบนเครื่องในท้องถิ่นจะต้องดาวน์โหลด FFMPEG และต้องเพิ่มโฟลเดอร์ BIN ลงในเส้นทาง
ลิงค์ - https://ffmpeg.org/download.html
ดาวน์โหลดจาก Get Packages & Executable Files ในลิงค์ด้านบน


