TTS_Data_Maker
1.0.0
Ссылка на репозиторий TTS - https://github.com/coqui-ai/tts
Ссылка на TTS в PYPI - https://pypi.org/project/tts/#description
Если вы хотите использовать аудиофайл вашего собственного шага 2. Если вы хотите использовать аудио из широкого спектра динамиков, доступных на YouTube Шаг 2 для вас.
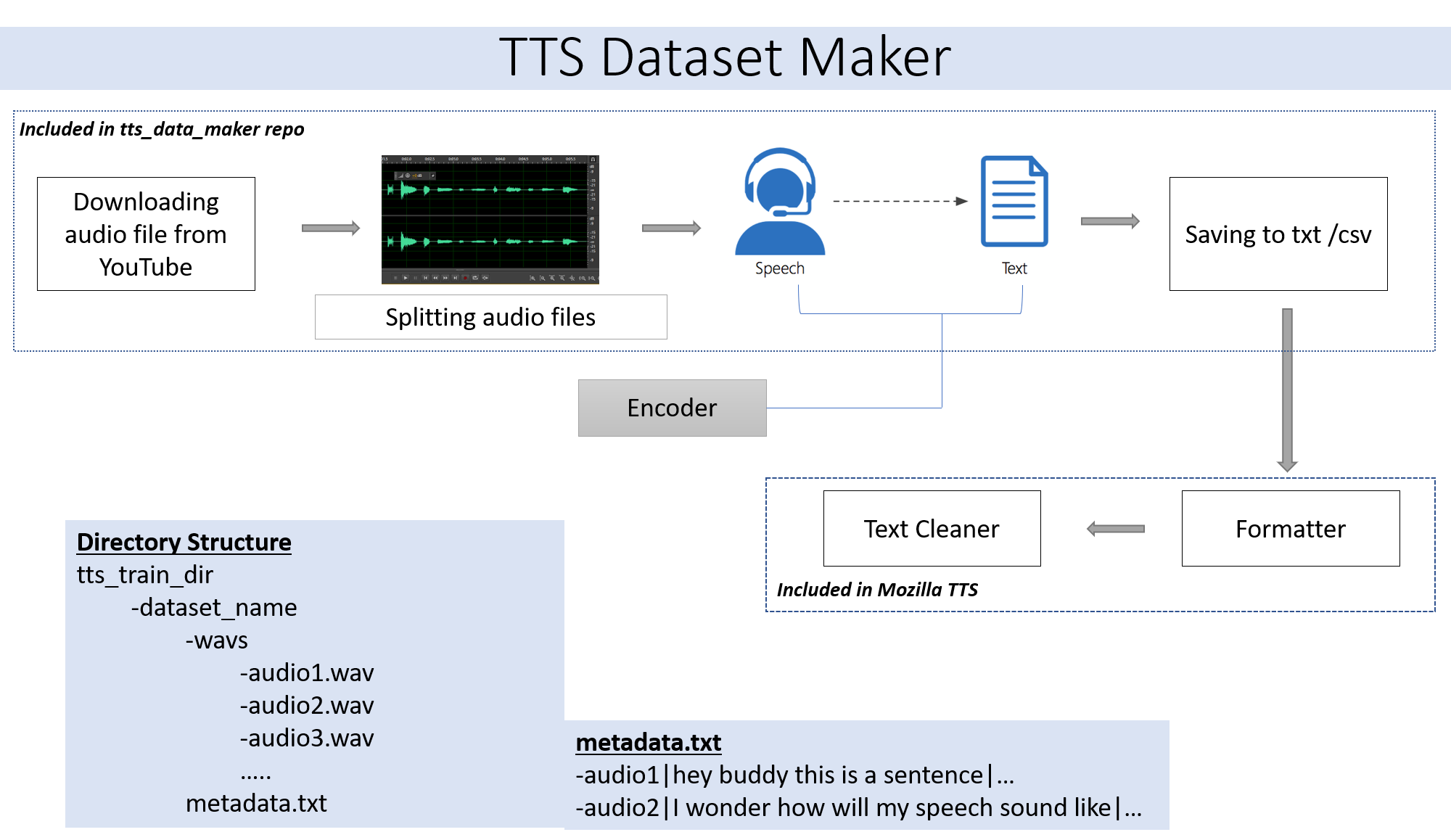
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
Чтобы загрузить аудио с видео CD YouTube в каталог TTS_DATA_MAKER и использовать Audio_download.py ниже представляет собой примерную команду для загрузки видео Got :) .A MP4 -файл будет загружен в каталоге main_audio. Требуется дать имени Video_link и динамика/видео в качестве аргументов в файле Python ниже.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Для разделения загруженного звука на более мелкие детали используйте файл extract_segment.py репозитория.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Для звука к речи мы выберем во многих текстах в речевой механизм, включая Google и IBM. Запустите приведенный ниже фрагмент кода, чтобы извлечь текст из звуковых фрагментов.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
Окончательный набор данных будет иметь папку Metadata.txt и Audio_split, имеющая все аудиофайлы, такие как 1.WAV, 2.WAV, 3.WAV и скорость MetAdata.txt будет выглядеть так
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
Папка WAV, содержащая все аудиофайлы, будет выглядеть так
wav
-audio1.wav
-audio2.wav
-audio3.wav
В конце концов, у нас должна быть следующая структура папок:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Реализация из GitHub Readmes всегда больно. Чтобы облегчить ситуацию, весь процесс был реализован в Google Collab -
Создание набора данных должно сопровождаться созданием модели с использованием TTS. Подробности того же самого можно найти из этой записной книжки -
Пожалуйста, игнорируйте, если вы работаете на Collab или Cloud.
Pydub Module широко используется в этом репозитории использует FFMPEG для обработки файлов WAV. Следовательно, при запуске на локальной машине требуется загрузка FFMPEG, а папка BIN должна быть добавлена в путь.
Ссылка - https://ffmpeg.org/download.html
Загрузите из разделения Get Packages & Executiveable Files по вышеуказанной ссылке.


