TTS_Data_Maker
1.0.0
رابط لمستودع TTS - https://github.com/coquii-ai/tts
رابط إلى TTS في pypi - https://pypi.org/project/tts/#description
إذا كنت ترغب في استخدام ملف صوتي من Skip Step 2. إذا كنت ترغب في استخدام الصوت من مجموعة واسعة من مكبرات الصوت المتاحة من YouTube Step 2 هي لك.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
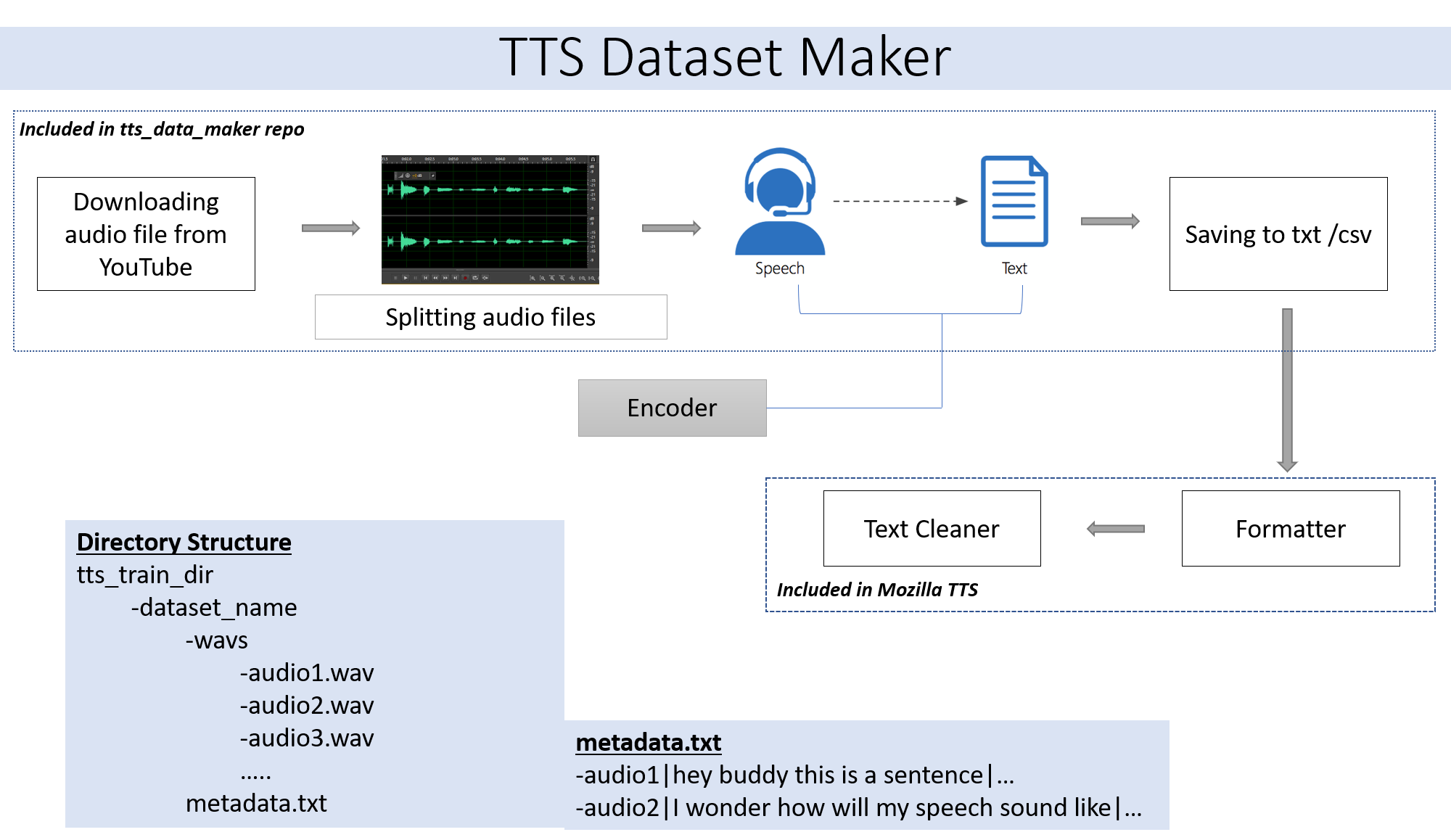
لتنزيل صوت من قرص فيديو على YouTube في دليل TTS_DATA_MAKER واستخدام Audio_Download.py أدناه هو أمر نموذج لتنزيل فيديو GOT :) .A. مطلوب إعطاء video_link واسم مكبر الصوت/الفيديو كوسائط لملف Python أدناه.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
لتقسيم الصوت الذي تم تنزيله إلى أجزاء أصغر ، استخدم ملف extract_segment.py من المستودع.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
للحصول على الصوت إلى الكلام ، سنختار العديد من النصوص إلى محرك الكلام بما في ذلك محرك Google و IBM. قم بتشغيل مقتطف الرمز أدناه لاستخراج النص من قصاصات الصوت.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
ستحتوي مجموعة البيانات النهائية على Metadata.txt و Audio_split التي تحتوي على جميع ملفات الصوت مثل 1.WAV و 2.WAV و 3.WAV و Metadata.txt قريبًا
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
سيبدو مجلد WAV الذي يحتوي على جميع ملفات الصوت هكذا
wav
-audio1.wav
-audio2.wav
-audio3.wav
في النهاية ، يجب أن يكون لدينا بنية المجلد التالية:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
إن التنفيذ من GitHub Readmes هو دائمًا ألم. لتسهيل الأمور ، تم تنفيذ العملية بأكملها في Google Collab -
يجب أن يتبع إنشاء مجموعة البيانات من خلال إنشاء نموذج باستخدام TTS. يمكن العثور على تفاصيل نفس الشيء من هذا الكمبيوتر الدفتري -
يرجى تجاهل ما إذا كان الجري على Collab أو Cloud.
تستخدم وحدة PYDUB المستخدمة على نطاق واسع في هذا المستودع FFMPEG لمعالجة ملفات WAV. وبالتالي ، إذا كان تشغيل جهاز محلي يتطلب تنزيل FFMPEG ويجب إضافة مجلد BIN إلى المسار.
Link - https://ffmpeg.org/download.html
قم بتنزيل قسم Get Get Packages والملفات القابلة للتنفيذ على الرابط أعلاه.


