TTS_Data_Maker
1.0.0
Link zu TTS -Repository - https://github.com/coqui-ai/tts
Link zu TTs in Pypi - https://pypi.org/project/tts/#description
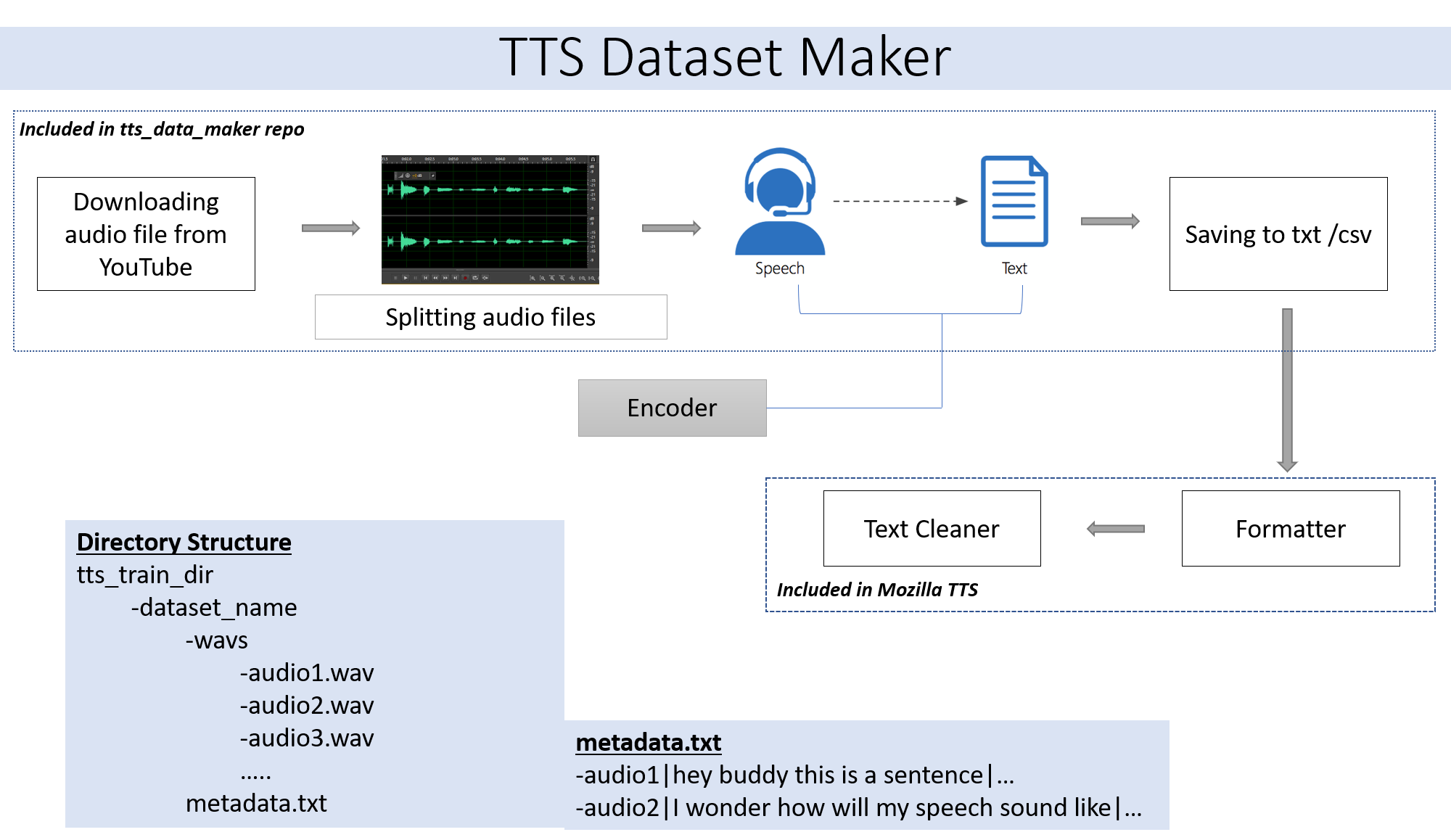
Wenn Sie eine Audiodatei Ihres eigenen Skip -Schritts verwenden möchten, Schritt 2. Wenn Sie Audio aus einer Vielzahl von Lautsprechern verwenden möchten, die bei YouTube erhältlich sind, ist Schritt 2 für Sie.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
Um ein Audio von YouTube Video -CD in das Verzeichnis TTS_DATA_MAKER herunterzuladen und verwenden Sie Audio_download.py unten finden Sie ein Beispielbefehl zum Herunterladen eines GOT -Videoes :) .A MP4 -Datei wird im Main_audio -Verzeichnis heruntergeladen. Es ist erforderlich, den folgenden Python -Datei den Namen Video_Link und Speaker/Video als Argumente zu geben.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Um das heruntergeladene Audio in kleinere Teile aufzuteilen, verwenden Sie die Datei extract_segment.py des Repositorys.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Für Audio zu Sprache wählen wir viele Text -zu -Sprach -Engine, einschließlich der von Google und IBM. Führen Sie das folgende Code -Snippet aus, um Text aus den Audio -Snippets zu extrahieren.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
Der endgültige Datensatz verfügt
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
Der WAV -Ordner, der alle Audiodateien enthält, sieht so aus
wav
-audio1.wav
-audio2.wav
-audio3.wav
Am Ende sollten wir die folgende Ordnerstruktur haben:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Die Implementierung aus Github Readmes ist immer ein Schmerz. Um die Dinge zu erleichtern, wurde der gesamte Prozess in Google Collaby implementiert -
Auf die Erstellung von Datensatz muss ein Modell mit TTS erstellt werden. Details desselben finden Sie in diesem Notizbuch -
Bitte ignorieren Sie, ob Sie in Zusammenarbeit oder Cloud ausgeführt werden.
Das in diesem Repository verwendete PyDub -Modul verwendet FFMPEG, um WAV -Dateien zu verarbeiten. Wenn Sie auf einem lokalen Computer ausgeführt werden, muss FFMPEG heruntergeladen werden und der Bin -Ordner muss dem Pfad hinzugefügt werden.
Link - https://ffmpeg.org/download.html
Laden Sie den Abschnitt "Pakete & ausführbare Dateien" im obigen Link herunter.


