TTS_Data_Maker
1.0.0
Enlace al repositorio de TTS - https://github.com/coqui-ai/tts
Enlace a TTS en Pypi - https://pypi.org/project/tts/#description
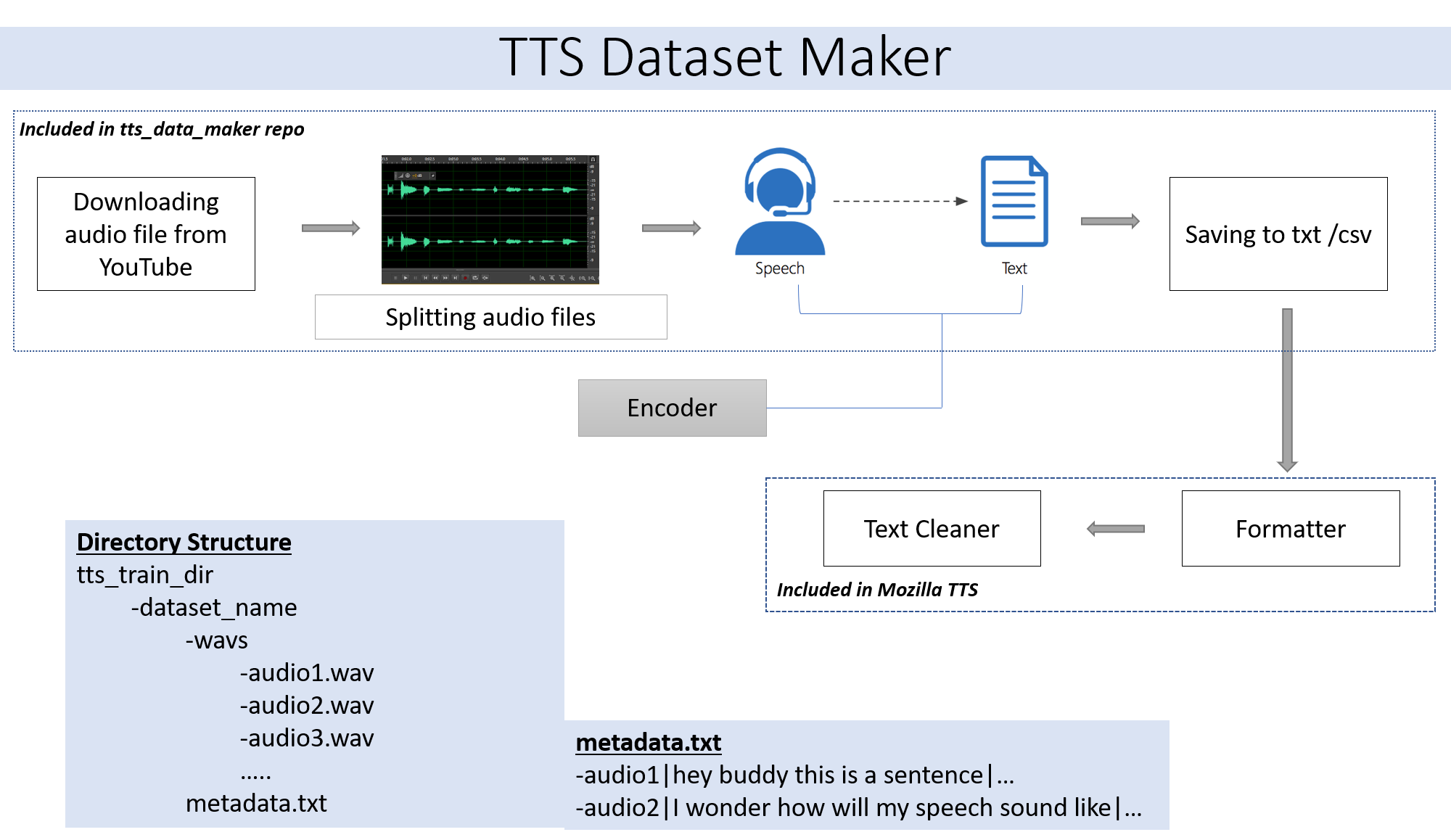
Si desea usar un archivo de audio de su propio Skip Paso 2. Si desea usar audio desde una amplia gama de altavoces disponibles en YouTube, paso 2 es para usted.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
Para descargar un audio del CD de video de YouTube en el directorio TTS_DATA_MAKER y usar audio_download.py a continuación hay un comando de muestra para descargar un video Got :). Un archivo MP4 se descargará en el directorio Main_audio. Se requiere dar el nombre de video_link y altavoz/video como argumentos en el archivo Python a continuación.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Para dividir el audio descargado en piezas más pequeñas, use el archivo extract_segment.py del repositorio.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Para el audio al habla elegiremos en muchos textos al motor del habla, incluidos los de Google e IBM. Ejecute el fragmento de código a continuación para extraer texto de los fragmentos de audio.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
El conjunto de datos final tendrá la carpeta metadata.txt y audio_split que tiene todos los archivos de audio como 1.wav, 2.wav, 3.wav y pronto el archivo metadata.txt se verá así
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
La carpeta WAV que contiene todos los archivos de audio se verá así
wav
-audio1.wav
-audio2.wav
-audio3.wav
Al final, debemos tener la siguiente estructura de carpeta:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Implementar desde Github Readmes siempre es un dolor. Para facilitar las cosas, todo el proceso se ha implementado en Google Collab -
La creación del conjunto de datos debe seguirse creando un modelo usando TTS. Los detalles del mismo se pueden encontrar en este cuaderno -
Ignore si se ejecuta en colaboración o nube.
El módulo PyDub utilizado ampliamente en este repositorio utiliza FFMPEG para procesar archivos WAV. Por lo tanto, si se ejecuta en una máquina local, requiere que se descargue FFMPEG y se debe agregar la carpeta Bin a la ruta.
Enlace - https://ffmpeg.org/download.html
Descargar desde la sección Obtener paquetes y archivos ejecutables en el enlace anterior.


