TTS_Data_Maker
1.0.0
TTSリポジトリへのリンク-https://github.com/coqui-ai/tts
Pypi -https://pypi.org/project/tts/#descriptionのTTSへのリンク
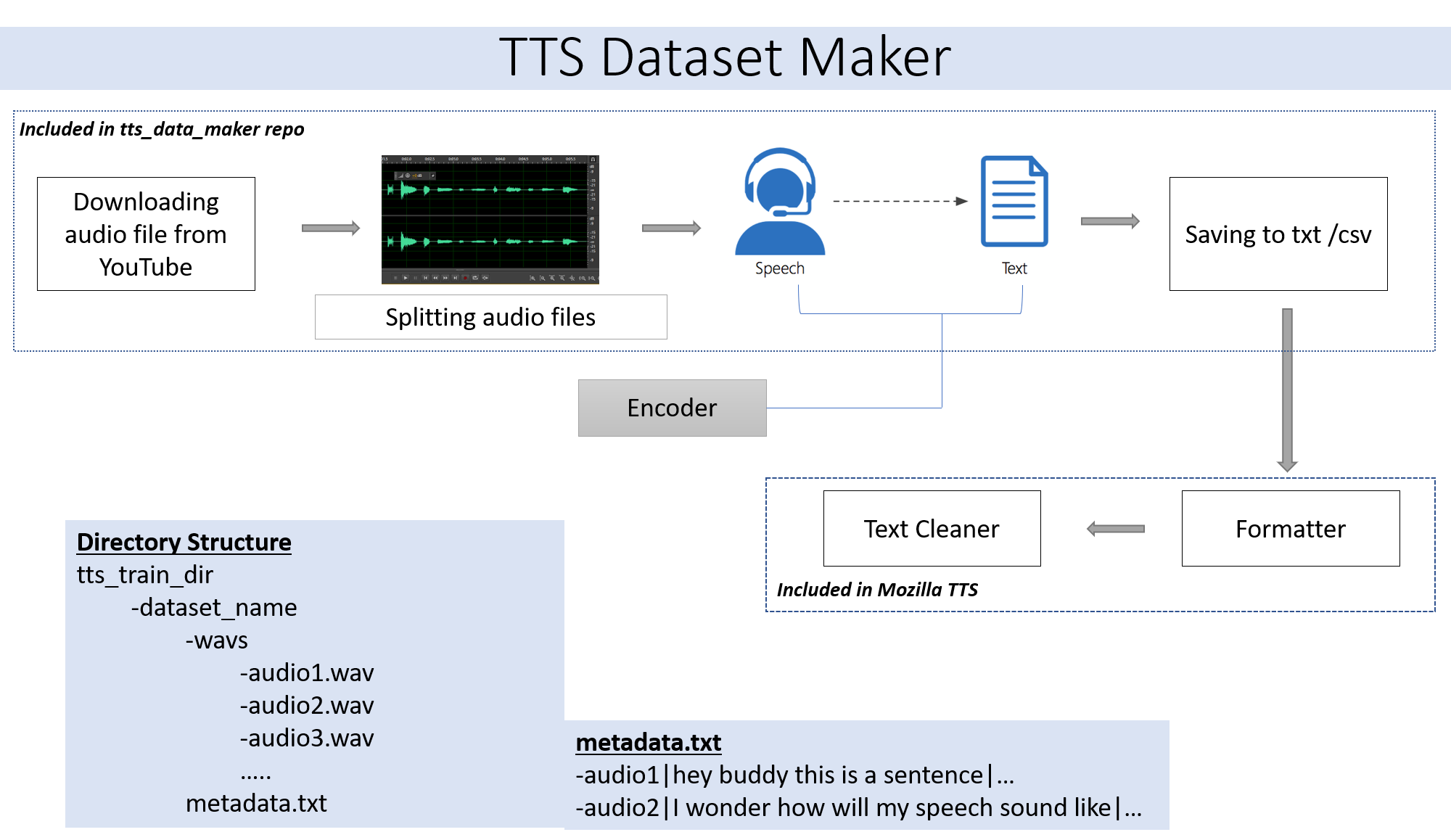
独自のスキップステップ2のオーディオファイルを使用する場合。 YouTubeから入手可能な幅広いスピーカーのオーディオを使用したい場合は、ステップ2が最適です。
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
YouTube Video CDからTTS_DATA_MAKERディレクトリにオーディオをダウンロードし、audio_download.pyを使用するのは、gotビデオをダウンロードするためのサンプルコマンドです:) .mp4ファイルはmain_audioディレクトリにダウンロードされます。以下のPythonファイルの引数としてVideo_linkとスピーカー/ビデオ名を指定する必要があります。
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
ダウンロードしたオーディオを小さな部品に分割するには、リポジトリのextract_segment.pyファイルを使用してください。
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
音声からスピーチについては、GoogleやIBMのものを含む多くのテキストからスピーチエンジンよりも選択します。以下のコードスニペットを実行して、オーディオスニペットからテキストを抽出します。
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
最終的なデータセットには、metadata.txtとaudio_splitフォルダーがあります。
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
すべてのオーディオファイルを含むWAVフォルダーは次のようになります
wav
-audio1.wav
-audio2.wav
-audio3.wav
最終的に、次のフォルダー構造が必要です。
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Github Readmesからの実装は常に苦痛です。物事を簡単にするために、プロセス全体がGoogleコラボで実装されています -
データセットの作成に続いて、TTSを使用してモデルを作成する必要があります。同じことの詳細は、このノートブックから見つけることができます -
コラボまたはクラウドで実行されている場合は無視してください。
このリポジトリで広く使用されているPydubモジュールは、FFMPEGを使用してWAVファイルを処理します。したがって、ローカルマシンで実行される場合は、FFMPEGをダウンロードする必要があり、BINフォルダーをパスに追加する必要があります。
リンク-https://ffmpeg.org/download.html
上記のリンクのGet Packages and Executable Filesセクションからダウンロードします。


