TTS_Data_Maker
1.0.0
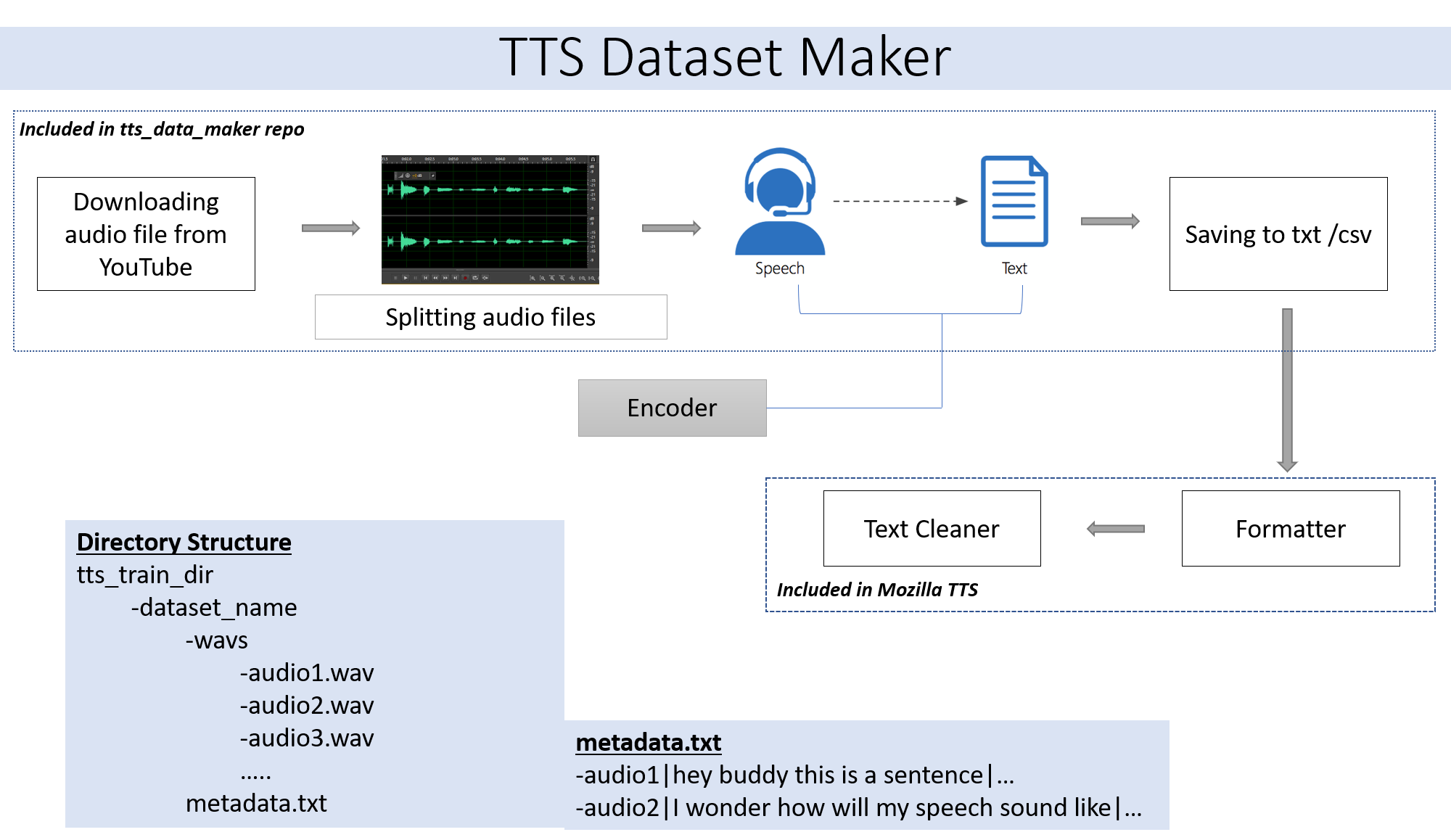
Link para o repositório TTS - https://github.com/coqui-aii/tts
Link para TTS em Pypi - https://pypi.org/project/tts/#description
Se você deseja usar um arquivo de áudio do seu próprio Skip Etapa 2. Se você deseja usar o áudio de uma ampla gama de alto -falantes disponíveis no YouTube Etapa 2 é para você.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
Para baixar um áudio do CD de vídeo do YouTube no diretório TTS_DATA_MAKER e use Audio_Download.py abaixo é um comando de amostra para baixar um vídeo Got Video :). Um arquivo MP4 será baixado no diretório main_audio. É necessário fornecer o nome de vídeo e alto -falante/alto -falante como argumentos ao arquivo python abaixo.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Para dividir o áudio baixado em peças menores, use o arquivo extract_segment.py do repositório.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Para o áudio para discursos, escolheremos muitos texto para mecanismo de fala, incluindo o do Google e a IBM. Execute o trecho de código abaixo para extrair texto dos trechos de áudio.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
O conjunto de dados final terá metadata.txt e pasta Audio_split com todos os arquivos de áudio como 1.wav, 2.wav, 3.wav e logo o arquivo de metadados.txt parecerá assim
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
A pasta WAV contendo todos os arquivos de áudio ficará assim
wav
-audio1.wav
-audio2.wav
-audio3.wav
No final, devemos ter a seguinte estrutura de pastas:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
A implementação do Github Readmes é sempre uma dor. Para facilitar as coisas, todo o processo foi implementado no Google Collab -
A criação do conjunto de dados deve ser seguida pela criação de um modelo usando TTS. Detalhes do mesmo podem ser encontrados neste caderno -
Por favor, ignore se estiver executando em colaboração ou nuvem.
O módulo PyDub usado extensivamente neste repositório usa o FFMPEG para processar arquivos WAV. Portanto, se estiver em execução em uma máquina local, é necessário baixar o FFMPEG e a pasta BIN deve ser adicionada ao caminho.
Link - https://ffmpeg.org/download.html
Faça o download da seção Get Packages & Executabable Arquivos no link acima.


