TTS_Data_Maker
1.0.0
Lien vers le référentiel TTS - https://github.com/coqui-ai/tts
Lien vers TTS dans PYPI - https://pypi.org/project/tts/#description
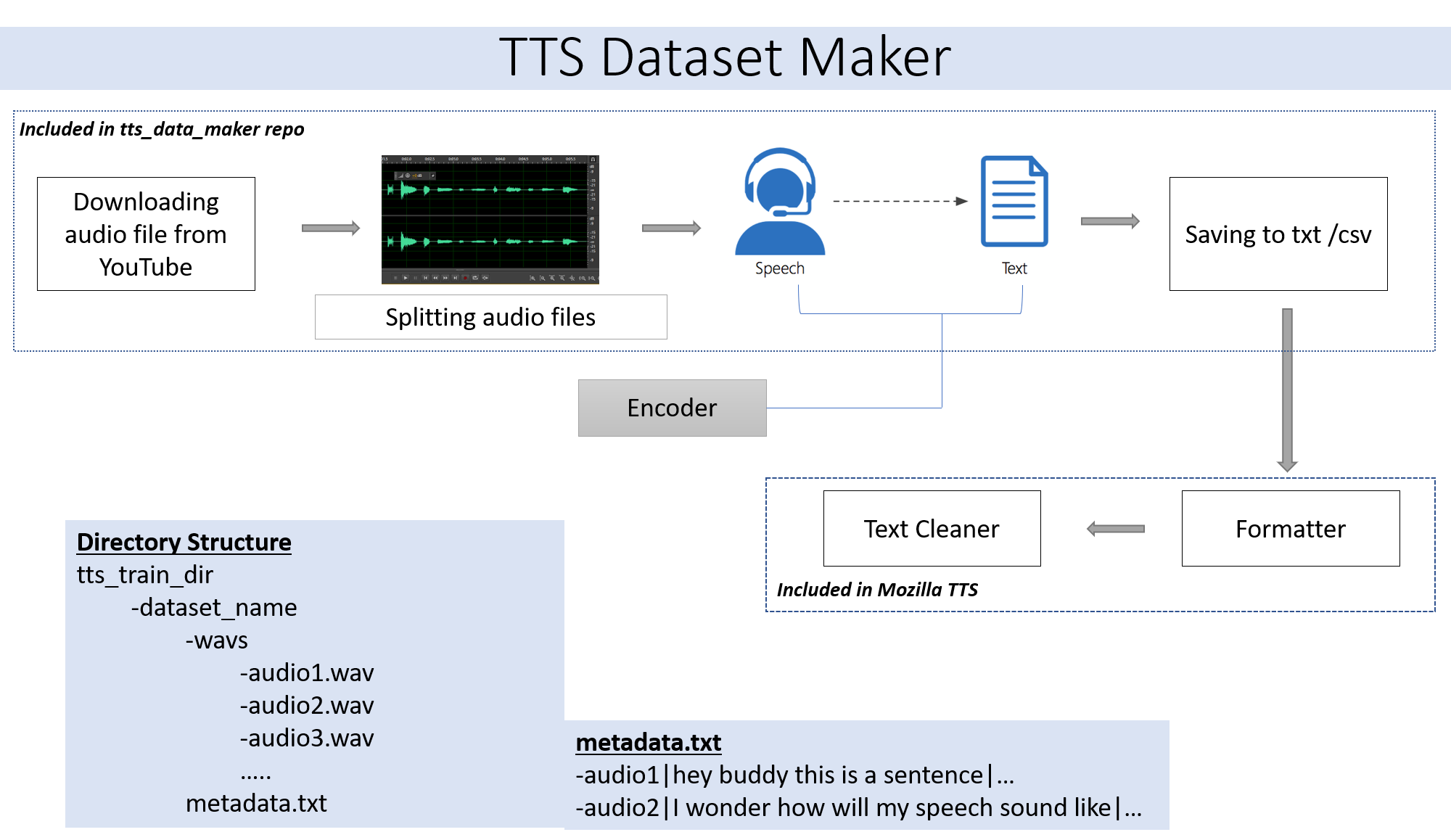
Si vous souhaitez utiliser un fichier audio de votre propre étape de saut 2. Si vous souhaitez utiliser l'audio à partir d'un large éventail de haut-parleurs disponibles sur YouTube, l'étape 2 est pour vous.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
Pour télécharger un CD vidéo audio à partir de YouTube dans le répertoire TTS_DATA_MAKER et utiliser Audio_Download.py ci-dessous est un exemple de commande pour télécharger une vidéo GOT :) .a MP4 sera téléchargé dans le répertoire Main_audio. Il est nécessaire de donner le nom vidéo_link et le haut-parleur / vidéo comme arguments au fichier Python ci-dessous.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Pour diviser l'audio téléchargé en pièces plus petites, utilisez le fichier extract_segment.py du référentiel.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Pour que l'audio à la parole, nous choisirons de nombreux textes à un moteur vocal, y compris ceux de Google et IBM. Exécutez l'extrait de code ci-dessous pour extraire du texte des extraits audio.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
L'ensemble de données final aura un dossier metadata.txt et audio_split ayant tous les fichiers audio comme 1.wav, 2.wav, 3.wav et bientôt metadata.txt le fichier ressemblera à ceci
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
Le dossier WAV contenant tous les fichiers audio ressemblera à ceci
wav
-audio1.wav
-audio2.wav
-audio3.wav
En fin de compte, nous devons avoir la structure du dossier suivant:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
La mise en œuvre de GitHub Readmes est toujours une douleur. Pour faciliter les choses, l'ensemble du processus a été mis en œuvre dans Google Collab
La création de l'ensemble de données doit être suivie par la création d'un modèle à l'aide de TTS. Les détails de la même chose peuvent être trouvés à partir de ce cahier -
Veuillez ignorer si vous exécutez sur Collab ou Cloud.
Le module PYDUB utilisé largement dans ce référentiel utilise FFMPEG pour traiter les fichiers WAV. Par conséquent, si elle fonctionne sur une machine locale, il faut télécharger FFMPEG et le dossier BIN doit être ajouté au chemin.
Lien - https://ffmpeg.org/download.html
Téléchargez à partir de la section Get Packages & Exécutable des fichiers sur le lien ci-dessus.


