TTS_Data_Maker
1.0.0
Link ke TTS Repository - https://github.com/coqui-ai/tts
Tautan ke TTS di PYPI - https://pypi.org/project/tts/#description
Jika Anda ingin menggunakan file audio dari Skip Langkah 2 Anda sendiri. Jika Anda ingin menggunakan audio dari berbagai speaker yang tersedia dari YouTube Langkah 2 adalah untuk Anda.
git clone https://github.com/souvikg544/TTS_Data_Maker.git
cd TTS_Data_Maker
pip install -r requirements.txt
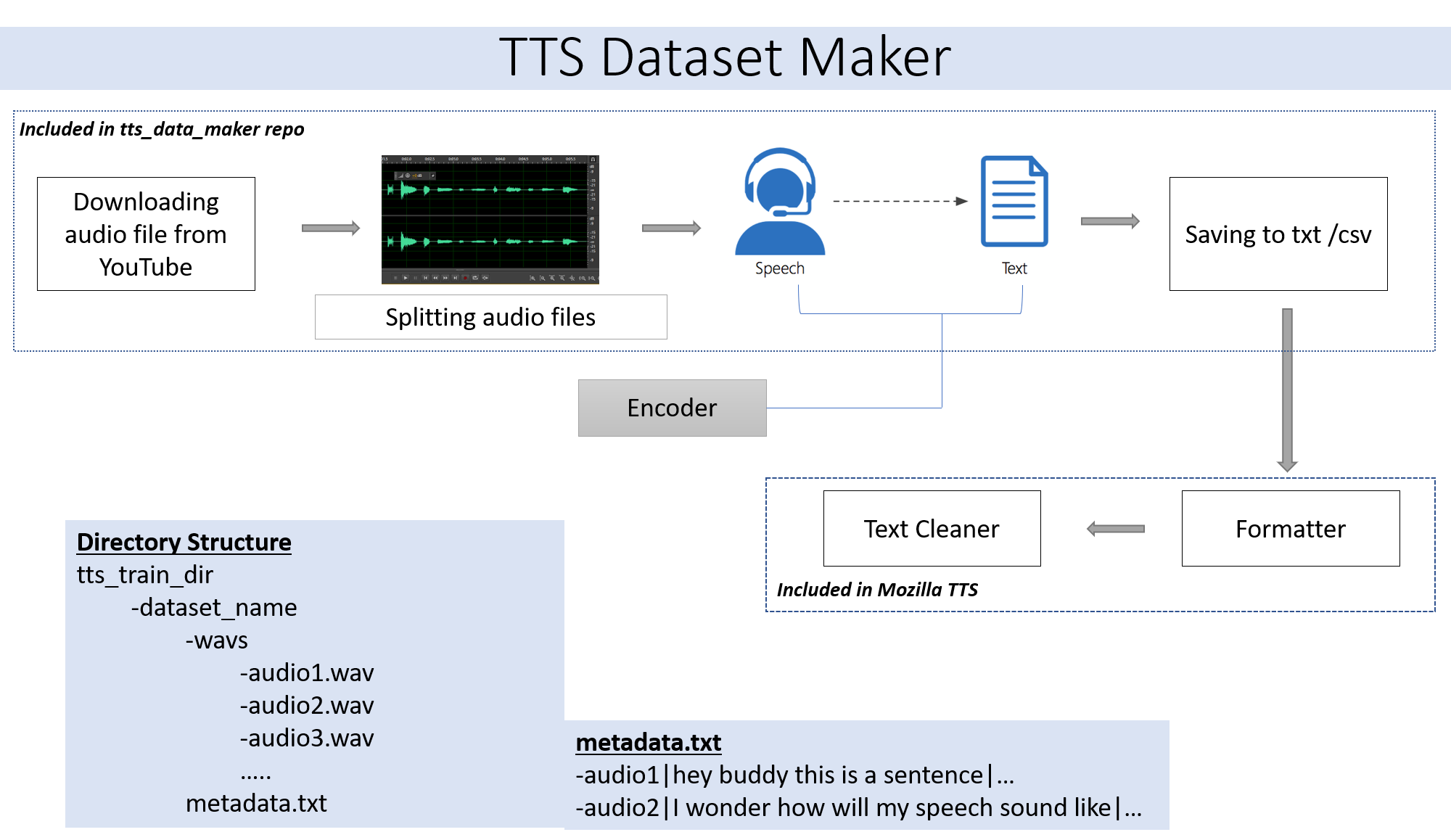
Untuk mengunduh audio dari cd video youtube ke direktori tts_data_maker dan menggunakan audio_download.py di bawah ini adalah perintah sampel untuk mengunduh video got :) .A file mp4 akan diunduh di direktori Main_Audio. Diperlukan untuk memberikan nama video_link dan speaker/video sebagai argumen untuk file Python di bawah ini.
python audio_download.py --video_link https://www.youtube.com/watch?v=-B8IkMj6d1E --speaker_name got
Untuk membagi audio yang diunduh menjadi bagian -bagian yang lebih kecil, gunakan file extract_segment.py dari repositori.
from extract_segment import SplitWavAudioMubin
download_folder="main_audio" #folder in which audio file is stored
video_filename="got.mp4" # Filename of the audio
output_folder="/content/sample_tts_dataset/wavs" #Output folder that will have segments of audio
duration=20 # Duration of each split in seconds
spliter=SplitWavAudioMubin(download_folder,video_filename,output_folder)
spliter.multiple_split(duration)
Untuk ucapan audio, kami akan memilih banyak teks ke mesin ucapan termasuk Google dan IBM. Jalankan cuplikan kode di bawah ini untuk mengekstrak teks dari cuplikan audio.
from extract_text import text_extraction
path_to_audio_split="/content/sample_tts_dataset/wavs" # As the name suggests use the same folder as output folder before
output_folder="/content/sample_tts_dataset" # Output folder having the text file
output_file= "metadata.txt" # Name of the text file.
et=text_extraction(path_to_audio_split)
et.extract(output_folder,output_file)
Dataset terakhir akan memiliki folder metadata.txt dan audio_split yang memiliki semua file audio seperti 1.wav, 2.wav, 3.wav dan segera file metadata.txt akan terlihat seperti ini
metadata.txt-
audio1|Hey how are you
audio2|I hope you are fine
audio3|Lets meet at dinner
Folder WAV yang berisi semua file audio akan terlihat seperti ini
wav
-audio1.wav
-audio2.wav
-audio3.wav
Pada akhirnya, kita harus memiliki struktur folder berikut:
/MyTTSDataset
|
| -> metadata.txt
| -> /wavs
| -> audio1.wav
| -> audio2.wav
| ...
Menerapkan dari Github Readmes selalu menyebalkan. Untuk membuat segalanya lebih mudah, seluruh proses telah diimplementasikan di Google Collab -
Pembuatan dataset harus diikuti dengan membuat model menggunakan TTS. Detail yang sama dapat ditemukan dari buku catatan ini -
Harap abaikan jika berjalan di collab atau cloud.
Modul PyDub yang digunakan secara luas dalam repositori ini menggunakan FFMPEG untuk memproses file WAV. Oleh karena itu jika berjalan pada mesin lokal, ia membutuhkan FFMPEG untuk diunduh dan folder bin harus ditambahkan ke jalur.
Tautan - https://ffmpeg.org/download.html
Unduh dari bagian Get Packages & Executable Files pada tautan di atas.


