silero models
v0.4.1

Silero模型:预训练的企业级STT / TTS模型和基准。
Enterprise级STT使清爽的简单(认真地,请参阅基准)。我们提供的质量与Google的STT相当(有时甚至更好),而且我们不是Google。
作为奖励:
另外,我们发布了满足以下标准的TTS模型:
另外,我们发表了一个文本校正和资本化模型,该模型:
您基本上可以在3种口味中使用我们的型号:
torch.hub.load() ;pip install silero ,然后import silero ;PIP和Pytorch Hub按需下载型号。如果需要缓存,请手动或通过调用必要的模型(将下载到缓存文件夹)进行操作。请参阅这些文档以获取更多信息。
Pytorch集线器和PIP软件包基于相同的代码。所有torch.hub.load示例都可以通过此基本更改与PIP软件包一起使用:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )所有提供的模型均在模型文件中列出。任何元数据和较新版本都将在此处添加。
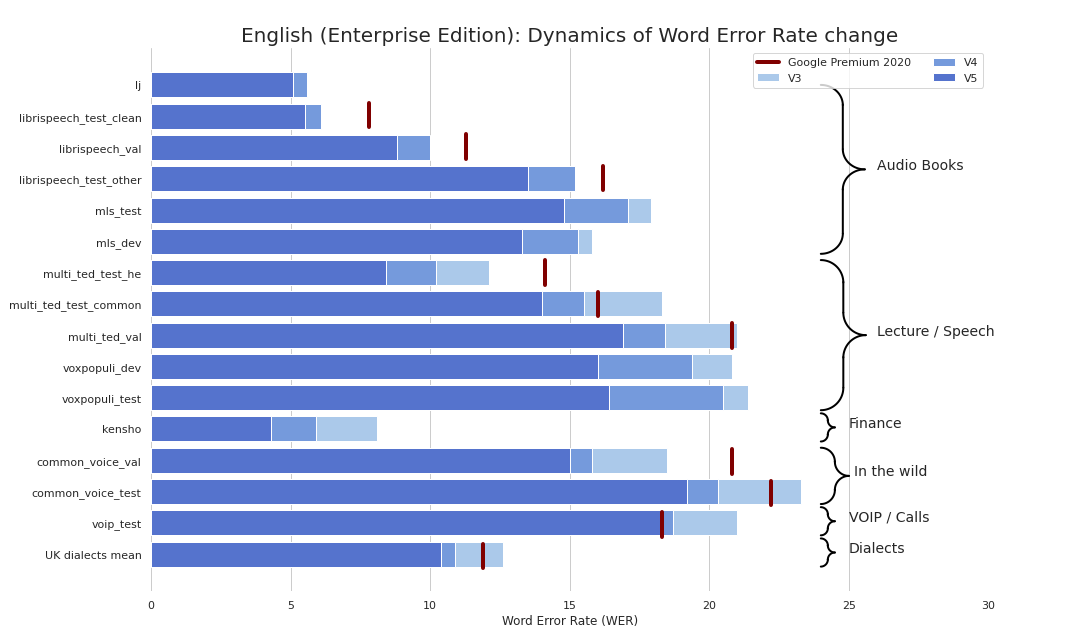
目前,我们提供以下检查点:
| Pytorch | onnx | 量化 | 质量 | COLAB | |
|---|---|---|---|---|---|
英语( en_v6 ) | ✔️ | ✔️ | ✔️ | 关联 | |
英语( en_v5 ) | ✔️ | ✔️ | ✔️ | 关联 | |
德语( de_v4 ) | ✔️ | ✔️ | ⌛ | 关联 | |
英语( en_v3 ) | ✔️ | ✔️ | ✔️ | 关联 | |
德语( de_v3 ) | ✔️ | ⌛ | ⌛ | 关联 | |
德语( de_v1 ) | ✔️ | ✔️ | ⌛ | 关联 | |
西班牙语( es_v1 ) | ✔️ | ✔️ | ⌛ | 关联 | |
乌克兰( ua_v3 ) | ✔️ | ✔️ | ✔️ | N/A。 |
型号的口味:
| 吉特 | 吉特 | 吉特 | 吉特 | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| XSMALL | 小的 | 大的 | Xlarge | XSMALL | 小的 | XSMALL | 小的 | 大的 | Xlarge | |
英语en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
英语en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
英语en_v4_0 | ✔️ | ✔️ | ||||||||
英语en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
德国de_v4 | ✔️ | ✔️ | ||||||||
德国de_v3 | ✔️ | |||||||||
德国de_v1 | ✔️ | ✔️ | ||||||||
西班牙es_v1 | ✔️ | ✔️ | ||||||||
乌克兰ua_v3 | ✔️ | ✔️ | ✔️ |
torch ,1.8+(用于克隆仓库中的tensorflow和onnx示例),打破了以上1.6的版本的更改torchaudio ,最新版本绑定到Pytorch应该只能工作omegaconf ,最新应该只能工作onnx ,最新应该只能工作onnxruntime ,最新应该只能工作tensorflow ,最新应该只能使用tensorflow_hub ,最新应该只能工作有关下面的每个示例的详细信息,请参阅提供的COLAB。所有示例都可以维持使用最新的已安装库的主要包装版本。
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))我们的模型将运行可以导入ONNX模型或支持ONNX运行时的任何地方。
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )SavedModel示例
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))所有提供的模型均在模型文件中列出。任何元数据和较新版本都将在此处添加。
V4模型支持SSML。另请参见COLAB示例以获取主要SSML标签。
| ID | 演讲者 | 自动压力 | 语言 | Sr | COLAB |
|---|---|---|---|---|---|
v4_ru | aidar kseniya baya xenia eugene random | 是的 | ru (俄语) | 8000 24000 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | 不 | cyrillic (Avar,Tatar,Kalmyk,...) | 8000 24000 48000 | |
v4_ua | mykyta , random | 不 | ua (乌克兰人) | 8000 24000 48000 | |
v4_uz | dilnavoz | 不 | uz (乌兹别克) | 8000 24000 48000 | |
v4_indic | hindi_male , hindi_female ,..., random | 不 | indic (印地语,泰卢固语,...) | 8000 24000 48000 |
V3模型支持SSML。另请参见COLAB示例以获取主要SSML标签。
| ID | 演讲者 | 自动压力 | 语言 | Sr | COLAB |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 ,..., en_117 , random | 不 | en (英语) | 8000 24000 48000 | |
v3_en_indic | tamil_female ,..., assamese_male , random | 不 | en (英语) | 8000 24000 48000 | |
v3_de | eva_k ,..., karlsson , random | 不 | de (德语) | 8000 24000 48000 | |
v3_es | es_0 , es_1 , es_2 , random | 不 | es (西班牙) | 8000 24000 48000 | |
v3_fr | fr_0 ,..., fr_5 , random | 不 | fr (法语) | 8000 24000 48000 | |
v3_indic | hindi_male , hindi_female ,..., random | 不 | indic (印地语,泰卢固语,...) | 8000 24000 48000 |
COLAB示例的基本依赖性:
torch ,1.10+;torchaudio ,最新版本绑定到Pytorch(仅是因为模型与STT一起托管,而不是工作需要);omegaconf ,最新的(如果您不加载所有配置,也可以删除); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )查看我们的TTS Wiki页面。
支持的tokenset: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| 扬声器_ID | 语言 | 性别 |
|---|---|---|
| B_AVA | 阿瓦尔 | f |
| B_BASHKIR | 巴什基 | m |
| b_bulb | 保加利亚语 | m |
| b_bulc | 保加利亚语 | m |
| B_che | 车臣 | m |
| B_CV | chuvash | m |
| CV_EKATERINA | chuvash | f |
| B_MYV | Erzya | m |
| b_kalmyk | 卡尔米克 | m |
| b_krc | 卡拉切 - 巴尔卡 | m |
| kz_m1 | 哈萨克 | m |
| kz_m2 | 哈萨克 | m |
| kz_f3 | 哈萨克 | f |
| kz_f1 | 哈萨克 | f |
| kz_f2 | 哈萨克 | f |
| B_KJH | 卡卡斯 | f |
| B_KPV | Komi-Ziryan | m |
| B_lez | 莱兹格安 | m |
| B_MHR | 玛丽 | f |
| B_MRJ | 玛丽高 | m |
| b_nog | Nogai | f |
| 老板 | 胡说八道 | m |
| B_RU | 俄语 | m |
| B_TAT | 塔塔尔 | m |
| marat_tt | 塔塔尔 | m |
| B_TYV | 图维尼亚人 | m |
| B_UDM | Udmurt | m |
| B_UZB | 乌兹别克 | m |
| B_SAH | yakut | m |
| kalmyk_erdni | 卡尔米克 | m |
| kalmyk_delghir | 卡尔米克 | f |
(!!!!)使用aksharamukha将所有输入句子都被roman romantim to ISO格式。 hindi的一个例子:
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| 语言 | 演讲者 | 罗马化功能 |
|---|---|---|
| 印地语 | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| 马拉雅拉姆语 | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| 曼尼普里 | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| 孟加拉 | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| 拉贾斯坦 | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| 泰米尔人 | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| 泰卢固语 | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| 古吉拉特语 | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| 卡纳达语 | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| 语言 | 量化 | 质量 | COLAB |
|---|---|---|---|
| 'en','de','ru','es' | ✔️ | 关联 |
COLAB示例的基本依赖性:
torch ,1.9+;pyyaml ,但它安装了火炬本身 import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Denoise模型试图减少背景噪声以及各种伪像,例如混响,剪裁,高/低通滤波器等,同时试图保存和/或增强语音。他们还试图提高音频质量并提高输入的采样率高达48kHz。
所有提供的模型均在模型文件中列出。
| 模型 | 吉特 | 实际输入SR | 输入SR | 输出SR | COLAB |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 |
COLAB示例的基本依赖性:
torch ,2.0+;torchaudio ,最新版本绑定到Pytorch应该有效;omegaconf ,最新的(如果您不加载所有配置,也可以删除)。 import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )还可以查看我们的Wiki。
请参阅这些Wiki部分:
请参考。
尝试我们的模型,创建问题,加入我们的聊天,给我们发送电子邮件,并阅读最新消息。
有关相关信息,请参考我们的Wiki以及许可和层页页面,并给我们发送电子邮件。
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
vad:
文本增强:
stt
TTS:
vad:
文本增强:
请使用“赞助商”按钮。


