silero models
v0.4.1

نماذج سيليرو: نماذج ومعايير STT / TTS التي تم تدريبها مسبقًا.
جعلت STT من الدرجة STT بسيطة منعشة (على محمل الجد ، انظر المعايير). نحن نقدم جودة مماثلة لـ STT من Google (وأحيانًا أفضل) ونحن لسنا Google.
كمكافأة:
كما نشرنا نماذج TTS التي تلبي المعايير التالية:
لقد نشرنا أيضًا نموذجًا لإعادة التأكيد على النص وإعادة الرسملة:
يمكنك استخدام نماذجنا في 3 نكهات:
torch.hub.load() ؛pip install silero ثم import silero ؛يتم تنزيل النماذج عند الطلب بواسطة PIP و Pytorch Hub. إذا كنت بحاجة إلى التخزين المؤقت ، فقم بذلك يدويًا أو عبر استدعاء نموذج ضروري مرة واحدة (سيتم تنزيله إلى مجلد ذاكرة التخزين المؤقت). يرجى الاطلاع على هذه المستندات لمزيد من المعلومات.
تعتمد Pytorch Hub و PIP على نفس الرمز. يمكن استخدام جميع أمثلة torch.hub.load مع حزمة PIP عبر هذا التغيير الأساسي:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )يتم سرد جميع النماذج المقدمة في ملف models.yml. سيتم إضافة أي بيانات تعريف وإصدارات أحدث.
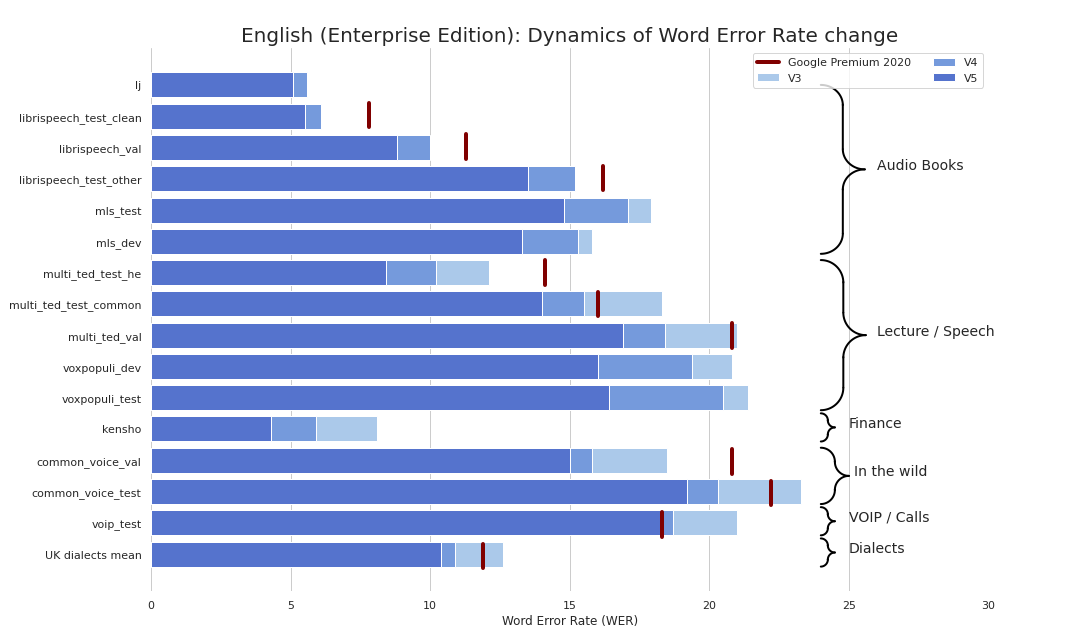
حاليا نقدم نقاط التفتيش التالية:
| Pytorch | onnx | الكمية | جودة | كولاب | |
|---|---|---|---|---|---|
اللغة الإنجليزية ( en_v6 ) | ✔ | ✔ | ✔ | وصلة | |
اللغة الإنجليزية ( en_v5 ) | ✔ | ✔ | ✔ | وصلة | |
الألمانية ( de_v4 ) | ✔ | ✔ | ⌛ | وصلة | |
اللغة الإنجليزية ( en_v3 ) | ✔ | ✔ | ✔ | وصلة | |
الألمانية ( de_v3 ) | ✔ | ⌛ | ⌛ | وصلة | |
الألمانية ( de_v1 ) | ✔ | ✔ | ⌛ | وصلة | |
الإسبانية ( es_v1 ) | ✔ | ✔ | ⌛ | وصلة | |
الأوكرانية ( ua_v3 ) | ✔ | ✔ | ✔ | ن/أ |
النكهات النموذجية:
| جيت | جيت | جيت | جيت | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | صغير | كبير | xlarge | xsmall | صغير | xsmall | صغير | كبير | xlarge | |
الإنجليزية en_v6 | ✔ | ✔ | ✔ | ✔ | ✔ | |||||
الإنجليزية en_v5 | ✔ | ✔ | ✔ | ✔ | ✔ | |||||
الإنجليزية en_v4_0 | ✔ | ✔ | ||||||||
الإنجليزية en_v3 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
الألمانية de_v4 | ✔ | ✔ | ||||||||
الألمانية de_v3 | ✔ | |||||||||
الألمانية de_v1 | ✔ | ✔ | ||||||||
الإسبانية es_v1 | ✔ | ✔ | ||||||||
الأوكرانية ua_v3 | ✔ | ✔ | ✔ |
torch ، 1.8+ (يستخدم لاستنساخ الريبو في أمثلة TensorFlow و ONNX) ، كسر التغييرات للإصدارات الأقدم من 1.6torchaudio ، أحدث إصدار ملزم بـ Pytorch يجب أن يعمل فقطomegaconf ، الأحدث يجب أن يعمل فقطonnx ، الأحدث يجب أن يعمل فقطonnxruntime ، الأحدث يجب أن يعمل فقطtensorflow ، الأحدث يجب أن يعمل فقطtensorflow_hub ، الأحدث يجب أن يعمل فقطيرجى الاطلاع على كولاب المقدمة للحصول على تفاصيل لكل مثال أدناه. يتم الحفاظ على جميع الأمثلة للعمل مع أحدث الإصدارات المعبأة الرئيسية من المكتبات المثبتة.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))سيتم تشغيل نموذجنا في أي مكان يمكنه استيراد نموذج ONNX أو يدعم وقت تشغيل ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )مثال SaveModel
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))يتم سرد جميع النماذج المقدمة في ملف models.yml. سيتم إضافة أي بيانات تعريف وإصدارات أحدث.
نماذج V4 تدعم SSML. انظر أيضًا أمثلة كولاب لاستخدام علامة SSML الرئيسية.
| بطاقة تعريف | مكبرات صوت | التوتر التلقائي | لغة | ريال | كولاب |
|---|---|---|---|---|---|
v4_ru | aidar ، baya ، kseniya ، xenia ، eugene ، random | نعم | ru (الروسية) | 8000 ، 24000 ، 48000 | |
v4_cyrillic | b_ava ، marat_tt ، kalmyk_erdni ... | لا | cyrillic (Avar ، Tatar ، Kalmyk ، ...) | 8000 ، 24000 ، 48000 | |
v4_ua | mykyta ، random | لا | ua (الأوكرانية) | 8000 ، 24000 ، 48000 | |
v4_uz | dilnavoz | لا | uz (Uzbek) | 8000 ، 24000 ، 48000 | |
v4_indic | hindi_male ، hindi_female ، ... ، random | لا | indic (الهندية ، التيلجو ، ...) | 8000 ، 24000 ، 48000 |
نماذج V3 تدعم SSML. انظر أيضًا أمثلة كولاب لاستخدام علامة SSML الرئيسية.
| بطاقة تعريف | مكبرات صوت | التوتر التلقائي | لغة | ريال | كولاب |
|---|---|---|---|---|---|
v3_en | en_0 ، en_1 ، ... ، en_117 ، random | لا | en (الإنجليزية) | 8000 ، 24000 ، 48000 | |
v3_en_indic | tamil_female ، ... ، assamese_male ، random | لا | en (الإنجليزية) | 8000 ، 24000 ، 48000 | |
v3_de | eva_k ، ... ، karlsson ، random | لا | de (الألمانية) | 8000 ، 24000 ، 48000 | |
v3_es | es_0 ، es_1 ، es_2 ، random | لا | es (الإسبانية) | 8000 ، 24000 ، 48000 | |
v3_fr | fr_0 ، ... ، fr_5 ، random | لا | fr (الفرنسية) | 8000 ، 24000 ، 48000 | |
v3_indic | hindi_male ، hindi_female ، ... ، random | لا | indic (الهندية ، التيلجو ، ...) | 8000 ، 24000 ، 48000 |
التبعيات الأساسية لأمثلة كولاب:
torch ، 1.10+ لنماذج V3/ 2.0+ لنماذج V4 ؛torchaudio ، أحدث إصدار ملزم بـ Pytorch (مطلوب فقط لأن النماذج يتم استضافتها مع STT ، غير مطلوبة للعمل) ؛omegaconf ، الأحدث (يمكن إزالتها أيضًا ، إذا لم تقم بتحميل جميع التكوينات) ؛ # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )تحقق من صفحة TTS Wiki الخاصة بنا.
!,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ المدعوم:!
| مكبر الصوت | لغة | جنس |
|---|---|---|
| b_ava | أفار | و |
| b_bashkir | باشكر | م |
| b_bulb | البلغارية | م |
| b_bulc | البلغارية | م |
| b_che | الشيشان | م |
| B_CV | تشوفاش | م |
| cv_ekaterina | تشوفاش | و |
| b_myv | إيرزيا | م |
| b_kalmyk | Kalmyk | م |
| B_KRC | كراتشاي-بيلار | م |
| KZ_M1 | كازاخاخية | م |
| KZ_M2 | كازاخاخية | م |
| KZ_F3 | كازاخاخية | و |
| KZ_F1 | كازاخاخية | و |
| KZ_F2 | كازاخاخية | و |
| B_KJH | خاكاس | و |
| B_KPV | كومي زيريان | م |
| b_lez | ليزغيان | م |
| B_MHR | ماري | و |
| b_mrj | ماري هاي | م |
| b_nog | نوجاي | و |
| رئيس | العظم | م |
| B_RU | الروسية | م |
| b_tat | التتار | م |
| marat_tt | التتار | م |
| b_tyv | توفينيان | م |
| b_udm | udmurt | م |
| b_uzb | أوزبك | م |
| B_SAH | ياكوت | م |
| kalmyk_erdni | Kalmyk | م |
| kalmyk_delghir | Kalmyk | و |
(!!!) يجب أن تُضطر جميع جمل المدخلات إلى تنسيق ISO باستخدام aksharamukha . مثال على hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| لغة | مكبرات صوت | وظيفة الرومانية |
|---|---|---|
| الهندية | hindi_female ، hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| الملايالام | malayalam_female ، malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| مانيبوري | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| البنغالية | bengali_female ، bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| راجاستاني | rajasthani_female ، rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| التاميل | tamil_female ، tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| التيلجو | telugu_female ، telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| غوجاراتية | gujarati_female ، gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| الكانادا | kannada_female ، kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| اللغات | الكمية | جودة | كولاب |
|---|---|---|---|
| 'en' ، 'de' ، 'ru' ، 'es' | ✔ | وصلة |
التبعيات الأساسية لأمثلة كولاب:
torch ، 1.9+ ؛pyyaml ، ولكن تم تثبيته مع Torch نفسها import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )تحاول نماذج Denoise تقليل ضوضاء الخلفية جنبًا إلى جنب مع مختلف المصنوعات اليدوية مثل تردد ، قصات ، مرشحات عالية/منخفضة ، وما إلى ذلك ، أثناء محاولة الحفاظ على الكلام و/أو تعزيزه. كما يحاولون تعزيز جودة الصوت وزيادة معدل أخذ العينات من المدخلات حتى 48 كيلو هرتز.
يتم سرد جميع النماذج المقدمة في ملف models.yml.
| نموذج | جيت | إدخال حقيقي sr | المدخلات sr | الإخراج sr | كولاب |
|---|---|---|---|---|---|
small_slow | ✔ | 8000 ، 16000 ، 24000 ، 44100 ، 48000 | 24000 | 48000 | |
large_fast | ✔ | 8000 ، 16000 ، 24000 ، 44100 ، 48000 | 24000 | 48000 | |
small_fast | ✔ | 8000 ، 16000 ، 24000 ، 44100 ، 48000 | 24000 | 48000 |
التبعيات الأساسية لأمثلة كولاب:
torch ، 2.0+ ؛torchaudio ، أحدث إصدار ملزم بـ Pytorch يجب أن يعمل ؛omegaconf ، الأحدث (يمكن إزالتها أيضًا ، إذا لم تقم بتحميل جميع التكوينات). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )تحقق أيضا من الويكي لدينا.
يرجى الرجوع إلى أقسام الويكي هذه:
يرجى الرجوع هنا.
جرب نماذجنا ، وإنشاء مشكلة ، وانضم إلى الدردشة ، ومراسلنا عبر البريد الإلكتروني ، وقراءة آخر الأخبار.
يرجى الرجوع إلى صفحة Wiki وصفحة الترخيص والطائرات للحصول على المعلومات ذات الصلة ، وإرسال بريد إلكتروني إلينا.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
فاد:
تحسين النص:
Stt
TTS:
فاد:
تحسين النص:
الرجاء استخدام زر "الراعي".


