silero models
v0.4.1

Silero Models: предварительно обученные модели STT / TTS предприятия и контрольные показатели.
STT предпринимательства стала освежающе простым (серьезно, см. Бесчмамы). Мы предоставляем качество, сравнимое с STT Google (а иногда и лучше), и мы не Google.
В качестве бонуса:
Также мы опубликовали модели TTS, которые удовлетворяют следующие критерии:
Кроме того, мы опубликовали модель для дать текст и рекапитализация, которая:
Вы можете использовать наши модели в 3 вкусах:
torch.hub.load() ;pip install silero , а затем import silero ;Модели загружаются по требованию как PIP, так и Pytorch Hub. Если вам нужно кэширование, сделайте это вручную или через вызов необходимой модели один раз (она будет загружена в папку кеша). Пожалуйста, смотрите эти документы для получения дополнительной информации.
Hub Pytorch и пакет PIP основаны на том же коде. Все примеры torch.hub.load можно использовать с пакетом PIP через это базовое изменение:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Все предоставленные модели перечислены в файле Models.yml. Любые метаданные и новые версии будут добавлены туда.
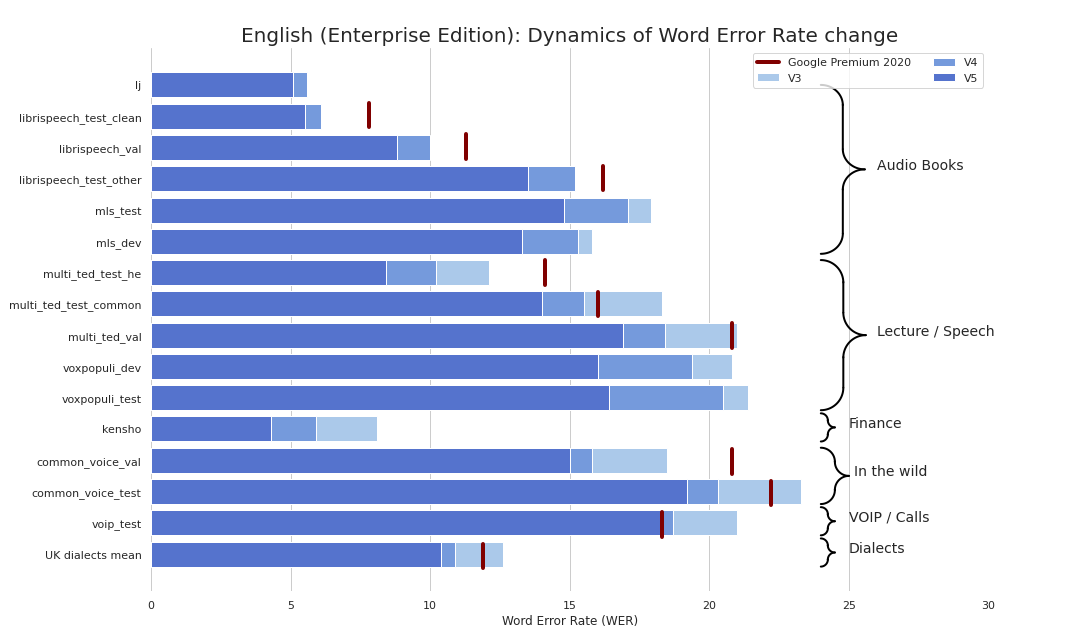
В настоящее время мы предоставляем следующие контрольно -пропускные пункты:
| Пирог | Onnx | Квантование | Качество | Колаба | |
|---|---|---|---|---|---|
Английский ( en_v6 ) | ✔ | ✔ | ✔ | связь | |
Английский ( en_v5 ) | ✔ | ✔ | ✔ | связь | |
Немецкий ( de_v4 ) | ✔ | ✔ | ⌛ | связь | |
Английский ( en_v3 ) | ✔ | ✔ | ✔ | связь | |
Немецкий ( de_v3 ) | ✔ | ⌛ | ⌛ | связь | |
Немецкий ( de_v1 ) | ✔ | ✔ | ⌛ | связь | |
Испанский ( es_v1 ) | ✔ | ✔ | ⌛ | связь | |
Украинский ( ua_v3 ) | ✔ | ✔ | ✔ | N/a |
Модельные ароматы:
| джит | джит | джит | джит | jit_q | jit_q | Onnx | Onnx | Onnx | Onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | маленький | большой | xlarge | xsmall | маленький | xsmall | маленький | большой | xlarge | |
Английский en_v6 | ✔ | ✔ | ✔ | ✔ | ✔ | |||||
Английский en_v5 | ✔ | ✔ | ✔ | ✔ | ✔ | |||||
Английский en_v4_0 | ✔ | ✔ | ||||||||
Английский en_v3 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
Немецкий de_v4 | ✔ | ✔ | ||||||||
Немецкий de_v3 | ✔ | |||||||||
Немецкий de_v1 | ✔ | ✔ | ||||||||
Испанский es_v1 | ✔ | ✔ | ||||||||
Украинский ua_v3 | ✔ | ✔ | ✔ |
torch , 1,8+ (используется для клонирования репо в примерах Tensorflow и Onnx), нарушение изменений для версий старше 1,6torchaudio , последняя версия, связанная с Pytorch, должна просто работатьomegaconf , последний должен просто работатьonnx , последнее должно просто работатьonnxruntime , последнее должно просто работатьtensorflow , последний должен просто работатьtensorflow_hub , последний должен просто работатьПожалуйста, смотрите предоставленную Colab для получения подробной информации для каждого примера ниже. Все примеры поддерживаются для работы с последними основными упакованными версиями установленных библиотек.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Наша модель будет работать в любом месте, что может импортировать модель ONNX или которая поддерживает время выполнения ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )SavedModel Пример
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Все предоставленные модели перечислены в файле Models.yml. Любые метаданные и новые версии будут добавлены туда.
Модели V4 поддерживают SSML. Также см. Примеры Colab для основного использования тегов SSML.
| ИДЕНТИФИКАТОР | Докладчики | Авто-стресс | Язык | Старший | Колаба |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | да | ru (русский) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | нет | cyrillic (авар, Татар, Калмик, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | нет | ua (украинская) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | нет | uz (Узбек) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | нет | indic (хинди, телугу, ...) | 8000 , 24000 , 48000 |
Модели V3 поддерживают SSML. Также см. Примеры Colab для основного использования тегов SSML.
| ИДЕНТИФИКАТОР | Докладчики | Авто-стресс | Язык | Старший | Колаба |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | нет | en (английский) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | нет | en (английский) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | нет | de (немецкий) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | нет | es (испанский) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | нет | fr (французский) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | нет | indic (хинди, телугу, ...) | 8000 , 24000 , 48000 |
Основные зависимости для примеров колаба:
torch , 1,10+ для моделей V3/ 2.0+ для моделей V4;torchaudio , последняя версия, связанная с Pytorch, должна работать (требуется только потому, что модели размещены вместе с STT, не требуемая для работы);omegaconf , последний (можно также удалить, если вы не загружаете все конфигурации); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Проверьте нашу страницу вики TTS.
Поддерживается Tokenset: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ ӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_id | Язык | Пол |
|---|---|---|
| b_ava | Авар | Фон |
| b_bashkir | Башкир | М |
| b_bulb | болгарский | М |
| b_bulc | болгарский | М |
| b_che | Чеченский | М |
| b_cv | Чуваш | М |
| cv_ekaterina | Чуваш | Фон |
| b_myv | Эрзи | М |
| b_kalmyk | Калмак | М |
| b_krc | Карачай-Балкар | М |
| kz_m1 | Казах | М |
| kz_m2 | Казах | М |
| kz_f3 | Казах | Фон |
| kz_f1 | Казах | Фон |
| kz_f2 | Казах | Фон |
| b_kjh | Хакас | Фон |
| b_kpv | Komi-Ziryan | М |
| b_lez | Лезхьян | М |
| b_mhr | Мари | Фон |
| b_mrj | Мари Хай | М |
| b_nog | Ногай | Фон |
| b_oss | Осетичный | М |
| b_ru | Русский | М |
| b_tat | Татар | М |
| marat_tt | Татар | М |
| b_tyv | Тувиниан | М |
| b_udm | Удмурт | М |
| b_uzb | Узбек | М |
| B_SAH | Якут | М |
| Kalmyk_erdni | Калмак | М |
| Kalmyk_delghir | Калмак | Фон |
(!!!) Все входные предложения должны быть романизированы в формате ISO с использованием aksharamukha . Пример для hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Язык | Докладчики | Функция романизации |
|---|---|---|
| хинди | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| малаялам | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| Манипури | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| бенгальский | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Раджастхани | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| тамильский | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| телугу | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| Гуджарати | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| Каннада | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Языки | Квантование | Качество | Колаба |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔ | связь |
Основные зависимости для примеров колаба:
torch , 1,9+;pyyaml , но он установлен с самим факелом import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Модели Denoise пытаются уменьшить фоновый шум вместе с различными артефактами, такими как реверберация, отсечение, фильтры с высоким/низким уровнем и т. Д., Пытаясь сохранить и/или улучшить речь. Они также пытаются повысить качество звука и увеличить скорость отбора проб до 48 кГц.
Все предоставленные модели перечислены в файле Models.yml.
| Модель | Джит | Реальный вход SR | Вход SR | Вывод SR | Колаба |
|---|---|---|---|---|---|
small_slow | ✔ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Основные зависимости для примеров колаба:
torch , 2.0+;torchaudio , последняя версия, связанная с Pytorch, должна работать;omegaconf , последний (можно также удалить, если вы не загружаете все конфигурации). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Также проверьте нашу вики.
Пожалуйста, обратитесь к этим разделам вики:
Пожалуйста, обратитесь здесь.
Попробуйте наши модели, создайте проблему, присоединяйтесь к нашему чату, напишите нам и прочитайте последние новости.
Пожалуйста, обратитесь на нашу страницу Wiki и Licensing and Tiers для соответствующей информации и напишите нам.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}Stt:
TTS:
Вад:
Улучшение текста:
Stt
TTS:
Вад:
Улучшение текста:
Пожалуйста, используйте кнопку «Спонсор».


