silero models
v0.4.1

Modelos Silero: modelos STT / TTS de grado empresarial previamente entrenado y puntos de referencia.
El STT de grado empresarial hizo refrescantemente simple (en serio, ver puntos de referencia). Proporcionamos una calidad comparable al STT (y a veces incluso mejor) de Google y no somos Google.
Como un bono:
También hemos publicado modelos TTS que satisfacen los siguientes criterios:
También hemos publicado un modelo para la recapitución y recapitalización de texto que:
Básicamente puede usar nuestros modelos en 3 sabores:
torch.hub.load() ;pip install silero y luego import silero ;Los modelos se descargan a pedido tanto por PIP como por Pytorch Hub. Si necesita almacenamiento en caché, hágalo manualmente o invocando un modelo necesario una vez (se descargará en una carpeta de caché). Consulte estos documentos para obtener más información.
Pytorch Hub y PIP se basan en el mismo código. Todos los ejemplos de torch.hub.load se pueden usar con el paquete PIP a través de este cambio básico:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Todos los modelos proporcionados se enumeran en el archivo Models.yml. Allí se agregarán cualquier metadato y versiones más nuevas.
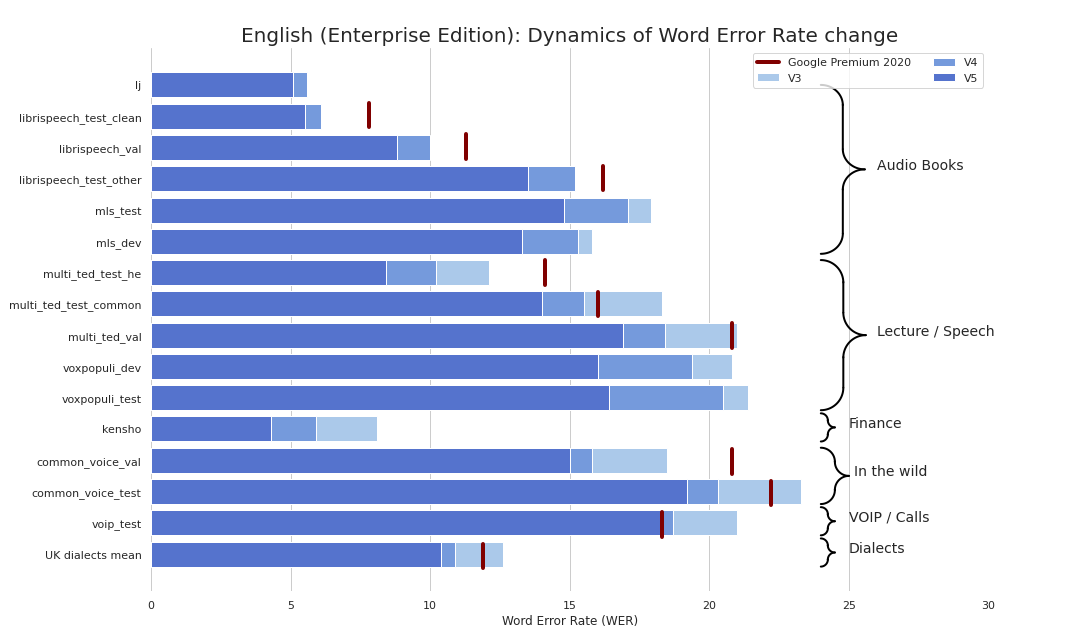
Actualmente proporcionamos los siguientes puntos de control:
| Pytorch | ONNX | Cuantificación | Calidad | Colab | |
|---|---|---|---|---|---|
Inglés ( en_v6 ) | ✔️ | ✔️ | ✔️ | enlace | |
Inglés ( en_v5 ) | ✔️ | ✔️ | ✔️ | enlace | |
Alemán ( de_v4 ) | ✔️ | ✔️ | ⌛ | enlace | |
Inglés ( en_v3 ) | ✔️ | ✔️ | ✔️ | enlace | |
Alemán ( de_v3 ) | ✔️ | ⌛ | ⌛ | enlace | |
Alemán ( de_v1 ) | ✔️ | ✔️ | ⌛ | enlace | |
Español ( es_v1 ) | ✔️ | ✔️ | ⌛ | enlace | |
Ucraniano ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N / A |
Sabores de modelo:
| jit | jit | jit | jit | jit_q | jit_q | ONNX | ONNX | ONNX | ONNX | |
|---|---|---|---|---|---|---|---|---|---|---|
| xmall | pequeño | grande | xlarge | xmall | pequeño | xmall | pequeño | grande | xlarge | |
Inglés en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Inglés en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Inglés en_v4_0 | ✔️ | ✔️ | ||||||||
Inglés en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
Alemán de_v4 | ✔️ | ✔️ | ||||||||
Alemán de_v3 | ✔️ | |||||||||
Alemán de_v1 | ✔️ | ✔️ | ||||||||
Español es_v1 | ✔️ | ✔️ | ||||||||
Ucraniano ua_v3 | ✔️ | ✔️ | ✔️ |
torch , 1.8+ (se usa para clonar el repositorio en ejemplos TensorFlow y ONNX), rompiendo cambios para versiones mayores de 1.6torchaudio , la última versión vinculada a Pytorch debería funcionar soloomegaconf , lo último debería funcionaronnx , lo último debería funcionar soloonnxruntime , lo último debería funcionar solotensorflow , lo último debería funcionartensorflow_hub , lo último solo debería funcionarConsulte el Colab proporcionado para obtener detalles para cada ejemplo a continuación. Todos los ejemplos se mantienen para trabajar con las últimas versiones empaquetadas principales de las bibliotecas instaladas.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Nuestro modelo se ejecutará en cualquier lugar que pueda importar el modelo ONNX o que admita el tiempo de ejecución de ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )SavedModel Ejemplo
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Todos los modelos proporcionados se enumeran en el archivo Models.yml. Allí se agregarán cualquier metadato y versiones más nuevas.
Los modelos V4 admiten SSML. Vea también ejemplos de Colab para el uso principal de la etiqueta SSML.
| IDENTIFICACIÓN | Altavoces | Estrés automático | Idioma | Sr | Colab |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | Sí | ru (ruso) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | No | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | No | ua (ucraniano) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | No | uz (uzbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | No | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Los modelos V3 admiten SSML. Vea también ejemplos de Colab para el uso principal de la etiqueta SSML.
| IDENTIFICACIÓN | Altavoces | Estrés automático | Idioma | Sr | Colab |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | No | en (inglés) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | No | en (inglés) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | No | de (alemán) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | No | es (español) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | No | fr (francés) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | No | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Dependencias básicas para ejemplos de colab:
torch , 1.10+ para modelos V3/ 2.0+ para modelos V4;torchaudio , la última versión unida a Pytorch debería funcionar (requerida solo porque los modelos se alojan junto con STT, no se requieren para el trabajo);omegaconf , último (también se puede eliminar, si no carga todas las configuraciones); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Echa un vistazo a nuestra página TTS Wiki.
Tokenset compatible: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Altavoz_id | Idioma | Género |
|---|---|---|
| b_ava | Avar | F |
| b_bashkir | Brashkir | METRO |
| b_bulb | búlgaro | METRO |
| b_bulc | búlgaro | METRO |
| b_che | Checheno | METRO |
| B_CV | Chuvash | METRO |
| cv_ekaterina | Chuvash | F |
| b_myv | Erzya | METRO |
| b_kalmyk | Kalmyk | METRO |
| b_krc | Karachay-balkar | METRO |
| KZ_M1 | Kazáceo | METRO |
| KZ_M2 | Kazáceo | METRO |
| KZ_F3 | Kazáceo | F |
| KZ_F1 | Kazáceo | F |
| KZ_F2 | Kazáceo | F |
| b_kjh | Caquas | F |
| B_KPV | Komi-ziryan | METRO |
| b_lez | Lezghiano | METRO |
| b_mhr | Mari | F |
| b_mrj | Mari alto | METRO |
| b_nog | Nogai | F |
| jefe | Osético | METRO |
| b_ru | ruso | METRO |
| b_tat | Tártaro | METRO |
| marat_tt | Tártaro | METRO |
| b_tyv | Tuviniano | METRO |
| b_udm | Udmurt | METRO |
| b_uzb | Uzbek | METRO |
| b_sah | Yakut | METRO |
| kalmyk_erdni | Kalmyk | METRO |
| kalmyk_delghir | Kalmyk | F |
(!!!) Todas las oraciones de entrada deben ser romanizadas para el formato ISO usando aksharamukha . Un ejemplo para hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Idioma | Altavoces | Función de romanización |
|---|---|---|
| hindi | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| malayalam | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| bengalí | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Rajasthani | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| tamil | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| telugu | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| gujarati | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| kannada | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Lenguas | Cuantificación | Calidad | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | enlace |
Dependencias básicas para ejemplos de colab:
torch , 1.9+;pyyaml , pero está instalado con la antorcha misma import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Los modelos Denoise intentan reducir el ruido de fondo junto con varios artefactos como reverberación, recorte, filtros de alto/bajo paso, etc., mientras intentan preservar y/o mejorar el habla. También intentan mejorar la calidad del audio y aumentar la tasa de muestreo de la entrada de hasta 48 kHz.
Todos los modelos proporcionados se enumeran en el archivo Models.yml.
| Modelo | Jit | Entrada real sr | Entrada sr | Salida sr | Colab |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Dependencias básicas para ejemplos de colab:
torch , 2.0+;torchaudio , la última versión vinculada a Pytorch debería funcionar;omegaconf , último (también se puede eliminar, si no carga todas las configuraciones). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )También mira nuestro wiki.
Consulte estas secciones wiki:
Consulte aquí.
Pruebe nuestros modelos, cree un problema, únase a nuestro chat, envíenos un correo electrónico y lea las últimas noticias.
Consulte nuestro wiki y la página de licencias y niveles para obtener información relevante, y envíenos un correo electrónico.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
Vad:
Mejora del texto:
Stt
TTS:
Vad:
Mejora del texto:
Utilice el botón "Patrocinador".


