silero models
v0.4.1

シレロモデル:事前に訓練されたエンタープライズグレードのSTT / TTSモデルとベンチマーク。
エンタープライズグレードのSTTはさわやかにシンプルになりました(真剣に、ベンチマークを参照)。 GoogleのSTTに匹敵する品質を提供します(さらにはさらに良いこともあります)。Googleではありません。
ボーナスとして:
また、次の基準を満たすTTSモデルを公開しました。
また、テキストの再認証と資本増強のモデルを公開しました。
基本的に3つのフレーバーでモデルを使用できます。
torch.hub.load() ;pip install sileroから、 import silero 。モデルは、PIPとPytorch Hubの両方でオンデマンドでダウンロードされます。キャッシュが必要な場合は、手動で行うか、必要なモデルを1回呼び出すことで実行します(キャッシュフォルダーにダウンロードされます)。詳細については、これらのドキュメントをご覧ください。
Pytorch HubとPIPパッケージは、同じコードに基づいています。すべてのtorch.hub.loadの例は、この基本的な変更を介してPIPパッケージで使用できます。
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )提供されたすべてのモデルは、models.ymlファイルにリストされています。そこにメタデータと新しいバージョンが追加されます。
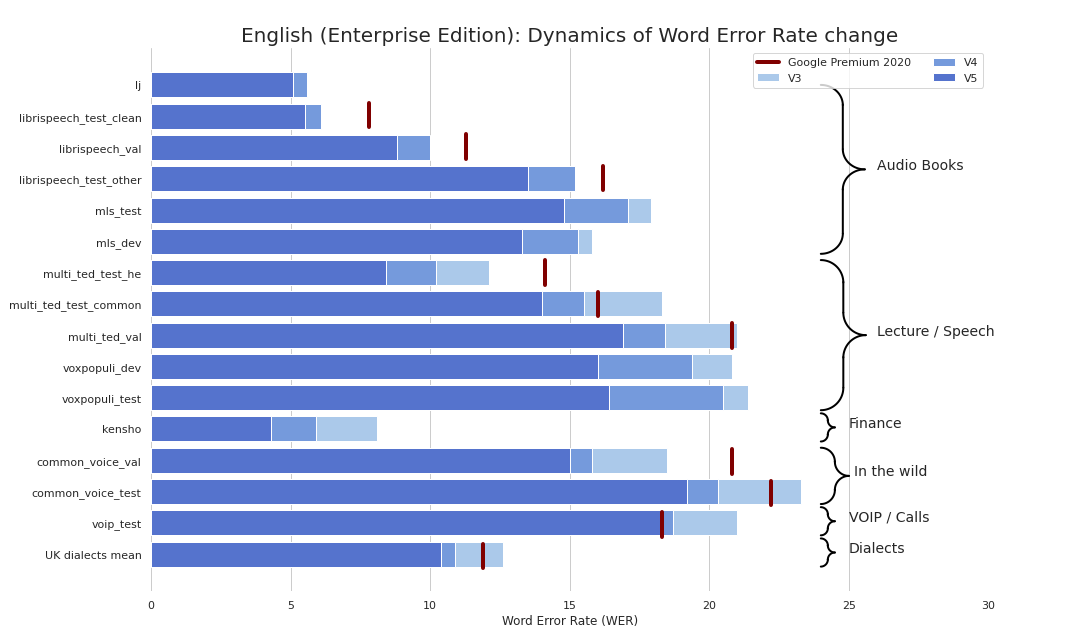
現在、次のチェックポイントを提供しています。
| Pytorch | onnx | 量子化 | 品質 | colab | |
|---|---|---|---|---|---|
英語( en_v6 ) | ✔✔️ | ✔✔️ | ✔✔️ | リンク | |
英語( en_v5 ) | ✔✔️ | ✔✔️ | ✔✔️ | リンク | |
ドイツ語( de_v4 ) | ✔✔️ | ✔✔️ | ⌛ | リンク | |
英語( en_v3 ) | ✔✔️ | ✔✔️ | ✔✔️ | リンク | |
ドイツ語( de_v3 ) | ✔✔️ | ⌛ | ⌛ | リンク | |
ドイツ語( de_v1 ) | ✔✔️ | ✔✔️ | ⌛ | リンク | |
スペイン語( es_v1 ) | ✔✔️ | ✔✔️ | ⌛ | リンク | |
ウクライナ人( ua_v3 ) | ✔✔️ | ✔✔️ | ✔✔️ | n/a |
モデルフレーバー:
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | 小さい | 大きい | Xlarge | xsmall | 小さい | xsmall | 小さい | 大きい | Xlarge | |
英語en_v6 | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | |||||
英語en_v5 | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | |||||
英語en_v4_0 | ✔✔️ | ✔✔️ | ||||||||
英語en_v3 | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ✔✔️ | ||
ドイツde_v4 | ✔✔️ | ✔✔️ | ||||||||
ドイツde_v3 | ✔✔️ | |||||||||
ドイツde_v1 | ✔✔️ | ✔✔️ | ||||||||
スペイン語es_v1 | ✔✔️ | ✔✔️ | ||||||||
ウクライナua_v3 | ✔✔️ | ✔✔️ | ✔✔️ |
torch 、1.8+(TensorflowおよびONNXの例でリポジトリをクローンするために使用)、1.6以上のバージョンの変更を破るtorchaudio 、Pytorchに縛られた最新バージョンはただ機能するはずですomegaconf 、最新のものはただ機能するはずですonnx 、最新は機能するはずですonnxruntime 、最新は機能するはずですtensorflow 、最新は機能するはずですtensorflow_hub 、最新のものはうまくいくはずです以下の例の詳細については、提供されたcolabをご覧ください。すべての例は、インストールされているライブラリの最新の主要なパッケージバージョンで動作するように維持されています。
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))私たちのモデルは、ONNXモデルをインポートできる、またはONNXランタイムをサポートできるどこでも実行されます。
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )savedmodelの例
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))提供されたすべてのモデルは、models.ymlファイルにリストされています。そこにメタデータと新しいバージョンが追加されます。
V4モデルはSSMLをサポートしています。メインSSMLタグの使用については、Colabの例も参照してください。
| id | スピーカー | オートストレス | 言語 | sr | colab |
|---|---|---|---|---|---|
v4_ru | aidar 、 baya 、 kseniya 、 xenia 、 eugene 、 random | はい | ru (ロシア語) | 8000 24000 48000 | |
v4_cyrillic | b_ava 、 marat_tt 、 kalmyk_erdni ... | いいえ | cyrillic (アバール、タタール、カルミク、...) | 8000 24000 48000 | |
v4_ua | mykyta 、 random | いいえ | ua (ウクライナ人) | 8000 24000 48000 | |
v4_uz | dilnavoz | いいえ | uz (uzbek) | 8000 24000 48000 | |
v4_indic | hindi_male 、 hindi_female 、...、 random | いいえ | indic (ヒンディー語、テルグ語、...) | 8000 24000 48000 |
V3モデルはSSMLをサポートしています。メインSSMLタグの使用については、Colabの例も参照してください。
| id | スピーカー | オートストレス | 言語 | sr | colab |
|---|---|---|---|---|---|
v3_en | en_0 、 en_1 、...、 en_117 、 random | いいえ | en (英語) | 8000 24000 48000 | |
v3_en_indic | tamil_female 、...、 assamese_male 、 random | いいえ | en (英語) | 8000 24000 48000 | |
v3_de | eva_k 、...、 karlsson 、 random | いいえ | de (ドイツ語) | 8000 24000 48000 | |
v3_es | es_0 、 es_1 、 es_2 、 random | いいえ | es (スペイン語) | 8000 24000 48000 | |
v3_fr | fr_0 、...、 fr_5 、 random | いいえ | fr (フランス語) | 8000 24000 48000 | |
v3_indic | hindi_male 、 hindi_female 、...、 random | いいえ | indic (ヒンディー語、テルグ語、...) | 8000 24000 48000 |
コラブ例の基本的な依存関係:
torch 、V3モデルの場合1.10+/ V4モデルの場合は2.0+。torchaudio 、Pytorchにバインドされた最新バージョンは機能する必要があります(ModelsがSTTと一緒にホストされているため、作業には必要ではありません)。omegaconf 、最新(すべての構成をロードしない場合は、削除できます)。 # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )TTS Wikiページをご覧ください。
サポートされているトークンセット: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_id | 言語 | 性別 |
|---|---|---|
| B_AVA | アバール | f |
| b_bashkir | バシキル | m |
| b_bulb | ブルガリア | m |
| b_bulc | ブルガリア | m |
| b_che | チェチェン | m |
| B_CV | チュヴァッシュ | m |
| cv_ekaterina | チュヴァッシュ | f |
| B_MYV | エルジャ | m |
| b_kalmyk | kalmyk | m |
| B_KRC | カラチェイ・バルカル | m |
| KZ_M1 | カザフ | m |
| KZ_M2 | カザフ | m |
| KZ_F3 | カザフ | f |
| KZ_F1 | カザフ | f |
| KZ_F2 | カザフ | f |
| B_KJH | カーカ | f |
| B_KPV | Komi-Ziryan | m |
| B_LEZ | レズギアン | m |
| B_MHR | マリ | f |
| B_MRJ | マリハイ | m |
| b_nog | ノガイ | f |
| ボス | 骨 | m |
| B_RU | ロシア | m |
| b_tat | タタール | m |
| marat_tt | タタール | m |
| b_tyv | トゥビニアン | m |
| b_udm | udmurt | m |
| B_UZB | ウズベック | m |
| b_sah | ヤクット | m |
| kalmyk_erdni | kalmyk | m |
| kalmyk_delghir | kalmyk | f |
(!!!)すべての入力文は、 aksharamukhaを使用してISO形式にローマ字にする必要があります。 hindiの例:
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| 言語 | スピーカー | ローマ化機能 |
|---|---|---|
| ヒンディー語 | hindi_female 、 hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| マラヤーラム語 | malayalam_female 、 malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| マニプリ | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| ベンガル語 | bengali_female 、 bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| ラジャスタニ | rajasthani_female 、 rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| タミル語 | tamil_female 、 tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| テルグ語 | telugu_female 、 telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| グジャラート語 | gujarati_female 、 gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| カンナダ | kannada_female 、 kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| 言語 | 量子化 | 品質 | colab |
|---|---|---|---|
| 'en'、 'de'、 'ru'、 'es' | ✔✔️ | リンク |
コラブ例の基本的な依存関係:
torch 、1.9+;pyyamlですが、トーチ自体がインストールされています import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Denoiseモデルは、音声を維持および/または強化しようとしながら、リバーブ、クリッピング、ハイ/ローパスフィルターなどのさまざまなアーティファクトとともに、バックグラウンドノイズを減らしようとします。また、オーディオの品質を向上させ、入力のサンプリングレートを最大48kHz増加させようとします。
提供されたすべてのモデルは、models.ymlファイルにリストされています。
| モデル | jit | 実際の入力sr | 入力sr | 出力sr | colab |
|---|---|---|---|---|---|
small_slow | ✔✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 | |
large_fast | ✔✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 | |
small_fast | ✔✔️ | 8000 16000 24000 44100 48000 | 24000 | 48000 |
コラブ例の基本的な依存関係:
torch 、2.0+;torchaudio 、Pytorchにバインドされた最新バージョンは機能するはずです。omegaconf 、最新(すべての構成をロードしない場合は、削除できます)。 import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Wikiもチェックしてください。
これらのwikiセクションを参照してください。
こちらを参照してください。
モデルを試して、問題を作成し、チャットに参加し、メールを送り、最新のニュースを読んでください。
関連情報については、Wikiとライセンスおよびティアのページを参照してください。
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
Vad:
テキストの強化:
stt
TTS:
Vad:
テキストの強化:
「スポンサー」ボタンを使用してください。


