silero models
v0.4.1

Silero-Modelle: STT / TTS-Modelle und Benchmarks in Unternehmensqualität.
STT-Grade-Stt machte erfrischend einfach (ernsthaft siehe Benchmarks). Wir bieten eine Qualität, die mit dem STT von Google vergleichbar ist (und manchmal sogar noch besser) und wir sind nicht Google.
Als Bonus:
Außerdem haben wir TTS -Modelle veröffentlicht, die die folgenden Kriterien erfüllen:
Außerdem haben wir ein Modell für die Textevertrag und Rekapitalisierung veröffentlicht, die:
Sie können unsere Modelle im Grunde in 3 Geschmacksrichtungen verwenden:
torch.hub.load() ;pip install silero und import silero ;Modelle werden sowohl von PIP- als auch von Pytorch Hub auf Demand heruntergeladen. Wenn Sie Caching benötigen, tun Sie es manuell oder über das Aufrufen eines erforderlichen Modells (es wird in einen Cache -Ordner heruntergeladen). Weitere Informationen finden Sie in diesen Dokumenten.
Pytorch Hub und PIP -Paket basieren auf demselben Code. Alle Beispiele von torch.hub.load können mit dem PIP -Paket über diese grundlegende Änderung verwendet werden:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Alle bereitgestellten Modelle sind in der Datei models.yml aufgeführt. Dort werden alle Metadaten und neueren Versionen hinzugefügt.
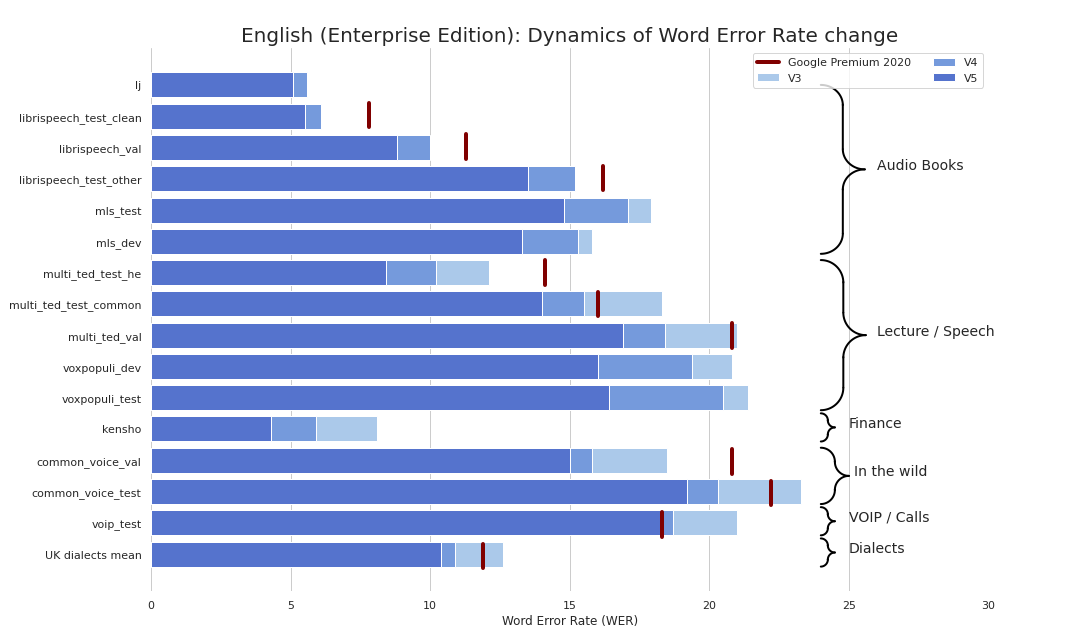
Derzeit stellen wir die folgenden Checkpoints an:
| Pytorch | Onnx | Quantisierung | Qualität | Colab | |
|---|---|---|---|---|---|
Englisch ( en_v6 ) | ✔️ | ✔️ | ✔️ | Link | |
Englisch ( en_v5 ) | ✔️ | ✔️ | ✔️ | Link | |
Deutsch ( de_v4 ) | ✔️ | ✔️ | ⌛ | Link | |
Englisch ( en_v3 ) | ✔️ | ✔️ | ✔️ | Link | |
Deutsch ( de_v3 ) | ✔️ | ⌛ | ⌛ | Link | |
Deutsch ( de_v1 ) | ✔️ | ✔️ | ⌛ | Link | |
Spanisch ( es_v1 ) | ✔️ | ✔️ | ⌛ | Link | |
Ukrainisch ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N / A |
Modellaromen:
| JIT | JIT | JIT | JIT | JIT_Q | JIT_Q | Onnx | Onnx | Onnx | Onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | klein | groß | Xlarge | xsmall | klein | xsmall | klein | groß | Xlarge | |
Englisch en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Englisch en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Englisch en_v4_0 | ✔️ | ✔️ | ||||||||
Englisch en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
Deutsch de_v4 | ✔️ | ✔️ | ||||||||
Deutsch de_v3 | ✔️ | |||||||||
Deutsch de_v1 | ✔️ | ✔️ | ||||||||
Spanisch es_v1 | ✔️ | ✔️ | ||||||||
Ukrainischer ua_v3 | ✔️ | ✔️ | ✔️ |
torch , 1,8+ (verwendet, um das Repo in TensorFlow- und ONNX -Beispielen zu klonen), wobei Änderungen für Versionen älter als 1,6 brechentorchaudio , die neueste Version, die an Pytorch gebunden istomegaconf , die neueste sollte einfach funktionierenonnx , die neueste sollte einfach funktionierenonnxruntime , neuestes sollte einfach funktionierentensorflow , neuestes sollte einfach funktionierentensorflow_hub , neuestes sollte einfach funktionierenWeitere Informationen finden Sie im folgenden Beispiel für jedes Beispiel. Alle Beispiele werden bei der Arbeit mit den neuesten großen verpackten Versionen der installierten Bibliotheken erhalten.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Unser Modell wird überall ausgeführt, das das ONNX -Modell importieren kann oder die die ONNX -Laufzeit unterstützt.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )SavedModel -Beispiel
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Alle bereitgestellten Modelle sind in der Datei models.yml aufgeführt. Dort werden alle Metadaten und neueren Versionen hinzugefügt.
V4 -Modelle unterstützen SSML. Siehe auch Colab -Beispiele für die Hauptnutzung des SSML -Tags.
| AUSWEIS | Sprecher | Auto-Stress | Sprache | Sr | Colab |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | Ja | ru (Russisch) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | NEIN | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | NEIN | ua (Ukrainisch) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | NEIN | uz (Usbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | NEIN | indic (Hindi, Telugu, ...) | 8000 , 24000 , 48000 |
V3 -Modelle unterstützen SSML. Siehe auch Colab -Beispiele für die Hauptnutzung des SSML -Tags.
| AUSWEIS | Sprecher | Auto-Stress | Sprache | Sr | Colab |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | NEIN | en (englisch) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | NEIN | en (englisch) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | NEIN | de (Deutsch) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | NEIN | es (Spanisch) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | NEIN | fr (Französisch) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | NEIN | indic (Hindi, Telugu, ...) | 8000 , 24000 , 48000 |
Grundlegende Abhängigkeiten für Colab -Beispiele:
torch , 1.10+ für V3 -Modelle/ 2.0+ für V4 -Modelle;torchaudio , die neueste Version, die an Pytorch gebunden ist, sollte funktionieren (nur, weil Modelle zusammen mit STT gehostet werden und nicht für die Arbeit erforderlich sind).omegaconf , neuester (kann auch entfernt werden, wenn Sie nicht alle Konfigurationen laden); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Schauen Sie sich unsere TTS -Wiki -Seite an.
Unterstützter Tokenset: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| LEACHER_ID | Sprache | Geschlecht |
|---|---|---|
| B_AVA | Avar | F |
| B_BASHKIR | Bashkir | M |
| B_BULB | bulgarisch | M |
| B_BULC | bulgarisch | M |
| B_che | Tschetschenisch | M |
| B_CV | Chuvash | M |
| CV_EKATERINA | Chuvash | F |
| B_MYV | Eschlya | M |
| B_KALMYK | Kalmyk | M |
| B_KRC | Karachay-Balkar | M |
| KZ_M1 | Kasachisch | M |
| KZ_M2 | Kasachisch | M |
| KZ_F3 | Kasachisch | F |
| KZ_F1 | Kasachisch | F |
| KZ_F2 | Kasachisch | F |
| B_KJH | Khakas | F |
| B_KPV | Komi-Ziryan | M |
| B_LEZ | Lezghian | M |
| B_MHR | Mari | F |
| B_MRJ | Mari hoch | M |
| B_NOG | Nogai | F |
| Chef | Ossetik | M |
| B_RU | Russisch | M |
| B_TAT | Tatar | M |
| marat_tt | Tatar | M |
| b_tyv | Tuvinian | M |
| B_UDM | Udmurt | M |
| B_UZB | Usbekisch | M |
| B_SAH | Yakut | M |
| Kalmyk_erdni | Kalmyk | M |
| kalmyk_delghir | Kalmyk | F |
(!!!) Alle Eingabesätze sollten mit aksharamukha im ISO -Format romanisiert werden. Ein Beispiel für hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Sprache | Sprecher | Romanisierungsfunktion |
|---|---|---|
| Hindi | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| Malayalam | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| Manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| Bengali | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Rajasthani | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| Tamil | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| Telugu | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| Gujarati | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| Kannada | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Sprachen | Quantisierung | Qualität | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' ' | ✔️ | Link |
Grundlegende Abhängigkeiten für Colab -Beispiele:
torch 1,9+;pyyaml , aber es ist mit Torch selbst installiert import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Denoise -Modelle versuchen, Hintergrundgeräusche zusammen mit verschiedenen Artefakten wie Reverb, Clipping, High/Tiefpass -Filtern usw. zu reduzieren, während Sie versuchen, die Sprache zu erhalten und/oder zu verbessern. Sie versuchen auch, die Audioqualität zu verbessern und die Stichprobenrate der Eingabe auf 48 kHz zu erhöhen.
Alle bereitgestellten Modelle sind in der Datei models.yml aufgeführt.
| Modell | JIT | Echte Eingabe sr | Eingabe sr | Ausgabe sr | Colab |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Grundlegende Abhängigkeiten für Colab -Beispiele:
torch , 2.0+;torchaudio , die neueste Version, die an Pytorch gebunden ist, sollte funktionieren;omegaconf , neuestes (kann auch entfernt werden, wenn Sie nicht alle Konfigurationen laden). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Schauen Sie sich auch unser Wiki an.
Bitte beachten Sie diese Wiki -Abschnitte:
Bitte beziehen Sie sich hier.
Probieren Sie unsere Modelle aus, erstellen Sie ein Problem, schließen Sie sich unserem Chat an, senden Sie uns eine E -Mail und lesen Sie die neuesten Nachrichten.
Weitere Informationen finden Sie in unserem Wiki und der Seite Lizenzierung und Ebenen und senden Sie uns eine E -Mail.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
Vad:
Textverbesserung:
Stt
TTS:
Vad:
Textverbesserung:
Bitte verwenden Sie die Schaltfläche "Sponsor".


