silero models
v0.4.1

รุ่น Silero: รุ่น STT / TTS ที่ผ่านการฝึกอบรมมาก่อนและเกณฑ์มาตรฐาน
STT ระดับองค์กรทำให้ง่ายขึ้น (อย่างจริงจังดูเกณฑ์มาตรฐาน) เราให้คุณภาพเทียบเคียงได้กับ STT ของ Google (และบางครั้งก็ดีกว่า) และเราไม่ใช่ Google
เป็นโบนัส:
นอกจากนี้เรายังได้เผยแพร่โมเดล TTS ที่เป็นไปตามเกณฑ์ดังต่อไปนี้:
นอกจากนี้เรายังได้เผยแพร่แบบจำลองสำหรับการตอบกลับข้อความและการเพิ่มทุนที่:
โดยทั่วไปคุณสามารถใช้แบบจำลองของเราใน 3 รสชาติ:
torch.hub.load() ;pip install silero จากนั้น import silero ;โมเดลจะถูกดาวน์โหลดตามความต้องการทั้งโดย PIP และ Pytorch Hub หากคุณต้องการการแคชให้ทำด้วยตนเองหรือผ่านการเรียกใช้โมเดลที่จำเป็นเพียงครั้งเดียว (จะดาวน์โหลดไปยังโฟลเดอร์แคช) โปรดดูเอกสารเหล่านี้สำหรับข้อมูลเพิ่มเติม
Pytorch Hub และ PIP Package ขึ้นอยู่กับรหัสเดียวกัน ตัวอย่างทั้งหมดของ torch.hub.load สามารถใช้กับแพ็คเกจ PIP ผ่านการเปลี่ยนแปลงพื้นฐานนี้:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )โมเดลที่ให้ไว้ทั้งหมดแสดงอยู่ในไฟล์ models.yml ข้อมูลเมตาและรุ่นใหม่ ๆ จะถูกเพิ่มที่นั่น
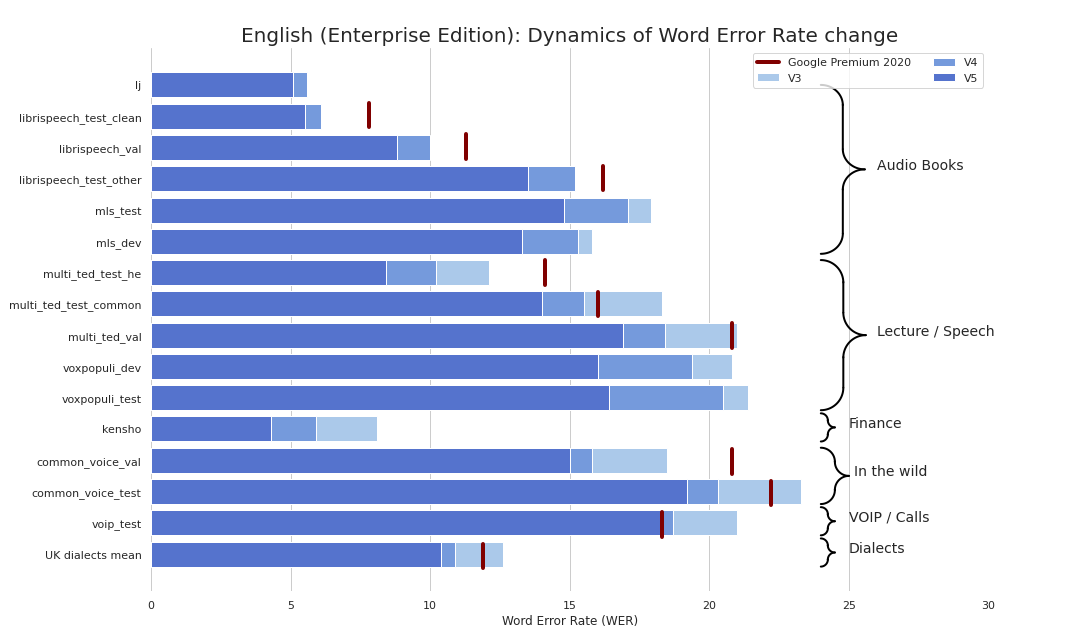
ขณะนี้เรามีจุดตรวจสอบต่อไปนี้:
| pytorch | onnx | การวัดปริมาณ | คุณภาพ | การกิน | |
|---|---|---|---|---|---|
ภาษาอังกฤษ ( en_v6 ) | การเชื่อมโยง | ||||
ภาษาอังกฤษ ( en_v5 ) | การเชื่อมโยง | ||||
ภาษาเยอรมัน ( de_v4 ) | การเชื่อมโยง | ||||
ภาษาอังกฤษ ( en_v3 ) | การเชื่อมโยง | ||||
ภาษาเยอรมัน ( de_v3 ) | การเชื่อมโยง | ||||
ภาษาเยอรมัน ( de_v1 ) | การเชื่อมโยง | ||||
ภาษาสเปน ( es_v1 ) | การเชื่อมโยง | ||||
ยูเครน ( ua_v3 ) | N/A |
รสชาติแบบจำลอง:
| การเจียระไน | การเจียระไน | การเจียระไน | การเจียระไน | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | เล็ก | ใหญ่ | xlarge | xsmall | เล็ก | xsmall | เล็ก | ใหญ่ | xlarge | |
ภาษาอังกฤษ en_v6 | ||||||||||
ภาษาอังกฤษ en_v5 | ||||||||||
ภาษาอังกฤษ en_v4_0 | ||||||||||
ภาษาอังกฤษ en_v3 | ||||||||||
เยอรมัน de_v4 | ||||||||||
เยอรมัน de_v3 | ||||||||||
เยอรมัน de_v1 | ||||||||||
สเปน es_v1 | ||||||||||
ยูเครน ua_v3 |
torch , 1.8+ (ใช้ในการโคลน repo ในตัวอย่าง tensorflow และ onnx) การเปลี่ยนแปลงการเปลี่ยนแปลงสำหรับรุ่นที่เก่ากว่า 1.6torchaudio เวอร์ชันล่าสุดที่ถูกผูกไว้กับ Pytorch ควรใช้งานได้omegaconf ล่าสุดควรทำงานonnx ล่าสุดควรใช้งานonnxruntime ล่าสุดควรทำงานtensorflow ล่าสุดควรทำงานtensorflow_hub ล่าสุดควรใช้งานได้โปรดดูรายละเอียด colab ที่ให้ไว้สำหรับแต่ละตัวอย่างด้านล่าง ตัวอย่างทั้งหมดได้รับการบำรุงรักษาให้ทำงานกับไลบรารีที่ติดตั้งล่าสุดรุ่นล่าสุด
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))โมเดลของเราจะทำงานได้ทุกที่ที่สามารถนำเข้าโมเดล ONNX หรือรองรับรันไทม์ ONNX
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )ตัวอย่างบันทึกโมเดล
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))โมเดลที่ให้ไว้ทั้งหมดแสดงอยู่ในไฟล์ models.yml ข้อมูลเมตาและรุ่นใหม่ ๆ จะถูกเพิ่มที่นั่น
รุ่น V4 รองรับ SSML ดูตัวอย่าง colab สำหรับการใช้แท็ก SSML หลัก
| รหัสประจำตัว | ลำโพง | ความเครียดอัตโนมัติ | ภาษา | SR | การกิน |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | ใช่ | ru (รัสเซีย) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | เลขที่ | cyrillic (Avar, Tatar, Kalmyk, ... ) | 8000 , 24000 , 48000 | |
v4_ua | mykyta random | เลขที่ | ua (ยูเครน) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | เลขที่ | uz (อุซเบก) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ... , random | เลขที่ | indic (ภาษาฮินดี, เตลูกู, ... ) | 8000 , 24000 , 48000 |
รุ่น V3 รองรับ SSML ดูตัวอย่าง colab สำหรับการใช้แท็ก SSML หลัก
| รหัสประจำตัว | ลำโพง | ความเครียดอัตโนมัติ | ภาษา | SR | การกิน |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ... , en_117 , random | เลขที่ | en (ภาษาอังกฤษ) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ... , assamese_male , random | เลขที่ | en (ภาษาอังกฤษ) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ... , karlsson , random | เลขที่ | de (เยอรมัน) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | เลขที่ | es (สเปน) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ... , fr_5 , random | เลขที่ | fr (ฝรั่งเศส) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ... , random | เลขที่ | indic (ภาษาฮินดี, เตลูกู, ... ) | 8000 , 24000 , 48000 |
การพึ่งพาพื้นฐานสำหรับตัวอย่าง colab:
torch , 1.10+ สำหรับรุ่น V3/ 2.0+ สำหรับรุ่น V4;torchaudio เวอร์ชันล่าสุดที่ถูกผูกไว้กับ Pytorch ควรทำงาน (จำเป็นเพียงเพราะโมเดลถูกโฮสต์ร่วมกับ STT ไม่จำเป็นสำหรับการทำงาน);omegaconf , ล่าสุด (สามารถลบออกได้เช่นกันหากคุณไม่โหลดการกำหนดค่าทั้งหมด); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )ตรวจสอบหน้า TTS Wiki ของเรา
รองรับ tokenset: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_id | ภาษา | เพศ |
|---|---|---|
| b_ava | avar | f |
| b_bashkir | Bashkir | ม. |
| b_bulb | ชาวบัลแกเรีย | ม. |
| b_bulc | ชาวบัลแกเรีย | ม. |
| b_che | คนเชเชน | ม. |
| b_cv | แช่ | ม. |
| cv_ekaterina | แช่ | f |
| b_myv | Erzya | ม. |
| b_kalmyk | Kalmyk | ม. |
| b_krc | Karachay-Balkar | ม. |
| KZ_M1 | คาซัค | ม. |
| KZ_M2 | คาซัค | ม. |
| KZ_F3 | คาซัค | f |
| KZ_F1 | คาซัค | f |
| KZ_F2 | คาซัค | f |
| b_kjh | สีกากา | f |
| b_kpv | Komi-Ziryan | ม. |
| b_lez | ชาวเลซกี้ | ม. |
| b_mhr | มารี | f |
| b_mrj | มารีสูง | ม. |
| b_nog | nogai | f |
| เจ้านาย | เกี่ยวกับเลียนแบบ | ม. |
| b_ru | ชาวรัสเซีย | ม. |
| b_tat | ตาตาร์ | ม. |
| marat_tt | ตาตาร์ | ม. |
| b_tyv | ชาวทูวิน | ม. |
| b_udm | Udmurt | ม. |
| b_uzb | อุซเบก | ม. |
| b_sah | ยาคุต | ม. |
| kalmyk_erdni | Kalmyk | ม. |
| kalmyk_delghir | Kalmyk | f |
(!!!) ประโยคอินพุตทั้งหมดควรได้รับการแก้ไขรูปแบบ ISO โดยใช้ aksharamukha ตัวอย่างสำหรับ hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| ภาษา | ลำโพง | ฟังก์ชั่นโรมัน |
|---|---|---|
| ภาษาฮินดี | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| มาลายาลัม | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| Manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| เบงกอล | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| รัฐราชสถาน | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| ทมิฬ | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| เตลูกู | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| รัฐคุชราต | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| ภาษากันนาดา | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| ภาษา | การวัดปริมาณ | คุณภาพ | การกิน |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | การเชื่อมโยง |
การพึ่งพาพื้นฐานสำหรับตัวอย่าง colab:
torch 1.9+;pyyaml แต่ติดตั้งด้วยคบเพลิงเอง import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )รุ่น Denoise พยายามลดเสียงรบกวนจากพื้นหลังพร้อมกับสิ่งประดิษฐ์ต่าง ๆ เช่นเสียงสะท้อน, การตัด, ตัวกรองสูง/lowpass ฯลฯ ในขณะที่พยายามรักษาและ/หรือเพิ่มการพูด พวกเขายังพยายามเพิ่มคุณภาพเสียงและเพิ่มอัตราการสุ่มตัวอย่างของอินพุตสูงถึง 48kHz
โมเดลที่ให้ไว้ทั้งหมดแสดงอยู่ในไฟล์ models.yml
| แบบอย่าง | การเจียระไน | SR อินพุตจริง | อินพุต SR | เอาท์พุท SR | การกิน |
|---|---|---|---|---|---|
small_slow | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | ||
large_fast | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | ||
small_fast | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
การพึ่งพาพื้นฐานสำหรับตัวอย่าง colab:
torch 2.0+;torchaudio เวอร์ชันล่าสุดที่ถูกผูกไว้กับ Pytorch ควรทำงานomegaconf , ล่าสุด (สามารถลบออกได้เช่นกันหากคุณไม่โหลดการกำหนดค่าทั้งหมด) import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )ตรวจสอบวิกิของเราด้วย
โปรดดูส่วนวิกิเหล่านี้:
โปรดอ้างอิงที่นี่
ลองใช้โมเดลของเราสร้างปัญหาเข้าร่วมการแชทส่งอีเมลถึงเราและอ่านข่าวล่าสุด
โปรดดูหน้าวิกิและหน้าใบอนุญาตและระดับสำหรับข้อมูลที่เกี่ยวข้องและส่งอีเมลถึงเรา
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
vad:
การปรับปรุงข้อความ:
STT
TTS:
vad:
การปรับปรุงข้อความ:
โปรดใช้ปุ่ม "ผู้สนับสนุน"


