silero models
v0.4.1

Modèles SILERO: modèles STT / TTS de qualité pré-formés et références.
STT de qualité d'entreprise a été rafraîchissante et simple (sérieusement, voir les repères). Nous fournissons une qualité comparable à la STT de Google (et parfois encore meilleure) et nous ne sommes pas Google.
En prime:
Nous avons également publié des modèles TTS qui satisfont aux critères suivants:
Nous avons également publié un modèle de réinscription au texte et de recapitalisation qui:
Vous pouvez essentiellement utiliser nos modèles en 3 saveurs:
torch.hub.load() ;pip install silero puis import silero ;Les modèles sont téléchargés à la demande par PIP et Pytorch Hub. Si vous avez besoin de mise en cache, faites-le manuellement ou en invoquant un modèle nécessaire une fois (il sera téléchargé dans un dossier de cache). Veuillez consulter ces documents pour plus d'informations.
Le package Pytorch Hub et PIP sont basés sur le même code. Tous les exemples de torch.hub.load peuvent être utilisés avec le package PIP via ce changement de base:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Tous les modèles fournis sont répertoriés dans le fichier Models.yml. Toutes les métadonnées et versions plus récentes y seront ajoutées.
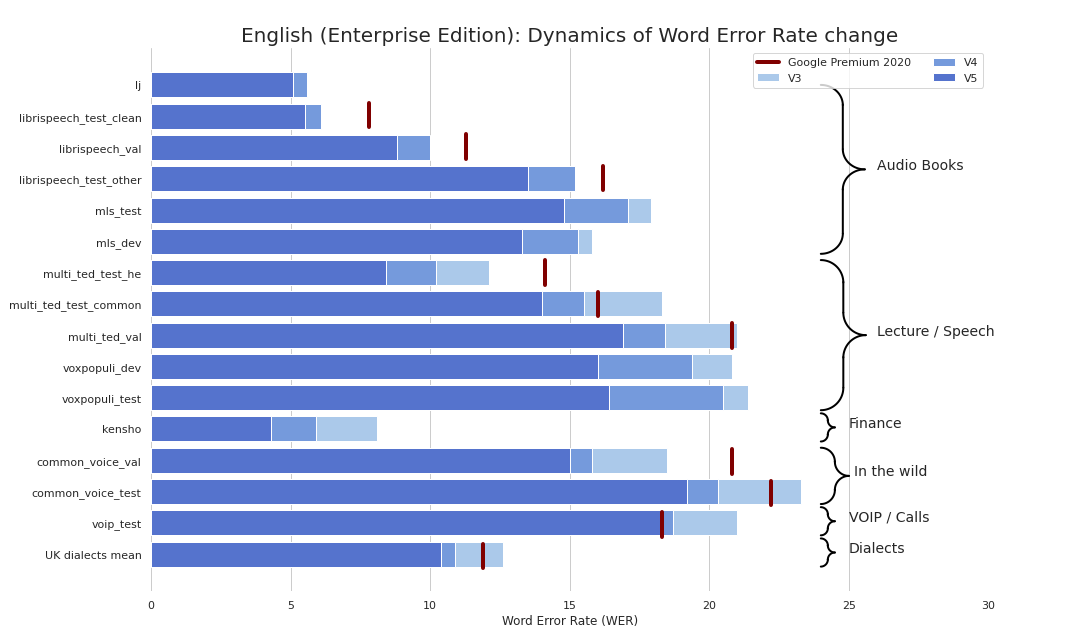
Actuellement, nous fournissons les points de contrôle suivants:
| Pytorch | Onnx | Quantification | Qualité | Colab | |
|---|---|---|---|---|---|
Anglais ( en_v6 ) | ✔️ | ✔️ | ✔️ | lien | |
Anglais ( en_v5 ) | ✔️ | ✔️ | ✔️ | lien | |
Allemand ( de_v4 ) | ✔️ | ✔️ | ⌛ | lien | |
Anglais ( en_v3 ) | ✔️ | ✔️ | ✔️ | lien | |
Allemand ( de_v3 ) | ✔️ | ⌛ | ⌛ | lien | |
Allemand ( de_v1 ) | ✔️ | ✔️ | ⌛ | lien | |
Espagnol ( es_v1 ) | ✔️ | ✔️ | ⌛ | lien | |
Ukrainien ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N / A |
Saves du modèle:
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | petit | grand | xllure | xsmall | petit | xsmall | petit | grand | xllure | |
Anglais en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Anglais en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Anglais en_v4_0 | ✔️ | ✔️ | ||||||||
Anglais en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
Allemand de_v4 | ✔️ | ✔️ | ||||||||
Allemand de_v3 | ✔️ | |||||||||
Allemand de_v1 | ✔️ | ✔️ | ||||||||
es_v1 espagnol | ✔️ | ✔️ | ||||||||
Ukrainien ua_v3 | ✔️ | ✔️ | ✔️ |
torch , 1,8+ (utilisé pour cloner le repo dans les exemples de Tensorflow et ONNX), brisant les modifications pour les versions de plus de 1,6torchaudio , la dernière version liée à Pytorch devrait simplement fonctionneromegaconf , le dernier devrait juste fonctionneronnx , le dernier devrait juste fonctionneronnxruntime , le dernier devrait juste fonctionnertensorflow , le dernier devrait juste fonctionnertensorflow_hub , le dernier devrait juste fonctionnerVeuillez consulter le colab fourni pour plus de détails pour chaque exemple ci-dessous. Tous les exemples sont maintenus pour fonctionner avec les dernières versions emballées principales des bibliothèques installées.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Notre modèle s'exécutera n'importe où qui peut importer le modèle ONNX ou qui prend en charge l'exécution ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )Exemple SavedModel
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Tous les modèles fournis sont répertoriés dans le fichier Models.yml. Toutes les métadonnées et versions plus récentes y seront ajoutées.
Les modèles V4 prennent en charge SSML. Voir également des exemples de colab pour l'utilisation de la balise SSML principale.
| IDENTIFIANT | Conférenciers | Stress automatique | Langue | SR | Colab |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | Oui | ru (russe) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | Non | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | Non | ua (Ukrainien) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | Non | uz (Ouzbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | Non | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Les modèles V3 prennent en charge SSML. Voir également des exemples de colab pour l'utilisation de la balise SSML principale.
| IDENTIFIANT | Conférenciers | Stress automatique | Langue | SR | Colab |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | Non | en (anglais) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | Non | en (anglais) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | Non | de (allemand) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | Non | es (espagnol) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | Non | fr (français) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | Non | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Dépendances de base pour les exemples de colab:
torch , 1.10+ pour les modèles V3 / 2.0+ pour les modèles V4;torchaudio , la dernière version liée à Pytorch devrait fonctionner (requise uniquement parce que les modèles sont hébergés avec STT, non requis pour le travail);omegaconf , dernier (peut également être supprimé, si vous ne chargez pas toutes les configurations); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Consultez notre page Wiki TTS.
Tokenset pris en charge: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_id | Langue | Genre |
|---|---|---|
| b_ava | Avar | F |
| b_bashkir | Bashkir | M |
| b_bulb | bulgare | M |
| b_bulc | bulgare | M |
| b_che | Tchétchène | M |
| b_cv | Chouvash | M |
| cv_ekaterina | Chouvash | F |
| b_myv | Erzya | M |
| b_kalmyk | Kalmyk | M |
| b_krc | Karachay-Balkar | M |
| kz_m1 | Kazakh | M |
| kz_m2 | Kazakh | M |
| kz_f3 | Kazakh | F |
| kz_f1 | Kazakh | F |
| kz_f2 | Kazakh | F |
| b_kjh | Kakas | F |
| b_kpv | Komi-ziryan | M |
| b_lez | Lezgien | M |
| b_mhr | Mari | F |
| b_mrj | Mari High | M |
| b_nog | Nogai | F |
| chef | Ossétique | M |
| b_ru | russe | M |
| b_tat | tatar | M |
| marat_tt | tatar | M |
| b_tyv | Tuvinien | M |
| b_udm | Udmurt | M |
| b_uzb | Ouzbek | M |
| b_sah | Yakut | M |
| kalmyk_erdni | Kalmyk | M |
| kalmyk_delghir | Kalmyk | F |
(!!!) Toutes les phrases d'entrée doivent être romannées au format ISO à l'aide d' aksharamukha . Un exemple pour hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Langue | Conférenciers | Fonction de romanisation |
|---|---|---|
| hindi | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| malayalam | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| bengali | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Rajasthani | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| tamoul | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| telugu | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| gujarati | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| kannada | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Langues | Quantification | Qualité | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | lien |
Dépendances de base pour les exemples de colab:
torch , 1,9+;pyyaml , mais il est installé avec Torch lui-même import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Les modèles Denoise tentent de réduire le bruit de fond ainsi que divers artefacts tels que la réverbération, l'écrêtage, les filtres élevés / passe-bas, etc., tout en essayant de préserver et / ou d'améliorer la parole. Ils tentent également d'améliorer la qualité de l'audio et d'augmenter le taux d'échantillonnage de l'entrée jusqu'à 48 kHz.
Tous les modèles fournis sont répertoriés dans le fichier Models.yml.
| Modèle | Jit | Sr d'entrée réelle | Entrée SR | Sortie SR | Colab |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Dépendances de base pour les exemples de colab:
torch , 2.0+;torchaudio , la dernière version liée à Pytorch devrait fonctionner;omegaconf , plus tard (peut également être supprimé, si vous ne chargez pas toutes les configurations). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Découvrez également notre wiki.
Veuillez vous référer à ces sections wiki:
Veuillez vous référer ici.
Essayez nos modèles, créez un problème, rejoignez notre chat, envoyez-nous un e-mail et lisez les dernières nouvelles.
Veuillez vous référer à notre wiki et à la page Licensing and Tiers pour des informations pertinentes et envoyez-nous un e-mail.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
VAD:
Amélioration du texte:
STT
TTS:
VAD:
Amélioration du texte:
Veuillez utiliser le bouton "sponsor".


