silero models
v0.4.1

실로 모델 : 미리 훈련 된 엔터프라이즈 급 STT / TTS 모델 및 벤치 마크.
Enterprise-Grade STT는 상쾌하게 간단하게 만들어졌습니다 (심각하게 벤치 마크 참조). 우리는 Google의 STT와 비슷한 품질을 제공하고 때로는 더 나은 품질을 제공하며 Google이 아닙니다.
보너스로 :
또한 다음 기준을 충족하는 TTS 모델을 발표했습니다.
또한 우리는 텍스트 부과 및 자본화를위한 모델을 발표했습니다.
기본적으로 3 가지 맛으로 모델을 사용할 수 있습니다.
torch.hub.load() ;pip install silero 다음 import silero .모델은 PIP와 Pytorch Hub에 의해 요청시 다운로드됩니다. 캐싱이 필요한 경우 수동으로 또는 필요한 모델을 한 번 호출하십시오 (캐시 폴더로 다운로드됩니다). 자세한 내용은이 문서를 참조하십시오.
Pytorch Hub 및 PIP 패키지는 동일한 코드를 기반으로합니다. 모든 torch.hub.load 예제는이 기본 변경을 통해 PIP 패키지와 함께 사용할 수 있습니다.
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )제공된 모든 모델은 Models.yml 파일에 나열되어 있습니다. 메타 데이터와 최신 버전이 추가됩니다.
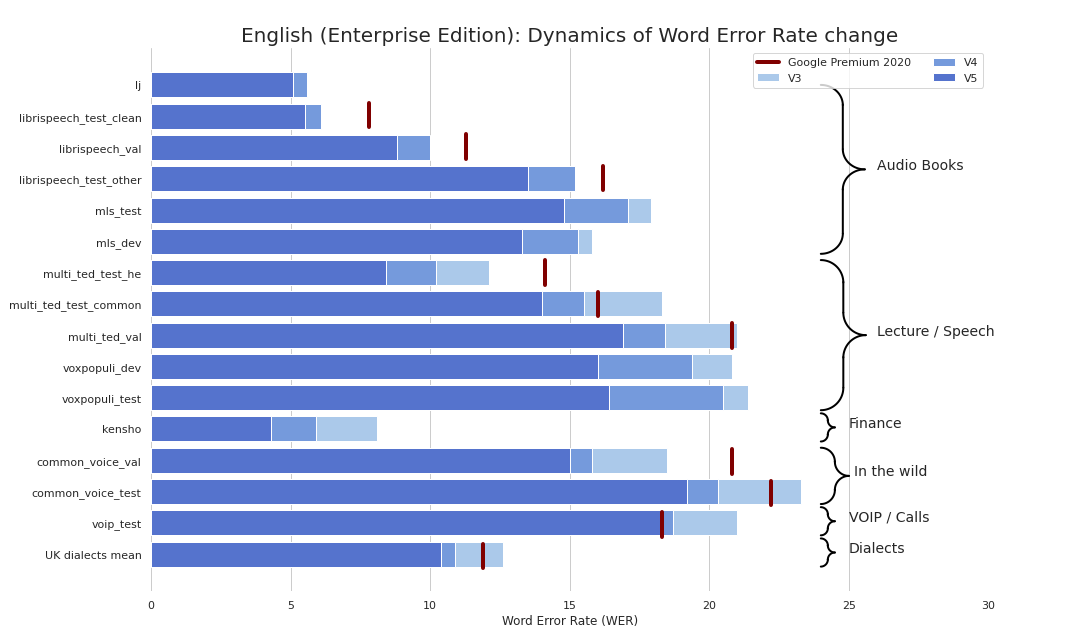
현재 우리는 다음과 같은 체크 포인트를 제공합니다.
| Pytorch | onx | 양자화 | 품질 | 콜랩 | |
|---|---|---|---|---|---|
영어 ( en_v6 ) | ✔️ | ✔️ | ✔️ | 링크 | |
영어 ( en_v5 ) | ✔️ | ✔️ | ✔️ | 링크 | |
독일어 ( de_v4 ) | ✔️ | ✔️ | ⌛ | 링크 | |
영어 ( en_v3 ) | ✔️ | ✔️ | ✔️ | 링크 | |
독일어 ( de_v3 ) | ✔️ | ⌛ | ⌛ | 링크 | |
독일어 ( de_v1 ) | ✔️ | ✔️ | ⌛ | 링크 | |
스페인어 ( es_v1 ) | ✔️ | ✔️ | ⌛ | 링크 | |
우크라이나 ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N/A |
모델 풍미 :
| jit | jit | jit | jit | JIT_Q | JIT_Q | onx | onx | onx | onx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | 작은 | 크기가 큰 | xlarge | xsmall | 작은 | xsmall | 작은 | 크기가 큰 | xlarge | |
영어 en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
영어 en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
영어 en_v4_0 | ✔️ | ✔️ | ||||||||
영어 en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
독일 de_v4 | ✔️ | ✔️ | ||||||||
독일 de_v3 | ✔️ | |||||||||
독일 de_v1 | ✔️ | ✔️ | ||||||||
스페인 es_v1 | ✔️ | ✔️ | ||||||||
우크라이나 ua_v3 | ✔️ | ✔️ | ✔️ |
torch , 1.8+ (Tensorflow 및 Onnx 예제에서 레포를 복제하는 데 사용됨), 1.6 이상의 버전의 변경 사항을 깨뜨립니다.torchaudio , Pytorch에 바인딩 된 최신 버전은omegaconf , 최신 기능은 작동해야합니다onnx , 최신 기능은 작동해야합니다onnxruntime , 최신 기능은 작동해야합니다tensorflow , 최신은 작동해야합니다tensorflow_hub , 최신은 작동해야합니다아래 각 예제에 대한 자세한 내용은 제공된 Colab을 참조하십시오. 모든 예제는 설치된 라이브러리의 최신 주요 패키지 버전과 함께 작동하도록 유지됩니다.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))우리의 모델은 ONNX 모델을 가져올 수 있거나 ONNX 런타임을 지원하는 모든 곳에서 실행됩니다.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )저장 모델 예
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))제공된 모든 모델은 Models.yml 파일에 나열되어 있습니다. 메타 데이터와 최신 버전이 추가됩니다.
V4 모델은 SSML을 지원합니다. 메인 SSML 태그 사용법의 Colab 예제도 참조하십시오.
| ID | 스피커 | 자동 스트레스 | 언어 | SR | 콜랩 |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | 예 | ru (러시아어) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | 아니요 | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | 아니요 | ua (우크라이나) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | 아니요 | uz (Uzbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | 아니요 | indic (힌디어, 텔루구 어, ...) | 8000 , 24000 , 48000 |
V3 모델은 SSML을 지원합니다. 메인 SSML 태그 사용법의 Colab 예제도 참조하십시오.
| ID | 스피커 | 자동 스트레스 | 언어 | SR | 콜랩 |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | 아니요 | en (영어) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | 아니요 | en (영어) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | 아니요 | de (독일어) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | 아니요 | es (스페인어) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | 아니요 | fr (프랑스어) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | 아니요 | indic (힌디어, 텔루구 어, ...) | 8000 , 24000 , 48000 |
Colab 예제의 기본 종속성 :
torch , V3 모델의 경우 1.10+/ V4 모델의 경우 2.0+;torchaudio , Pytorch에 바인딩 된 최신 버전은 작동해야합니다 (모델이 STT와 함께 호스팅되기 때문에 작업에 필요하지 않기 때문에 필요).omegaconf , 최신 (모든 구성을로드하지 않으면 제거 할 수 있음); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )TTS Wiki 페이지를 확인하십시오.
지원되는 토큰 셋 : !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| speaker_id | 언어 | 성별 |
|---|---|---|
| b_ava | 아바 | 에프 |
| b_bashkir | 바쉬 키르 | 중 |
| b_bulb | 불가리아 사람 | 중 |
| b_bulc | 불가리아 사람 | 중 |
| b_che | 체첸 | 중 |
| B_CV | Chuvash | 중 |
| CV_EKATERINA | Chuvash | 에프 |
| b_myv | 에르시 | 중 |
| b_kalmyk | 칼미크 | 중 |
| B_KRC | Karachay-Balkar | 중 |
| KZ_M1 | 카자흐 | 중 |
| KZ_M2 | 카자흐 | 중 |
| KZ_F3 | 카자흐 | 에프 |
| KZ_F1 | 카자흐 | 에프 |
| KZ_F2 | 카자흐 | 에프 |
| b_kjh | 카카 | 에프 |
| B_KPV | 코미-지리아 | 중 |
| b_lez | Lezghian | 중 |
| b_mhr | 마리 | 에프 |
| b_mrj | 마리 하이 | 중 |
| b_nog | 노 가이 | 에프 |
| 사장 | 골수 | 중 |
| B_RU | 러시아인 | 중 |
| b_tat | 타타르 | 중 |
| marat_tt | 타타르 | 중 |
| b_tyv | 투기니아 | 중 |
| b_udm | udmurt | 중 |
| b_uzb | 우즈벡 | 중 |
| B_SAH | 야 카트 | 중 |
| Kalmyk_erdni | 칼미크 | 중 |
| Kalmyk_delghir | 칼미크 | 에프 |
(!!!) 모든 입력 문장은 aksharamukha 사용하여 ISO 형식으로 로마 형식으로 만들어야합니다. hindi 의 예 :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| 언어 | 스피커 | 로마 화 기능 |
|---|---|---|
| 힌디 어 | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| 말라 얄 람어 | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| 마니 푸리 | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| 벵골 사람 | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| 라자스타니 | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| 타밀 사람 | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| 텔루구 어 | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| 구자라트 | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| 칸나다어 | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| 언어 | 양자화 | 품질 | 콜랩 |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | 링크 |
Colab 예제의 기본 종속성 :
torch , 1.9+;pyyaml 이지만 토치 자체가 설치되어 있습니다 import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Denoise Models는 리버브, 클리핑, 고/저역 통과 필터 등과 같은 다양한 유물과 함께 배경 소음을 줄이려고 시도하면서 음성을 보존 및/또는 강화하려고합니다. 또한 오디오 품질을 높이고 최대 48kHz의 입력의 샘플링 속도를 높이려고합니다.
제공된 모든 모델은 Models.yml 파일에 나열되어 있습니다.
| 모델 | jit | 실제 입력 sr | 입력 sr | 출력 sr | 콜랩 |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Colab 예제의 기본 종속성 :
torch , 2.0+;torchaudio , Pytorch에 바운드 최신 버전이 작동해야합니다.omegaconf , 최신 (모든 구성을로드하지 않으면 제거 할 수 있습니다). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )또한 Wiki를 확인하십시오.
이 위키 섹션을 참조하십시오.
여기를 참조하십시오.
모델을 시도하고, 문제를 만들고, 채팅에 참여하고, 이메일을 보내고, 최신 뉴스를 읽으십시오.
관련 정보는 Wiki 및 라이센스 및 계층 페이지를 참조하고 이메일을 보내 주시기 바랍니다.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}stt :
TTS :
Vad :
텍스트 향상 :
stt
TTS :
Vad :
텍스트 향상 :
"스폰서"버튼을 사용하십시오.


