silero models
v0.4.1

Modelos SILERO: Modelos e referências STT / TTS de nível corporativo pré-treinado.
O STT de nível empresarial simplificou refrescante (seriamente, veja benchmarks). Fornecemos qualidade comparável ao STT do Google (e às vezes até melhor) e não somos o Google.
Como um bônus:
Também publicamos modelos TTS que atendem aos seguintes critérios:
Também publicamos um modelo para repunciação e recapitalização de texto que:
Você pode basicamente usar nossos modelos em 3 sabores:
torch.hub.load() ;pip install silero e import silero ;Os modelos são baixados sob demanda pelo PIP e Pytorch Hub. Se você precisar de armazenamento em cache, faça -o manualmente ou invocando um modelo necessário uma vez (ele será baixado para uma pasta de cache). Consulte esses documentos para obter mais informações.
O pacote Pytorch Hub e Pip são baseados no mesmo código. Todos os exemplos da torch.hub.load podem ser usados com o pacote PIP por meio desta alteração básica:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Todos os modelos fornecidos estão listados no arquivo models.yml. Quaisquer metadados e versões mais recentes serão adicionados lá.
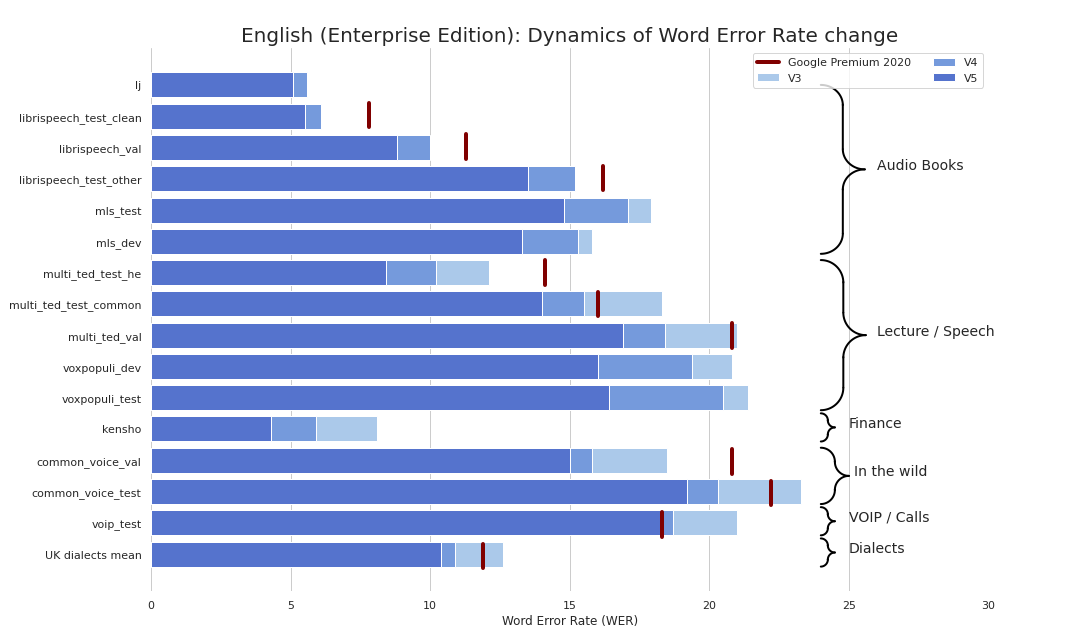
Atualmente, fornecemos os seguintes pontos de verificação:
| Pytorch | ONNX | Quantização | Qualidade | Colab | |
|---|---|---|---|---|---|
Inglês ( en_v6 ) | ✔️ | ✔️ | ✔️ | link | |
Inglês ( en_v5 ) | ✔️ | ✔️ | ✔️ | link | |
Alemão ( de_v4 ) | ✔️ | ✔️ | ⌛ | link | |
Inglês ( en_v3 ) | ✔️ | ✔️ | ✔️ | link | |
Alemão ( de_v3 ) | ✔️ | ⌛ | ⌛ | link | |
Alemão ( de_v1 ) | ✔️ | ✔️ | ⌛ | link | |
Espanhol ( es_v1 ) | ✔️ | ✔️ | ⌛ | link | |
Ucraniano ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N / D |
Flavores modelo:
| jit | jit | jit | jit | jit_q | jit_q | ONNX | ONNX | ONNX | ONNX | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | pequeno | grande | XLARGE | xsmall | pequeno | xsmall | pequeno | grande | XLARGE | |
English en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Inglês en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
Inglês en_v4_0 | ✔️ | ✔️ | ||||||||
Inglês en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
de_v4 alemão | ✔️ | ✔️ | ||||||||
de_v3 alemão | ✔️ | |||||||||
de_v1 alemão | ✔️ | ✔️ | ||||||||
Espanhol es_v1 | ✔️ | ✔️ | ||||||||
Ucraniano ua_v3 | ✔️ | ✔️ | ✔️ |
torch , 1,8+ (usado para clonar o repo em exemplos Tensorflow e Onnx), interrompendo as mudanças para versões mais antigas que 1.6torchaudio , a versão mais recente ligada a Pytorch deve apenas funcionaromegaconf , mais recente deve funcionaronnx , mais recente deve funcionaronnxruntime , mais recente deve funcionartensorflow , mais recente deve funcionartensorflow_hub , mais recente deve funcionarConsulte o Colab fornecido para obter detalhes para cada exemplo abaixo. Todos os exemplos são mantidos para trabalhar com as mais recentes versões principais embaladas das bibliotecas instaladas.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Nosso modelo será executado em qualquer lugar que possa importar o modelo ONNX ou que suporta o tempo de execução do ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )Exemplo de Model Saved
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Todos os modelos fornecidos estão listados no arquivo models.yml. Quaisquer metadados e versões mais recentes serão adicionados lá.
Os modelos V4 suportam SSML. Veja também os exemplos do COLAB para o uso principal de tags do SSML.
| EU IA | Alto -falantes | Auto-estresse | Linguagem | Sr | Colab |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | sim | ru (russo) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | não | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | não | ua (ucraniano) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | não | uz (uzbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | não | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Os modelos V3 suportam SSML. Veja também os exemplos do COLAB para o uso principal de tags do SSML.
| EU IA | Alto -falantes | Auto-estresse | Linguagem | Sr | Colab |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | não | en (inglês) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | não | en (inglês) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | não | de (alemão) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | não | es (espanhol) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | não | fr (francês) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | não | indic (hindi, telugu, ...) | 8000 , 24000 , 48000 |
Dependências básicas para exemplos de colab:
torch , 1.10+ para modelos V3/ 2.0+ para modelos V4;torchaudio , versão mais recente vinculada ao Pytorch, deve funcionar (exigido apenas porque os modelos são hospedados em conjunto com o STT, não é necessário para o trabalho);omegaconf , mais recente (também pode ser removido, se você não carregar todas as configurações); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Confira nossa página do Wiki TTS.
Tokenset suportado: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| SOPAFER_ID | Linguagem | Gênero |
|---|---|---|
| b_ava | Avar | F |
| b_bashkir | Bashkir | M |
| b_bulb | búlgaro | M |
| b_bulc | búlgaro | M |
| b_che | CHECHEN | M |
| B_CV | Chuvash | M |
| cv_ekaterina | Chuvash | F |
| B_MYV | Erzya | M |
| b_kalmyk | Kalmyk | M |
| b_krc | Karachay-Balkar | M |
| kz_m1 | Cazaque | M |
| kz_m2 | Cazaque | M |
| kz_f3 | Cazaque | F |
| kz_f1 | Cazaque | F |
| kz_f2 | Cazaque | F |
| b_kjh | Khakas | F |
| B_KPV | Komi-Ziryan | M |
| B_LEZ | Lezghian | M |
| B_MHR | Mari | F |
| b_mrj | Mari High | M |
| b_nog | Nogai | F |
| chefe | Ossético | M |
| b_ru | russo | M |
| b_tat | Tatar | M |
| marat_tt | Tatar | M |
| b_tyv | Tuviniano | M |
| b_udm | Udmurt | M |
| b_uzb | Uzbek | M |
| B_SAH | Yakut | M |
| Kalmyk_erdni | Kalmyk | M |
| Kalmyk_delghir | Kalmyk | F |
(!!!) Todas as frases de entrada devem ser romanizadas no formato ISO usando aksharamukha . Um exemplo para hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Linguagem | Alto -falantes | Função de romanização |
|---|---|---|
| hindi | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| malaiala | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| Manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| bengali | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Rajasthani | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| tâmil | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| Telugu | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| Gujarati | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| Kannada | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Idiomas | Quantização | Qualidade | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | link |
Dependências básicas para exemplos de colab:
torch , 1,9+;pyyaml , mas está instalado com a própria tocha import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Os modelos de denoise tentam reduzir o ruído de fundo, juntamente com vários artefatos, como reverb, recorte, filtros de passagens altas/lutas etc., enquanto tentam preservar e/ou aprimorar a fala. Eles também tentam aumentar a qualidade do áudio e aumentar a taxa de amostragem da entrada em até 48kHz.
Todos os modelos fornecidos estão listados no arquivo models.yml.
| Modelo | Jit | Entrada real sr | Entrada sr | Saída sr | Colab |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Dependências básicas para exemplos de colab:
torch , 2.0+;torchaudio , versão mais recente vinculada a Pytorch, deve funcionar;omegaconf , mais recente (também pode ser removido, se você não carregar todas as configurações). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Confira também nosso wiki.
Consulte estas seções wiki:
Por favor, consulte aqui.
Experimente nossos modelos, crie um problema, participe do nosso bate -papo, envie um e -mail e leia as últimas notícias.
Consulte nosso wiki e a página de licenciamento e camadas para obter informações relevantes e envie um email.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
Vad:
Aprimoramento do texto:
STT
TTS:
Vad:
Aprimoramento do texto:
Por favor, use o botão "Patrocinador".


