silero models
v0.4.1

Model Silero: Model dan tatanan dan tolok ukur pra-latih perusahaan.
STT perusahaan-kelas membuat sederhana yang menyegarkan (serius, lihat tolok ukur). Kami memberikan kualitas yang sebanding dengan STT Google (dan kadang -kadang bahkan lebih baik) dan kami bukan Google.
Sebagai bonus:
Kami juga telah menerbitkan model TTS yang memenuhi kriteria berikut:
Kami juga telah menerbitkan model untuk repunctasi teks dan rekapitalisasi yang:
Anda pada dasarnya dapat menggunakan model kami dalam 3 rasa:
torch.hub.load() ;pip install silero dan kemudian import silero ;Model diunduh berdasarkan permintaan baik oleh PIP dan Pytorch Hub. Jika Anda membutuhkan caching, lakukan secara manual atau melalui memohon model yang diperlukan sekali (itu akan diunduh ke folder cache). Silakan lihat dokumen ini untuk informasi lebih lanjut.
Pytorch Hub dan paket PIP didasarkan pada kode yang sama. Semua contoh torch.hub.load dapat digunakan dengan paket PIP melalui perubahan dasar ini:
# before
torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' , # or silero_tts or silero_te
** kwargs )
# after
from silero import silero_stt , silero_tts , silero_te
silero_stt ( ** kwargs )Semua model yang disediakan tercantum dalam file model.yml. Versi metadata dan yang lebih baru akan ditambahkan di sana.
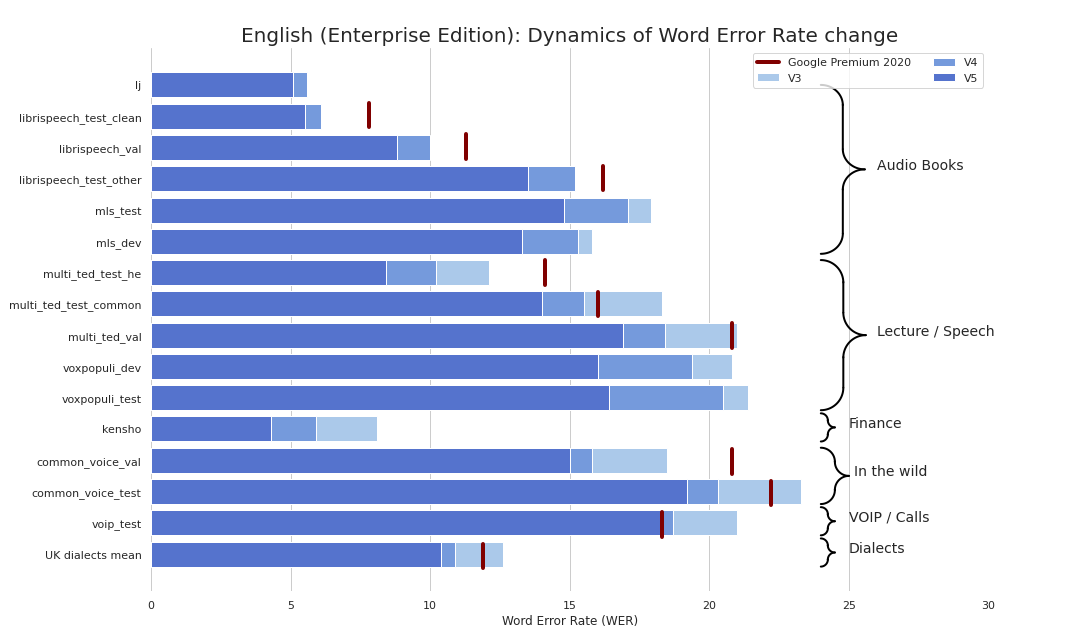
Saat ini kami menyediakan pos pemeriksaan berikut:
| Pytorch | Onnx | Kuantisasi | Kualitas | Colab | |
|---|---|---|---|---|---|
Bahasa Inggris ( en_v6 ) | ✔️ | ✔️ | ✔️ | link | |
Bahasa Inggris ( en_v5 ) | ✔️ | ✔️ | ✔️ | link | |
Jerman ( de_v4 ) | ✔️ | ✔️ | ⌛ | link | |
Bahasa Inggris ( en_v3 ) | ✔️ | ✔️ | ✔️ | link | |
Jerman ( de_v3 ) | ✔️ | ⌛ | ⌛ | link | |
Jerman ( de_v1 ) | ✔️ | ✔️ | ⌛ | link | |
Spanyol ( es_v1 ) | ✔️ | ✔️ | ⌛ | link | |
Ukraina ( ua_v3 ) | ✔️ | ✔️ | ✔️ | N/a |
Model Flavours:
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | kecil | besar | xlarge | xsmall | kecil | xsmall | kecil | besar | xlarge | |
English en_v6 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
English en_v5 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |||||
English en_v4_0 | ✔️ | ✔️ | ||||||||
English en_v3 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
de_v4 Jerman | ✔️ | ✔️ | ||||||||
de_v3 Jerman | ✔️ | |||||||||
de_v1 Jerman | ✔️ | ✔️ | ||||||||
es_v1 Spanyol | ✔️ | ✔️ | ||||||||
ua_v3 Ukraina | ✔️ | ✔️ | ✔️ |
torch , 1.8+ (digunakan untuk mengkloning repo dalam contoh TensorFlow dan ONNX), memecahkan perubahan untuk versi yang lebih tua dari 1,6torchaudio , versi terbaru terikat ke pytorch seharusnya hanya bekerjaomegaconf , terbaru harus bekerjaonnx , terbaru harus bekerja hanyaonnxruntime , terbaru harus bekerjatensorflow , terbaru hanya harus berfungsitensorflow_hub , terbaru harus hanya berfungsiSilakan lihat Colab yang disediakan untuk detail untuk setiap contoh di bawah ini. Semua contoh dipertahankan untuk bekerja dengan versi kemasan utama terbaru dari perpustakaan yang diinstal.
import torch
import zipfile
import torchaudio
from glob import glob
device = torch . device ( 'cpu' ) # gpu also works, but our models are fast enough for CPU
model , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_stt' ,
language = 'en' , # also available 'de', 'es'
device = device )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils # see function signature for details
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' ,
dst = 'speech_orig.wav' , progress = True )
test_files = glob ( 'speech_orig.wav' )
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]),
device = device )
output = model ( input )
for example in output :
print ( decoder ( example . cpu ()))Model kami akan berjalan di mana saja yang dapat mengimpor model ONNX atau yang mendukung runtime ONNX.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual ONNX model
torch . hub . download_url_to_file ( models . stt_models . en . latest . onnx , 'model.onnx' , progress = True )
onnx_model = onnx . load ( 'model.onnx' )
onnx . checker . check_model ( onnx_model )
ort_session = onnxruntime . InferenceSession ( 'model.onnx' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# actual ONNX inference and decoding
onnx_input = input . detach (). cpu (). numpy ()
ort_inputs = { 'input' : onnx_input }
ort_outs = ort_session . run ( None , ort_inputs )
decoded = decoder ( torch . Tensor ( ort_outs [ 0 ])[ 0 ])
print ( decoded )Contoh SavedModel
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_ , decoder , utils = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' , model = 'silero_stt' , language = language )
( read_batch , split_into_batches ,
read_audio , prepare_model_input ) = utils
# see available models
torch . hub . download_url_to_file ( 'https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml' , 'models.yml' )
models = OmegaConf . load ( 'models.yml' )
available_languages = list ( models . stt_models . keys ())
assert language in available_languages
# load the actual tf model
torch . hub . download_url_to_file ( models . stt_models . en . latest . tf , 'tf_model.tar.gz' )
subprocess . run ( 'rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model' , shell = True , check = True )
tf_model = tf . saved_model . load ( 'tf_model' )
# download a single file in any format compatible with TorchAudio
torch . hub . download_url_to_file ( 'https://opus-codec.org/static/examples/samples/speech_orig.wav' , dst = 'speech_orig.wav' , progress = True )
test_files = [ 'speech_orig.wav' ]
batches = split_into_batches ( test_files , batch_size = 10 )
input = prepare_model_input ( read_batch ( batches [ 0 ]))
# tf inference
res = tf_model . signatures [ "serving_default" ]( tf . constant ( input . numpy ()))[ 'output_0' ]
print ( decoder ( torch . Tensor ( res . numpy ())[ 0 ]))Semua model yang disediakan tercantum dalam file model.yml. Versi metadata dan yang lebih baru akan ditambahkan di sana.
Model V4 mendukung SSML. Juga lihat contoh Colab untuk penggunaan tag SSML utama.
| PENGENAL | Pembicara | Stres otomatis | Bahasa | Sr | Colab |
|---|---|---|---|---|---|
v4_ru | aidar , baya , kseniya , xenia , eugene , random | Ya | ru (Rusia) | 8000 , 24000 , 48000 | |
v4_cyrillic | b_ava , marat_tt , kalmyk_erdni ... | TIDAK | cyrillic (Avar, Tatar, Kalmyk, ...) | 8000 , 24000 , 48000 | |
v4_ua | mykyta , random | TIDAK | ua (Ukraina) | 8000 , 24000 , 48000 | |
v4_uz | dilnavoz | TIDAK | uz (Uzbek) | 8000 , 24000 , 48000 | |
v4_indic | hindi_male , hindi_female , ..., random | TIDAK | indic (Hindi, Telugu, ...) | 8000 , 24000 , 48000 |
Model V3 mendukung SSML. Juga lihat contoh Colab untuk penggunaan tag SSML utama.
| PENGENAL | Pembicara | Stres otomatis | Bahasa | Sr | Colab |
|---|---|---|---|---|---|
v3_en | en_0 , en_1 , ..., en_117 , random | TIDAK | en (bahasa Inggris) | 8000 , 24000 , 48000 | |
v3_en_indic | tamil_female , ..., assamese_male , random | TIDAK | en (bahasa Inggris) | 8000 , 24000 , 48000 | |
v3_de | eva_k , ..., karlsson , random | TIDAK | de (Jerman) | 8000 , 24000 , 48000 | |
v3_es | es_0 , es_1 , es_2 , random | TIDAK | es (Spanyol) | 8000 , 24000 , 48000 | |
v3_fr | fr_0 , ..., fr_5 , random | TIDAK | fr (Prancis) | 8000 , 24000 , 48000 | |
v3_indic | hindi_male , hindi_female , ..., random | TIDAK | indic (Hindi, Telugu, ...) | 8000 , 24000 , 48000 |
Ketergantungan Dasar untuk Contoh Colab:
torch , 1.10+ untuk model V3/ 2.0+ untuk model V4;torchaudio , versi terbaru yang terikat ke Pytorch harus bekerja (hanya diperlukan karena model di -host bersama dengan STT, tidak diperlukan untuk bekerja);omegaconf , terbaru (dapat dihapus juga, jika Anda tidak memuat semua konfigurasi); # V4
import torch
language = 'ru'
model_id = 'v4_ru'
sample_rate = 48000
speaker = 'xenia'
device = torch . device ( 'cpu' )
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = language ,
speaker = model_id )
model . to ( device ) # gpu or cpu
audio = model . apply_tts ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate ) # V4
import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/models/tts/ru/v4_ru.pt' ,
local_file )
model = torch . package . PackageImporter ( local_file ). load_pickle ( "tts_models" , "model" )
model . to ( device )
example_text = 'В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.'
sample_rate = 48000
speaker = 'baya'
audio_paths = model . save_wav ( text = example_text ,
speaker = speaker ,
sample_rate = sample_rate )Lihat halaman Wiki TTS kami.
Tokenset yang Didukung : !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ
| Speaker_id | Bahasa | Jenis kelamin |
|---|---|---|
| B_AVA | Avar | F |
| b_bashkir | Bashkir | M |
| b_bulb | Bulgaria | M |
| b_bulc | Bulgaria | M |
| b_che | Chechen | M |
| b_cv | Chuvash | M |
| CV_EKATERINA | Chuvash | F |
| b_myv | Erzya | M |
| b_kalmyk | Kalmyk | M |
| B_KRC | Karachay-Balkar | M |
| KZ_M1 | Kazakh | M |
| KZ_M2 | Kazakh | M |
| KZ_F3 | Kazakh | F |
| KZ_F1 | Kazakh | F |
| KZ_F2 | Kazakh | F |
| b_kjh | Khakas | F |
| b_kpv | Komi-Ziryan | M |
| B_LEZ | Lezghian | M |
| B_MHR | Mari | F |
| b_mrj | Mari High | M |
| b_nog | Nogai | F |
| bos | Ossetik | M |
| b_ru | Rusia | M |
| b_tat | Tatar | M |
| Marat_tt | Tatar | M |
| b_tyv | Tuvinian | M |
| b_udm | Udmurt | M |
| b_uzb | Uzbek | M |
| b_sah | Yakut | M |
| Kalmyk_erdni | Kalmyk | M |
| Kalmyk_delghir | Kalmyk | F |
(!!!) Semua kalimat input harus diromanisasi ke format ISO menggunakan aksharamukha . Contoh untuk hindi :
# V3
import torch
from aksharamukha import transliterate
# Loading model
model , example_text = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_tts' ,
language = 'indic' ,
speaker = 'v4_indic' )
orig_text = "प्रसिद्द कबीर अध्येता, पुरुषोत्तम अग्रवाल का यह शोध आलेख, उस रामानंद की खोज करता है"
roman_text = transliterate . process ( 'Devanagari' , 'ISO' , orig_text )
print ( roman_text )
audio = model . apply_tts ( roman_text ,
speaker = 'hindi_male' )| Bahasa | Pembicara | Fungsi romanisasi |
|---|---|---|
| Hindi | hindi_female , hindi_male | transliterate.process('Devanagari', 'ISO', orig_text) |
| Malayalam | malayalam_female , malayalam_male | transliterate.process('Malayalam', 'ISO', orig_text) |
| Manipuri | manipuri_female | transliterate.process('Bengali', 'ISO', orig_text) |
| Benggala | bengali_female , bengali_male | transliterate.process('Bengali', 'ISO', orig_text) |
| Rajasthani | rajasthani_female , rajasthani_female | transliterate.process('Devanagari', 'ISO', orig_text) |
| Tamil | tamil_female , tamil_male | transliterate.process('Tamil', 'ISO', orig_text, pre_options=['TamilTranscribe']) |
| Telugu | telugu_female , telugu_male | transliterate.process('Telugu', 'ISO', orig_text) |
| Gujarati | gujarati_female , gujarati_male | transliterate.process('Gujarati', 'ISO', orig_text) |
| Kannada | kannada_female , kannada_male | transliterate.process('Kannada', 'ISO', orig_text) |
| Bahasa | Kuantisasi | Kualitas | Colab |
|---|---|---|---|
| 'en', 'de', 'ru', 'es' | ✔️ | link |
Ketergantungan Dasar untuk Contoh Colab:
torch , 1.9+;pyyaml , tapi dipasang dengan obor itu sendiri import torch
model , example_texts , languages , punct , apply_te = torch . hub . load ( repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_te' )
input_text = input ( 'Enter input text n ' )
apply_te ( input_text , lan = 'en' )Model Denoise berusaha mengurangi kebisingan latar belakang bersama dengan berbagai artefak seperti reverb, kliping, filter tinggi/rendah, dll., Saat mencoba melestarikan dan/atau meningkatkan bicara. Mereka juga berusaha untuk meningkatkan kualitas audio dan meningkatkan laju pengambilan sampel input hingga 48kHz.
Semua model yang disediakan tercantum dalam file model.yml.
| Model | Jit | SR INPUT NYATA | Input sr | Output sr | Colab |
|---|---|---|---|---|---|
small_slow | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
large_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 | |
small_fast | ✔️ | 8000 , 16000 , 24000 , 44100 , 48000 | 24000 | 48000 |
Ketergantungan Dasar untuk Contoh Colab:
torch , 2.0+;torchaudio , versi terbaru terikat ke Pytorch harus bekerja;omegaconf , terbaru (dapat dihapus juga, jika Anda tidak memuat semua konfigurasi). import torch
name = 'small_slow'
device = torch . device ( 'cpu' )
model , samples , utils = torch . hub . load (
repo_or_dir = 'snakers4/silero-models' ,
model = 'silero_denoise' ,
name = name ,
device = device )
( read_audio , save_audio , denoise ) = utils
i = 0
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
audio_path = f'sample { i } .wav'
audio = read_audio ( audio_path ). to ( device )
output = model ( audio )
save_audio ( f'result { i } .wav' , output . squeeze ( 1 ). cpu ())
i = 1
torch . hub . download_url_to_file (
samples [ i ],
dst = f'sample { i } .wav' ,
progress = True
)
output , sr = denoise ( model , f'sample { i } .wav' , f'result { i } .wav' , device = 'cpu' ) import os
import torch
device = torch . device ( 'cpu' )
torch . set_num_threads ( 4 )
local_file = 'model.pt'
if not os . path . isfile ( local_file ):
torch . hub . download_url_to_file ( 'https://models.silero.ai/denoise_models/sns_latest.jit' ,
local_file )
model = torch . jit . load ( local_file )
torch . _C . _jit_set_profiling_mode ( False )
torch . set_grad_enabled ( False )
model . to ( device )
a = torch . rand (( 1 , 48000 ))
a = a . to ( device )
out = model ( a )Lihat juga wiki kami.
Silakan merujuk ke bagian wiki ini:
Silakan merujuk di sini.
Coba model kami, buat masalah, bergabunglah dengan obrolan kami, email kami, dan baca berita terbaru.
Silakan merujuk ke wiki kami dan halaman lisensi dan tiers untuk informasi yang relevan, dan email kami.
@misc { Silero Models,
author = { Silero Team } ,
title = { Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks } ,
year = { 2021 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/snakers4/silero-models} } ,
commit = { insert_some_commit_here } ,
email = { hello @ silero.ai }
}STT:
TTS:
VAD:
Peningkatan teks:
Stt
TTS:
VAD:
Peningkatan teks:
Silakan gunakan tombol "Sponsor".


