vits2
1.0.0
最近已经对单阶段的文本到语音模型进行了积极研究,其结果表现优于两阶段管道系统。尽管以前的单阶段模型取得了长足的进步,但其间歇性的不自然,计算效率和对音素转化的强烈依赖有改善的余地。在这项工作中,我们介绍了VITS2,这是一种单阶段的文本到语音模型,通过改进以前工作的几个方面来有效地综合了更自然的语音。我们提出了改进的结构和训练机制,并提出了所提出的方法可有效改善自然性,多演讲者模型中语音特征的相似性以及培训和推理的效率。此外,我们证明了以前作品中对音素转换的强大依赖性可以大大减少我们的方法,这允许完全端到端的单级方法。
演示:https://vits-2.github.io/demo/
论文:https://arxiv.org/abs/2307.16430
VITS2的非官方实施。这是一项正在进行的工作。有关更多详细信息,请参考Todo。
| 持续时间预测指标 | 标准化流程 | 文本编码器 |
|---|---|---|
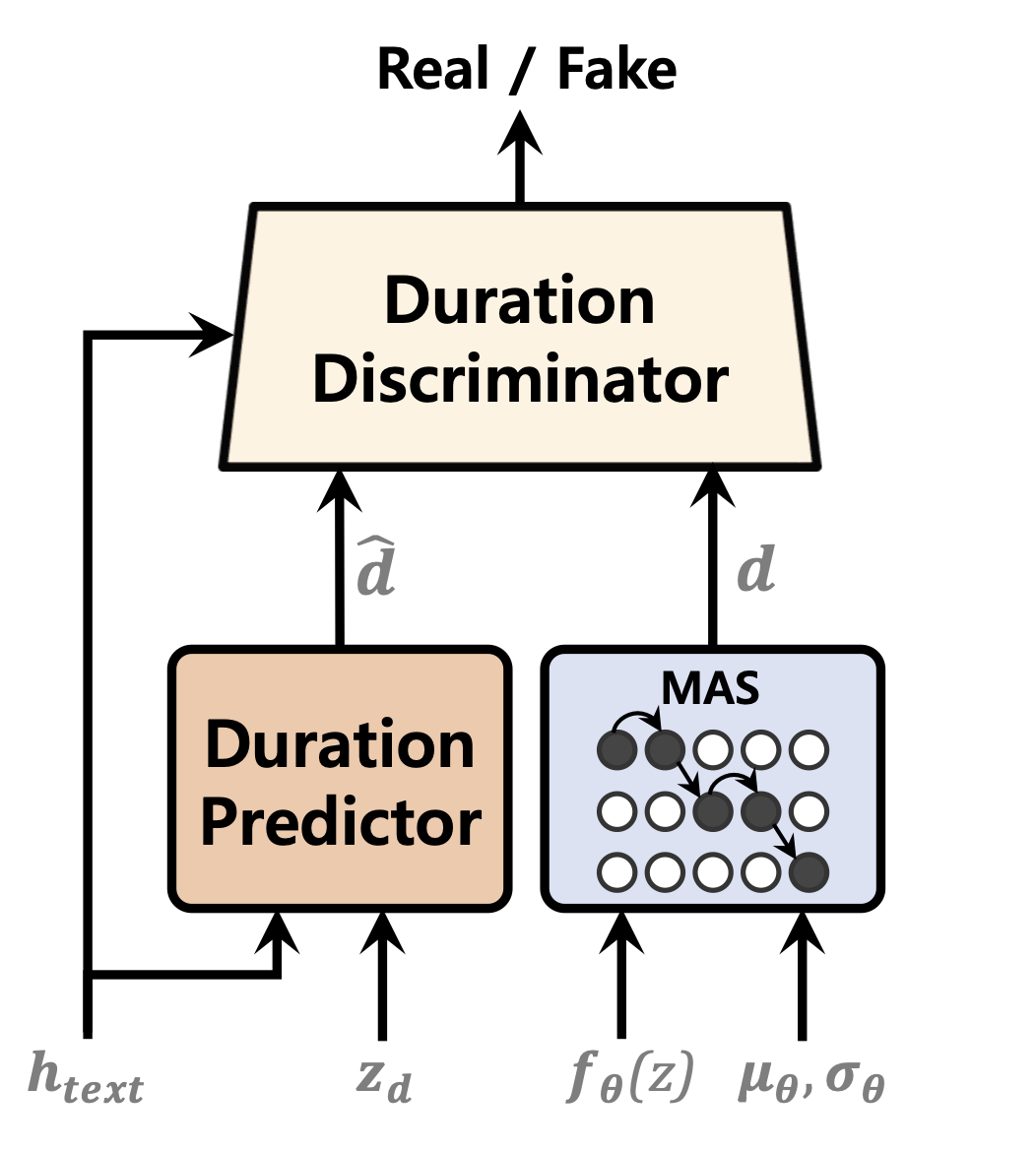 | 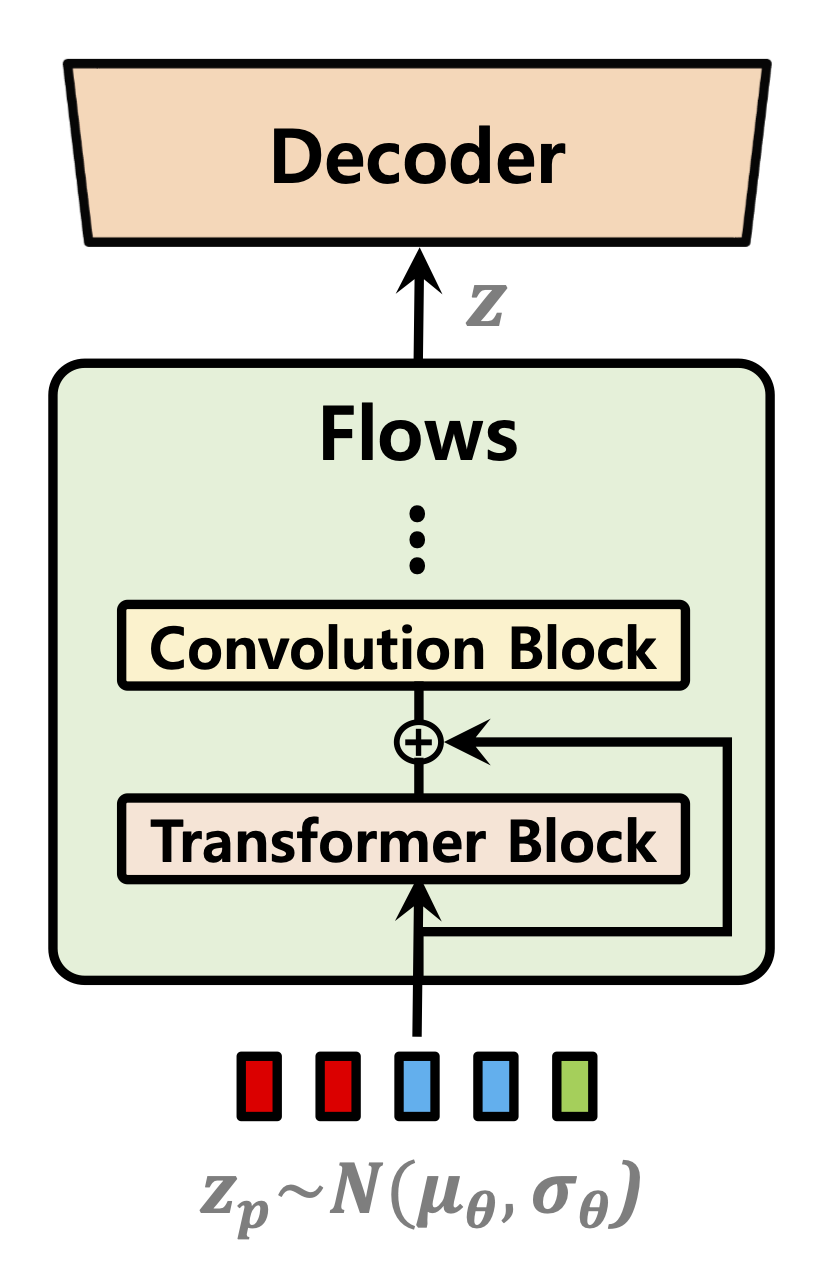 | 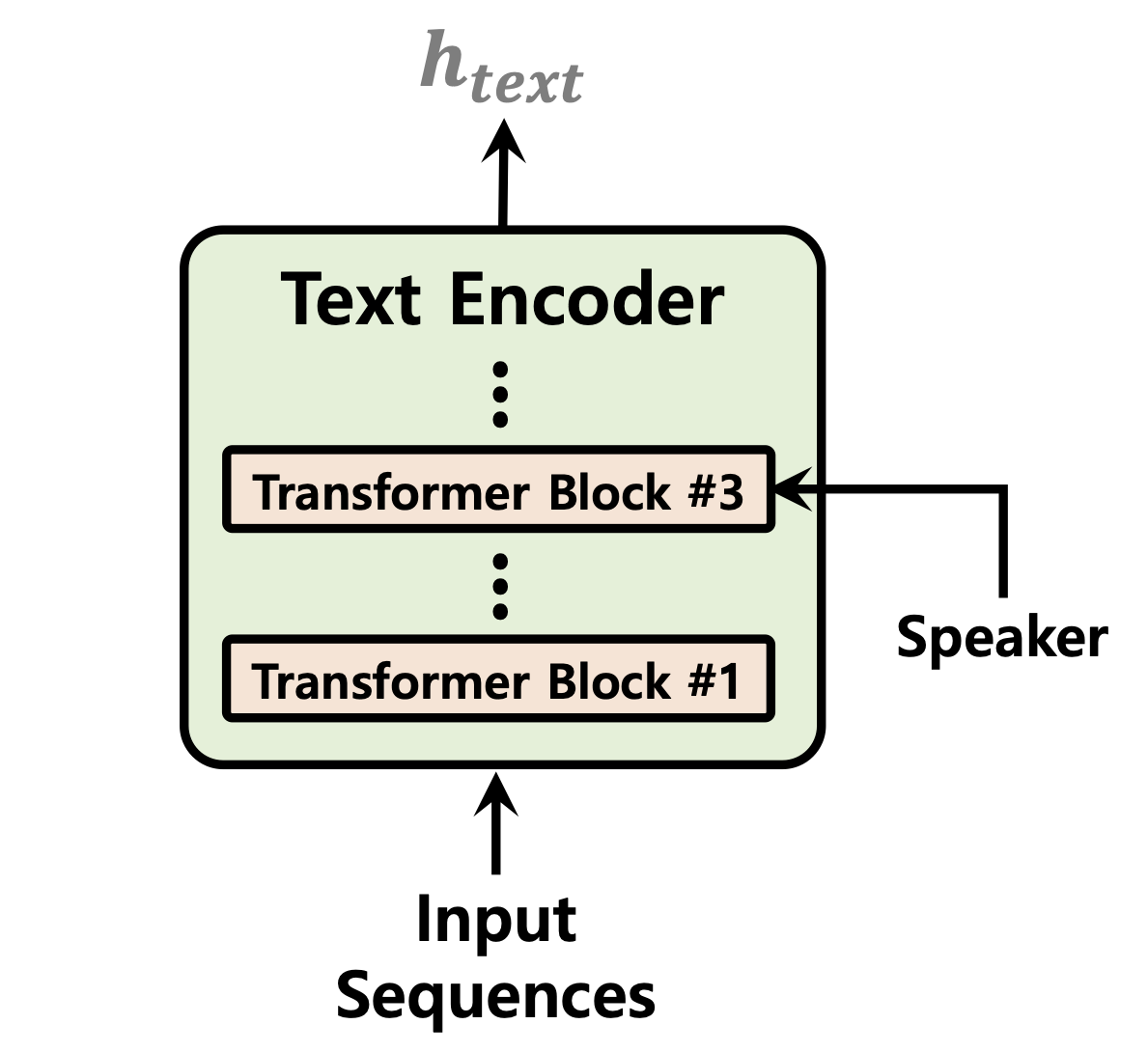 |
[进行中]
在1 GPU上为LJSpeech数据集进行52,000个培训步骤之后的音频样本:https://github.com/daniilrobnikov/vits2/assets2/assets2/91742765/d769c77a-bd92-bd92-bd92-bd92-bd92-4732-96 e7-96e7-bab53bf50d783
克隆仓库
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2这是假设您在克隆之后已导航到vits2 root。
注意:这是在python3.11下与Conda Env进行的。对于其他Python版本,您可能会遇到版本冲突。
Pytorch 2.0请参阅要求。
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " 您可以选择以下三个选项:LJ Speech,VCTK或自定义数据集。
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yaml预处理文本。请参阅准备/filelists.ipynb
重命名或创建指向数据集文件夹的链接。
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(可选):将音频文件置于22050 Hz。请参阅audio_resample.ipynb
预处理旋光图。请参阅mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yaml预处理文本。请参阅准备/filelists.ipynb
重命名或创建指向数据集文件夹的链接。
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2datasets集目录中复制ljs_base并将其重命名为custom_baseconfig.yaml中的以下字段: data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml注意:如果要使用phonemize_text清洁剂,则可能需要安装espeak-ng 。请参考Espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_base请参阅teac thece.ipynb和inperion_batch.ipynb
[进行中]


