vits2
1.0.0
Einstufige Text-zu-Sprache-Modelle wurden in letzter Zeit aktiv untersucht, und ihre Ergebnisse haben zweistufige Pipeline-Systeme übertroffen. Obwohl das vorherige einstufige Modell große Fortschritte erzielt hat, gibt es in Bezug auf die zeitweilige Unnaturalität, die Recheneffizienz und die starke Abhängigkeit von der Phonemkonvertierung Verbesserung. In dieser Arbeit stellen wir Vits2 vor, ein einstufiges Text-zu-Sprach-Modell, das eine natürlichere Sprache effizient synthetisiert, indem sie verschiedene Aspekte der vorherigen Arbeiten verbessern. Wir schlagen verbesserte Strukturen und Trainingsmechanismen vor und präsentieren, dass die vorgeschlagenen Methoden die Natürlichkeit, die Ähnlichkeit der Sprachmerkmale in einem Modell mit mehreren Sprechern und die Effizienz von Training und Inferenz wirksam sind. Darüber hinaus zeigen wir, dass die starke Abhängigkeit von der Phonemumwandlung in früheren Arbeiten mit unserer Methode erheblich reduziert werden kann, was einen vollständig end-to-End-Ansatz ermöglicht.
Demo: https://vits-2.github.io/demo/
Papier: https://arxiv.org/abs/2307.16430
Inoffizielle Implementierung von Vits2. Dies ist eine laufende Arbeit. Weitere Informationen finden Sie in TODO.
| Dauerprädiktor | Normalisierung von Flüssen | Text Encoder |
|---|---|---|
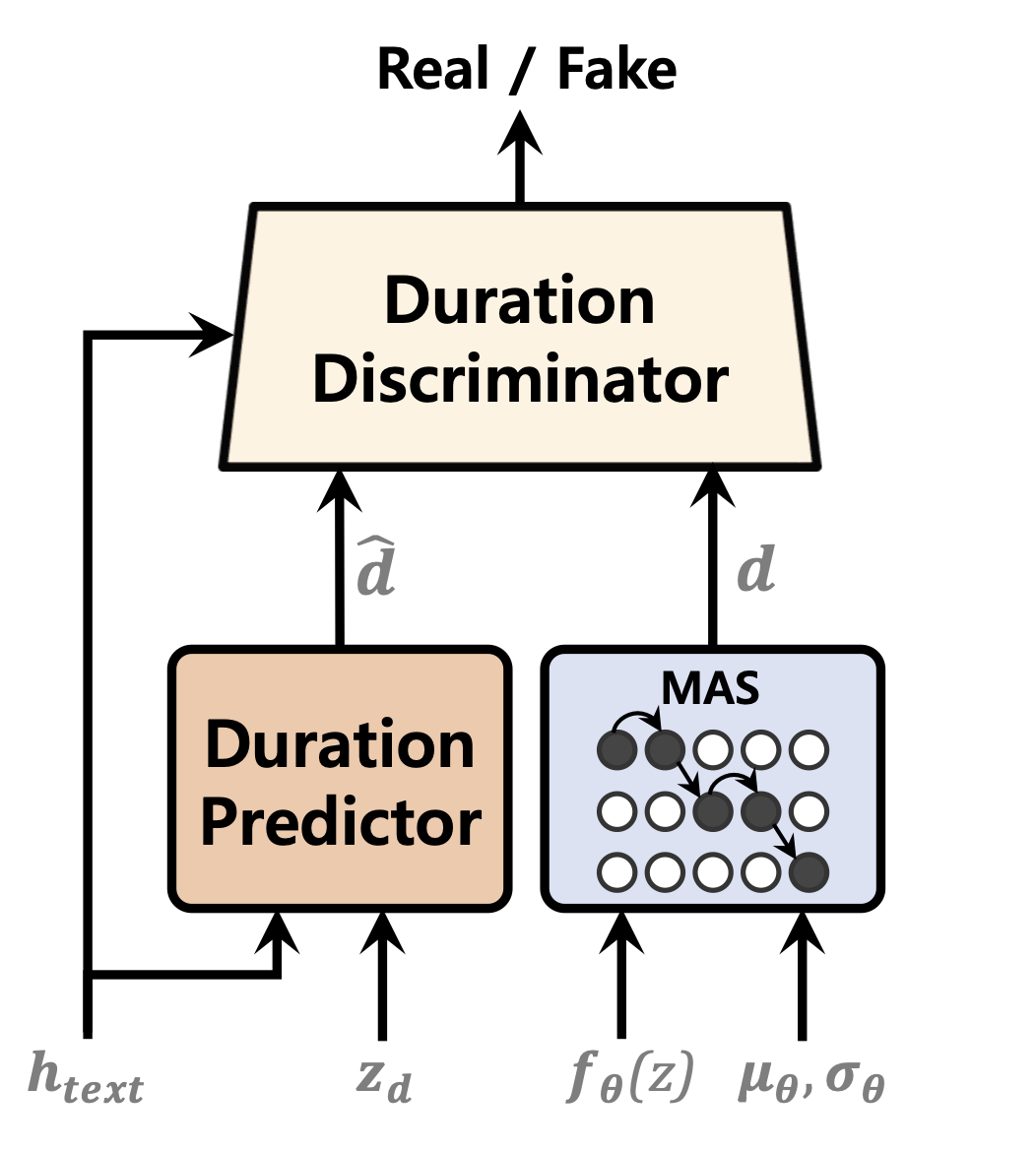 | 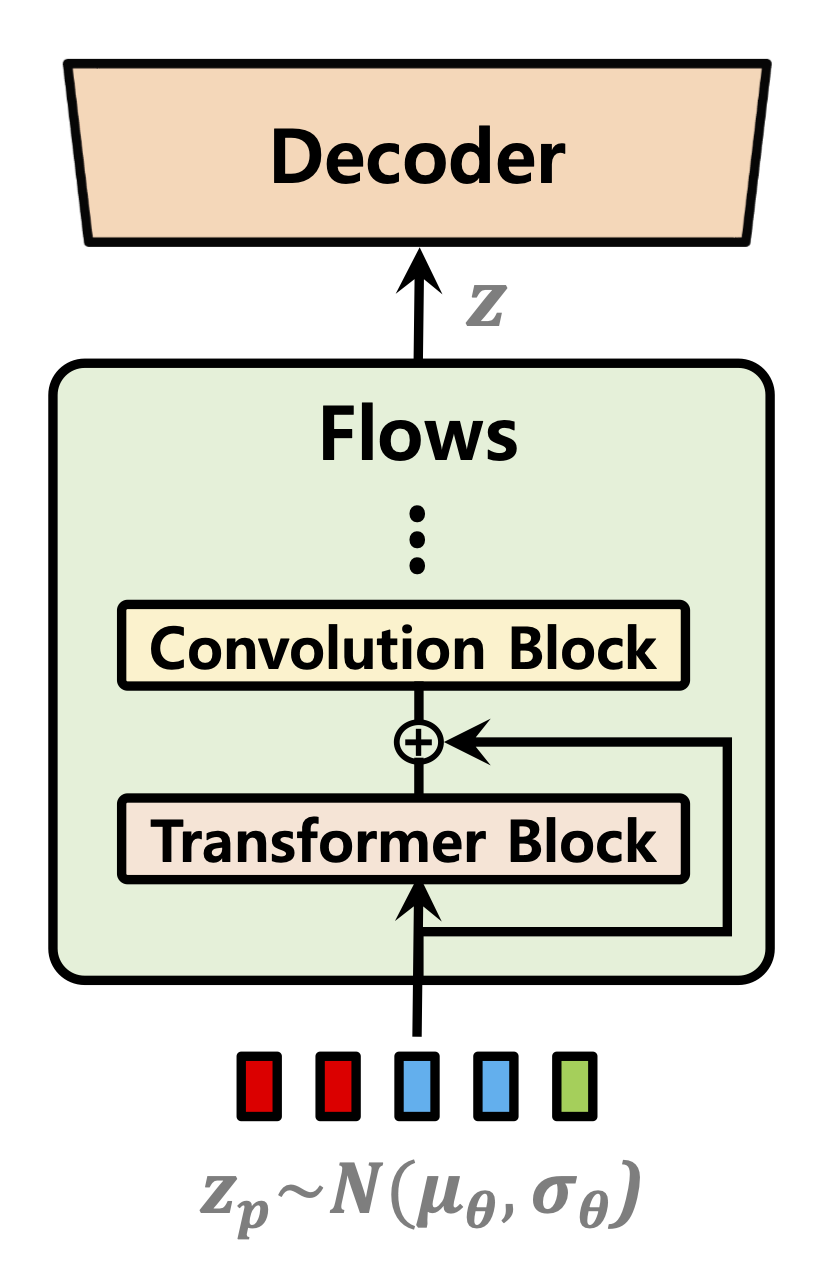 | 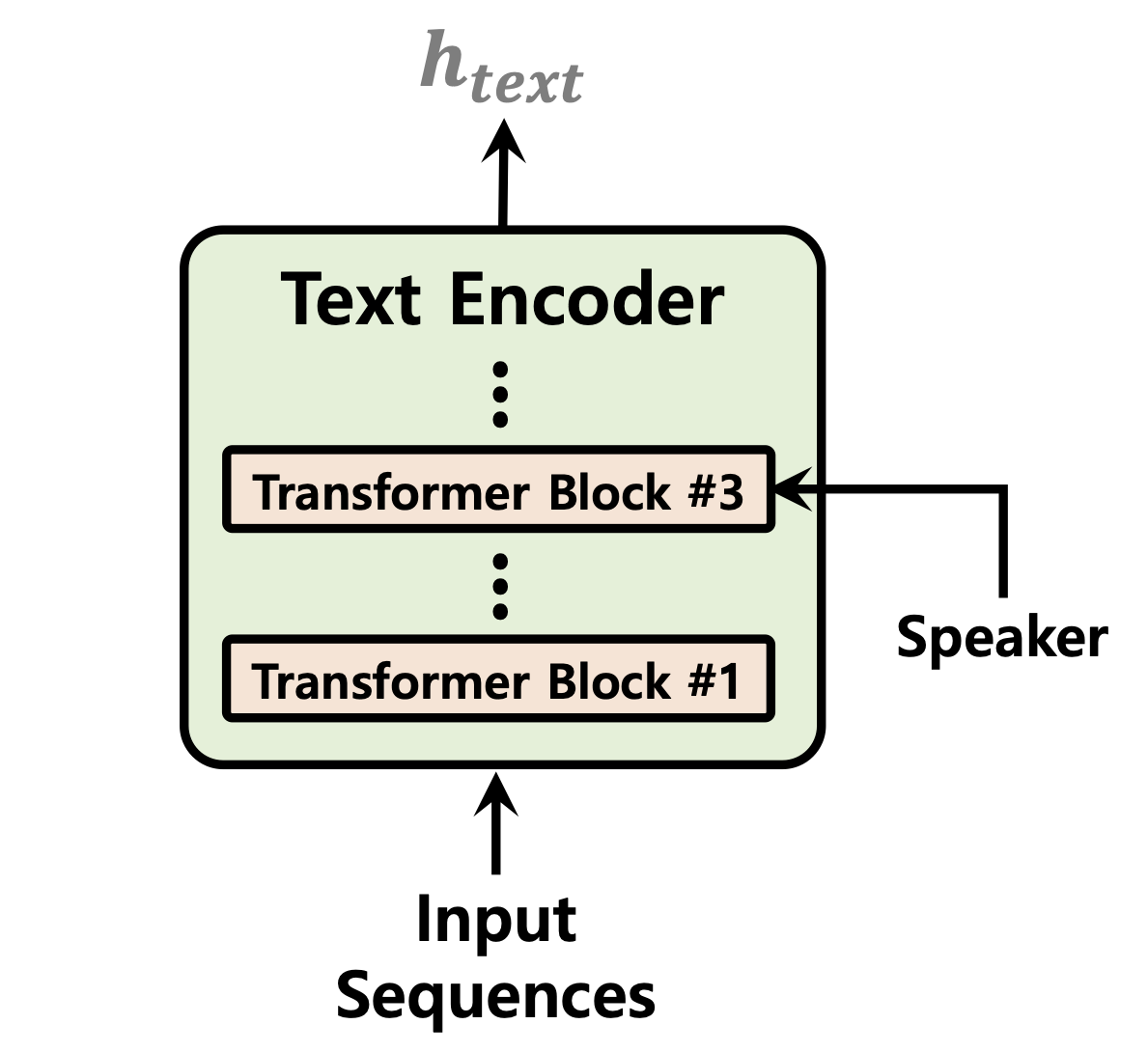 |
[Im Gange]
Audio-Probe nach 52.000 Trainingsschritten auf 1 GPU für LJSpeech-Datensatz: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-abf53bf50d783
Klonen Sie das Repo
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Dies setzt voraus, dass Sie nach dem Klonen zur vits2 -Wurzel navigiert haben.
Hinweis: Dies wird unter python3.11 mit Conda Env getestet. Für andere Python -Versionen können Sie auf Versionskonflikte stoßen.
Pytorch 2.0 Bitte beziehen Sie sich an die Anforderungen.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Es gibt drei Optionen, aus denen Sie auswählen können: LJ Speech, VCTK oder benutzerdefinierten Datensatz.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlVorverarbeitungstext. Siehe Preped/Filelists.IPynb
Benennen Sie einen Link zum Dataset -Ordner um oder erstellen Sie einen Link.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(optional): DownSample die Audiodateien auf 22050 Hz. Siehe audio_resample.ipynb
Präprozess-Melspektrogramme. Siehe mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlVorverarbeitungstext. Siehe Preped/Filelists.IPynb
Benennen Sie einen Link zum Dataset -Ordner um oder erstellen Sie einen Link.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base datasets custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml Hinweis: Möglicherweise müssen Sie espeak-ng installieren, wenn Sie phonemize_text Cleaner verwenden möchten. Bitte beziehen Sie sich auf Espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseSiehe Inferenz.ipynb und Inference_Batch.ipynb
[Im Gange]


