vits2
1.0.0
Los modelos de texto a voz de una sola etapa se han estudiado activamente recientemente, y sus resultados han superado a los sistemas de tuberías de dos etapas. Aunque el modelo anterior de una sola etapa ha hecho un gran progreso, hay margen de mejora en términos de su antinatural intermitente, eficiencia computacional y una fuerte dependencia de la conversión de fonemas. En este trabajo, presentamos VITS2, un modelo de texto a voz de una sola etapa que sintetiza eficientemente un discurso más natural al mejorar varios aspectos del trabajo anterior. Proponemos estructuras y mecanismos de entrenamiento mejorados y presentamos que los métodos propuestos son efectivos para mejorar la naturalidad, la similitud de las características del habla en un modelo de múltiples altavoces y la eficiencia de entrenamiento e inferencia. Además, demostramos que la fuerte dependencia de la conversión de fonemas en trabajos anteriores puede reducirse significativamente con nuestro método, lo que permite un enfoque de una sola etapa completamente de extremo a extremo.
Demo: https://vits-2.github.io/demo/
Documento: https://arxiv.org/abs/2307.16430
Implementación no oficial de VITS2. Este es un trabajo en progreso. Consulte a TODO para obtener más detalles.
| Predictor de duración | Flujos de normalización | Codificador de texto |
|---|---|---|
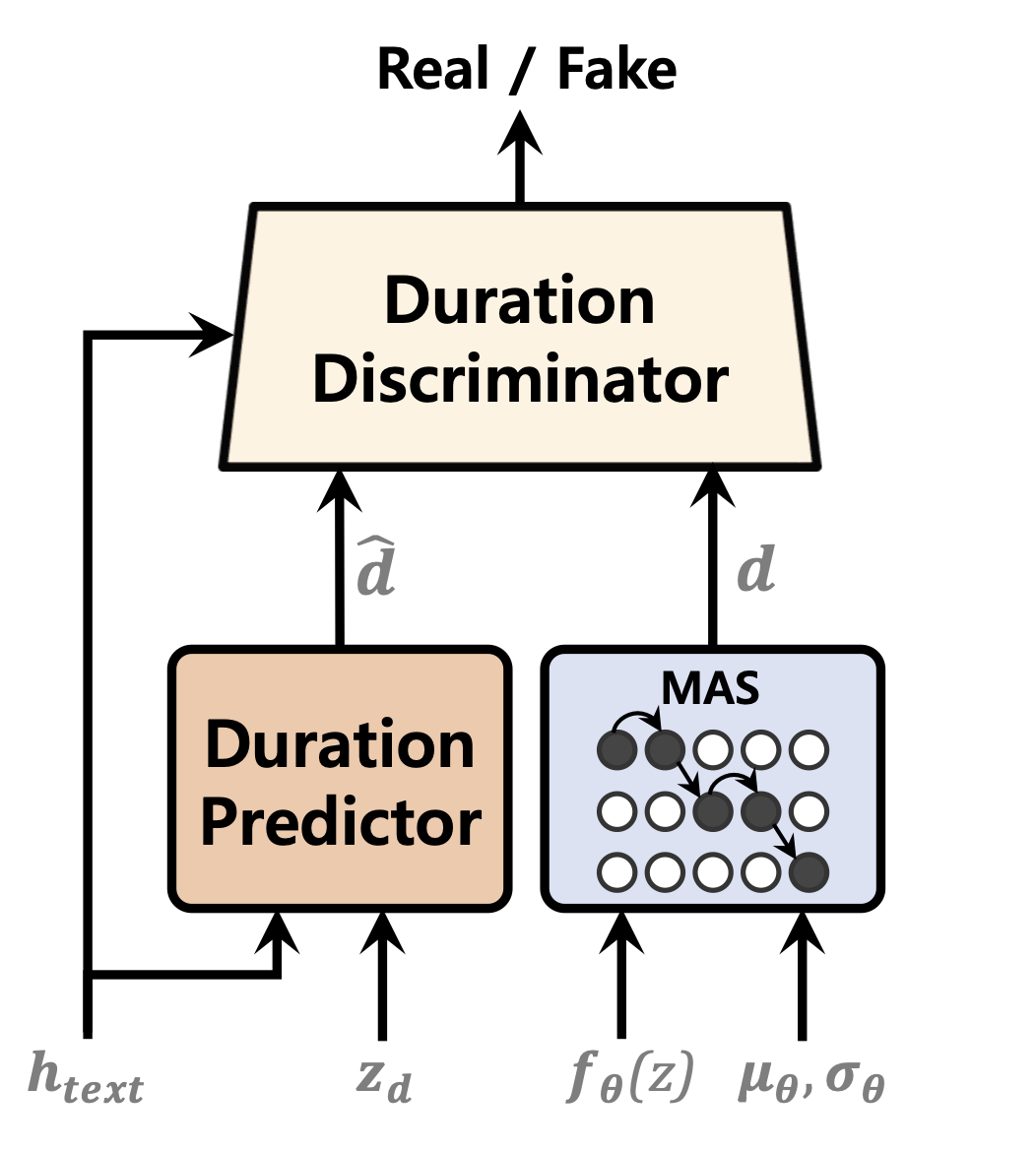 | 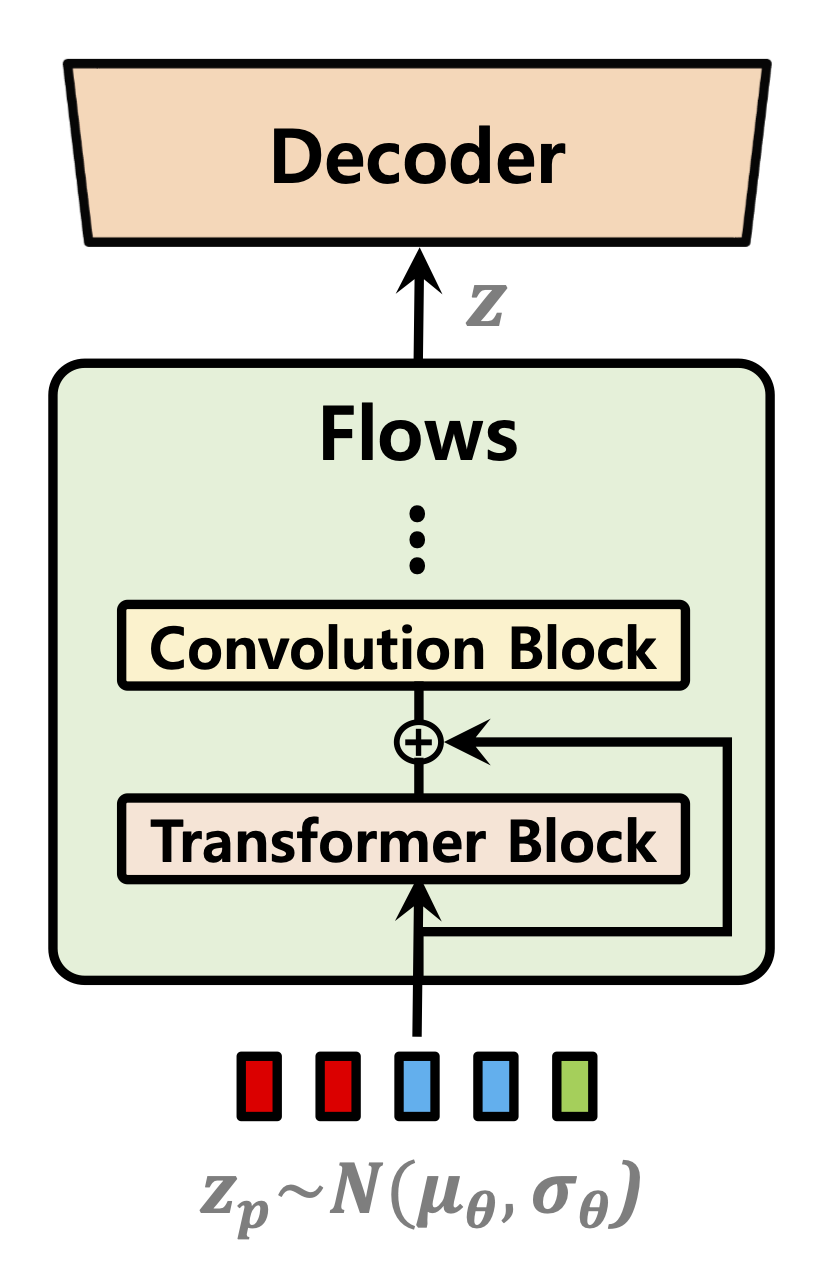 | 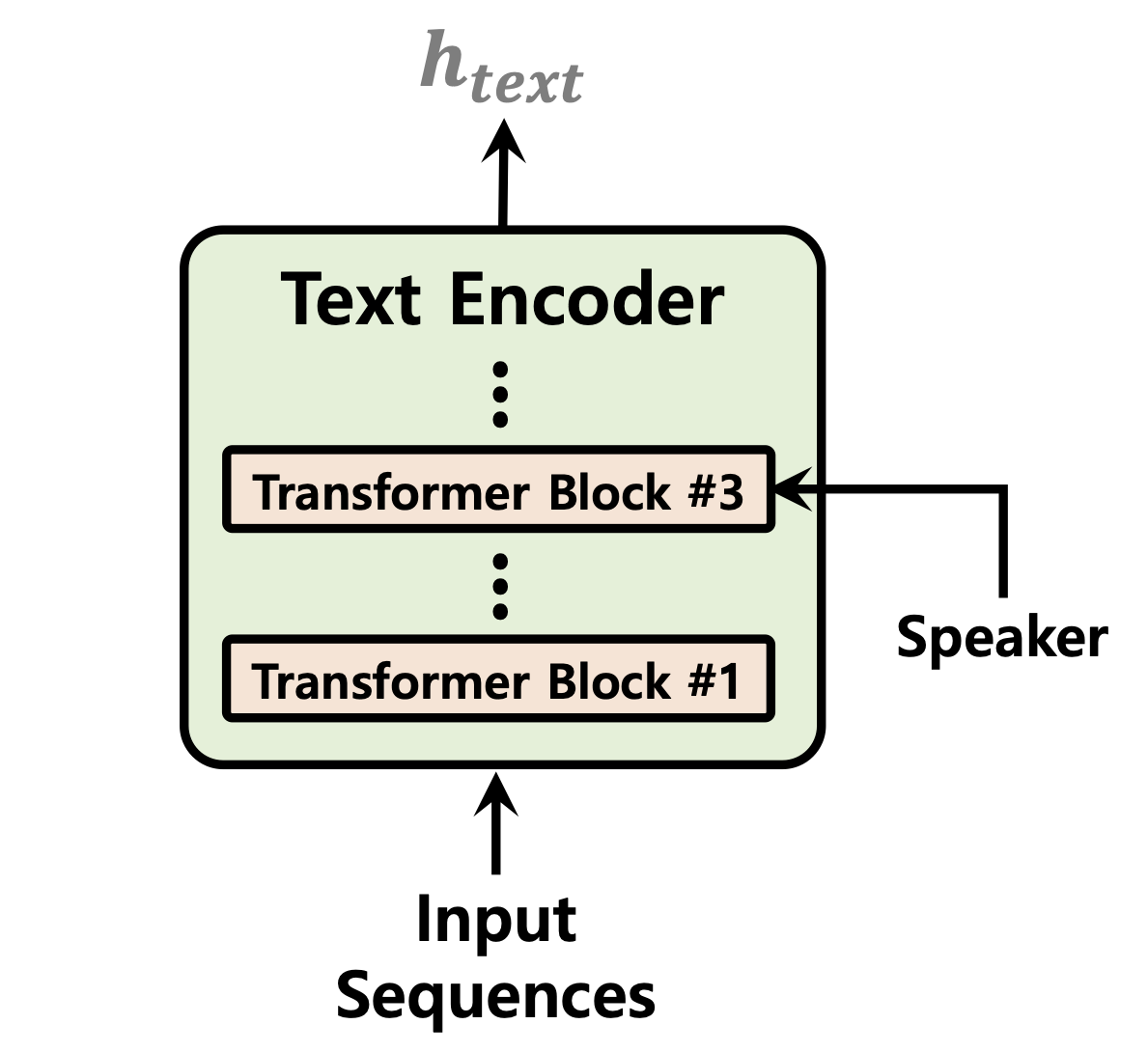 |
[En curso]
Muestra de audio después de 52,000 pasos de capacitación en 1 GPU para el conjunto de datos de Ljspeech: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d7833
Clonar el repositorio
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Esto supone que ha navegado a la raíz vits2 después de clonarla.
Nota: Esto se prueba bajo python3.11 con Conda Env. Para otras versiones de Python, puede encontrar conflictos de versión.
Pytorch 2.0 Consulte los requisitos.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Hay tres opciones entre las que puede elegir: LJ Speech, VCTK o DataSet personalizado.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamltexto preprocesado. Ver preparar/filelists.ipynb
Cambie el nombre o cree un enlace a la carpeta del conjunto de datos.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(Opcional): muestrean los archivos de audio a 22050 Hz. Ver audio_resample.ipynb
Preprocesos de espectrogramas MEL. Ver mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamltexto preprocesado. Ver preparar/filelists.ipynb
Cambie el nombre o cree un enlace a la carpeta del conjunto de datos.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base en datasets y cambiarlo a custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml Nota: Es posible que deba instalar espeak-ng si desea usar phonemize_text Cleaner. Consulte espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseVer Inference.ipynb e Inference_batch.ipynb
[En curso]


