vits2
1.0.0
단일 단계 텍스트 음성 연설 모델은 최근에 적극적으로 연구되었으며 그 결과는 2 단계 파이프 라인 시스템을 능가했습니다. 이전의 단일 단계 모델은 큰 진전을 이루었지만 간헐적 인 부 자연성, 계산 효율 및 음소 전환에 대한 강력한 의존성 측면에서 개선의 여지가 있습니다. 이 작업에서, 우리는 이전 작업의 여러 측면을 개선하여보다 자연스러운 음성을 효율적으로 합성하는 단일 단계 텍스트 연설 모델 인 VITS2를 소개합니다. 우리는 개선 된 구조 및 훈련 메커니즘을 제안하고 제안 된 방법이 자연성을 향상시키는 데 효과적이며, 멀티 스피커 모델에서 언어 특성의 유사성, 훈련 및 추론의 효율성을 제시합니다. 또한, 우리는 이전 작품에서 음소 전환에 대한 강력한 의존성이 우리의 방법으로 크게 줄어들 수 있음을 보여줍니다.
데모 : https://vits-2.github.io/demo/
종이 : https://arxiv.org/abs/2307.16430
VITS2의 비공식 구현. 이것은 진행중인 작업입니다. 자세한 내용은 TODO를 참조하십시오.
| 기간 예측 변수 | 정상화 흐름 | 텍스트 인코더 |
|---|---|---|
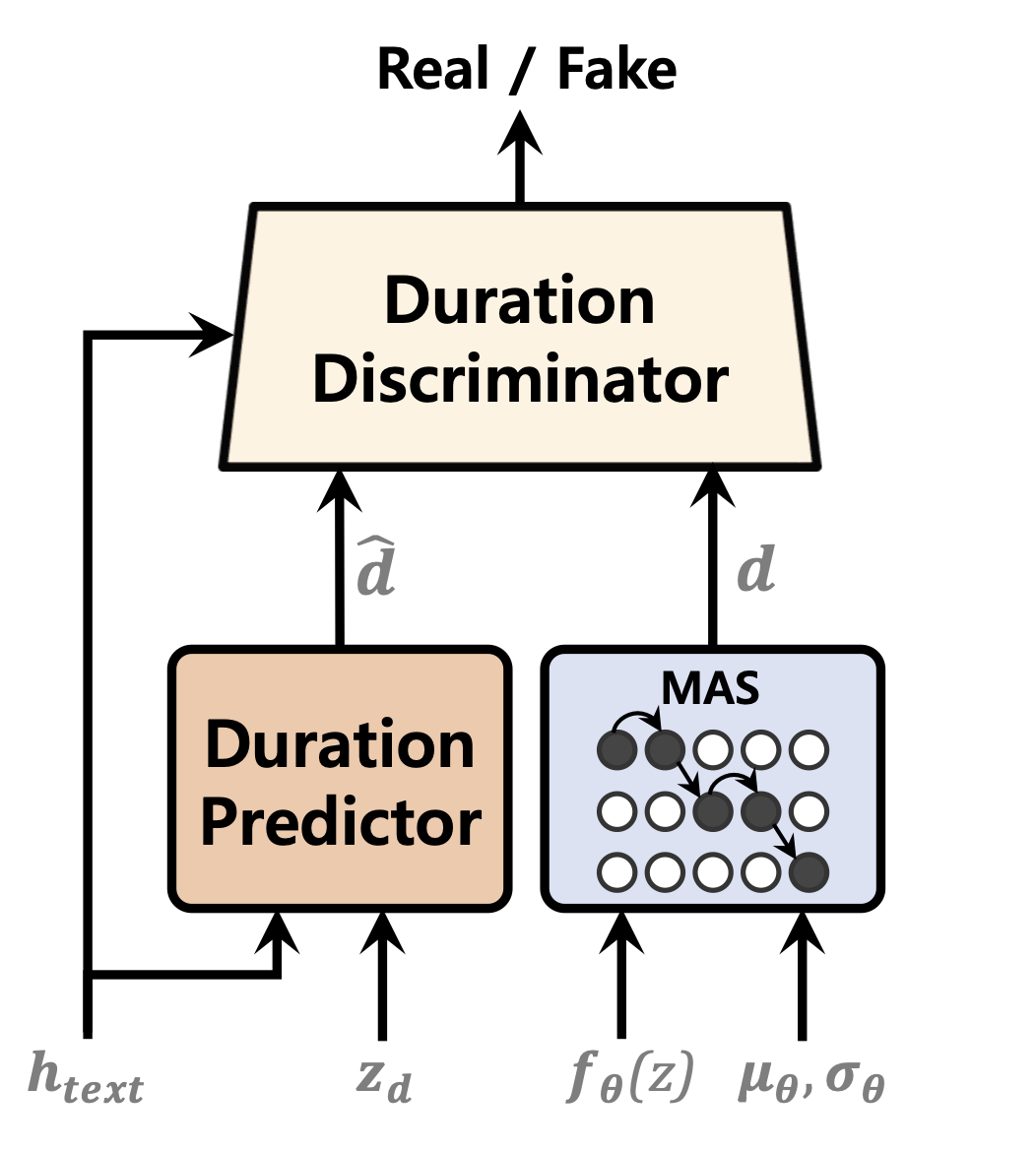 | 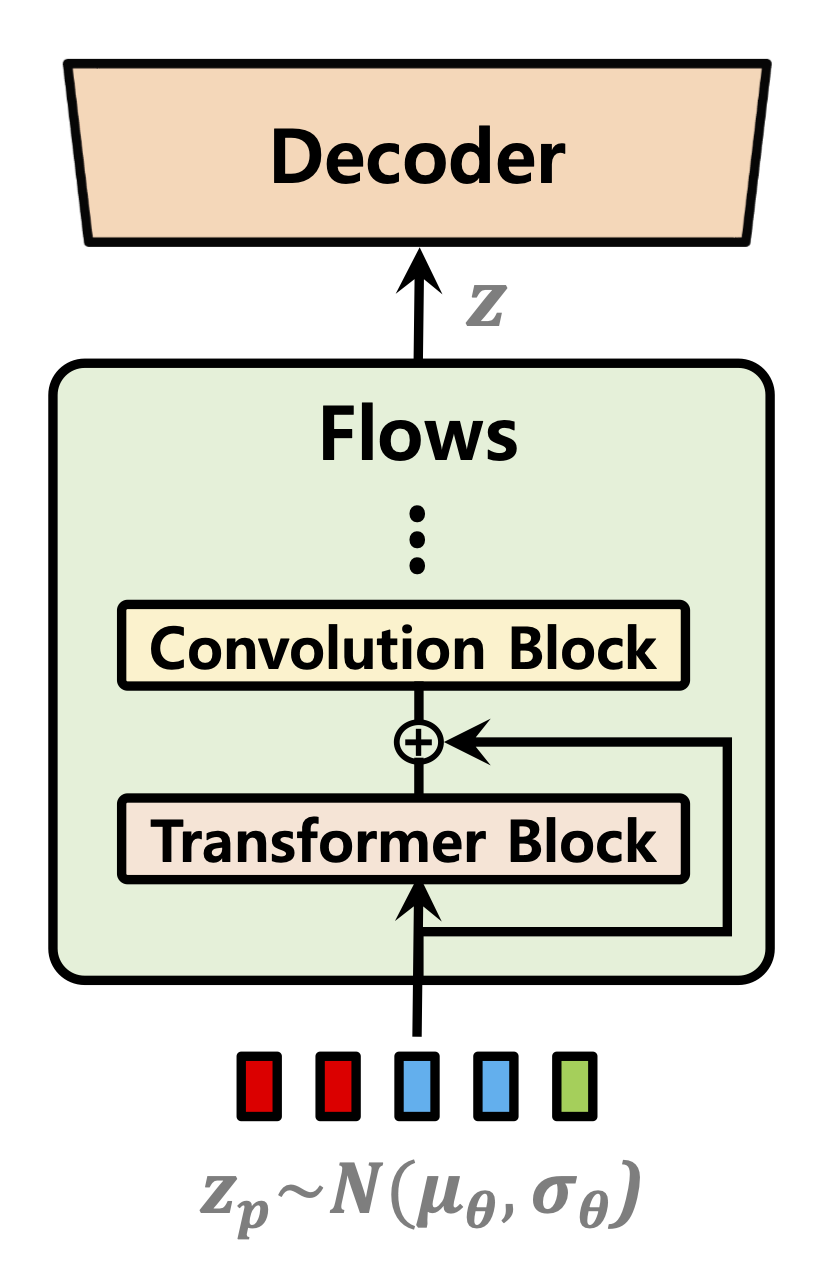 | 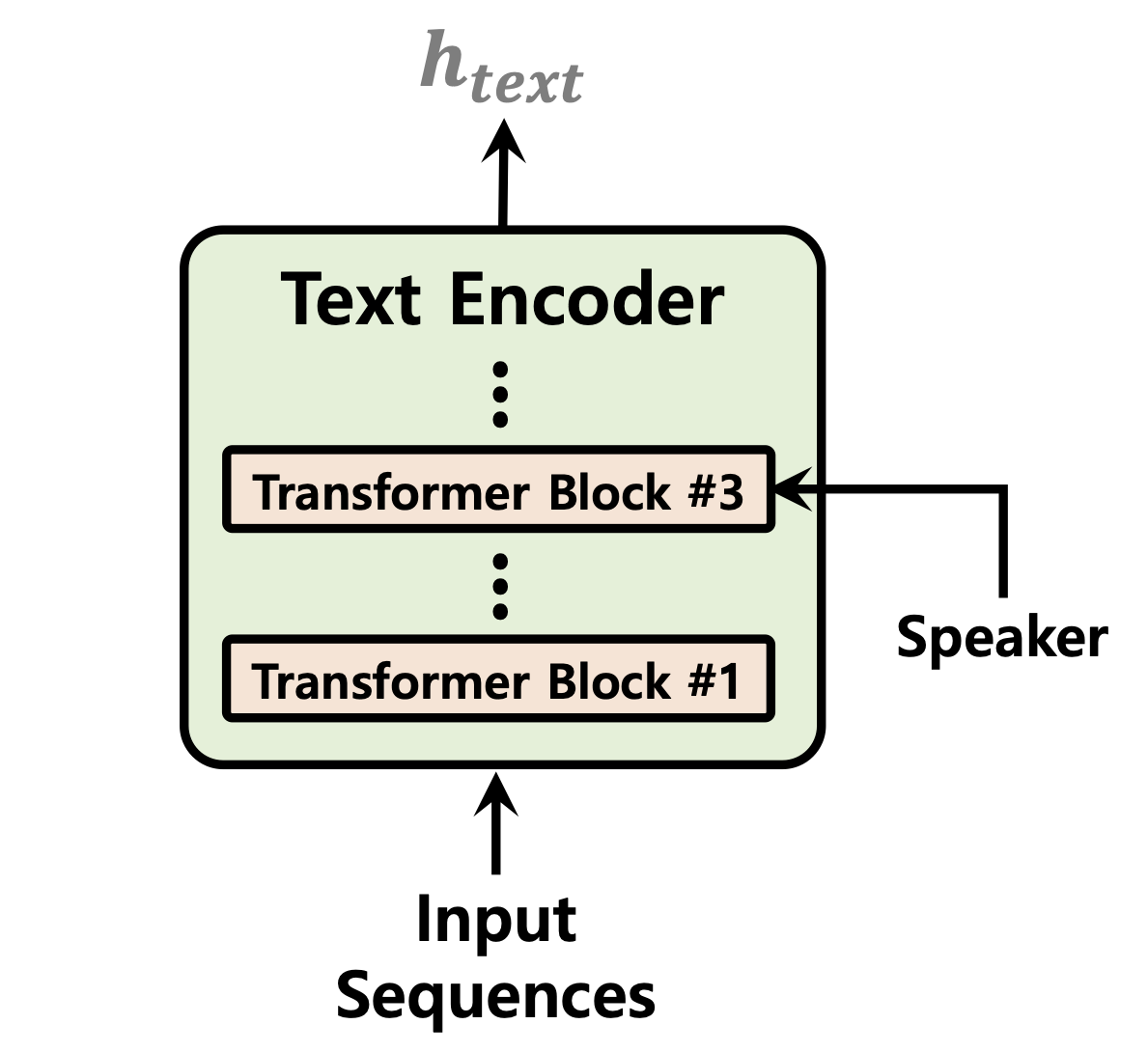 |
[진행 중]
ljspeech 데이터 세트에 대한 1 GPU에 대한 52,000 단계의 훈련 후 오디오 샘플 : https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d783
레포를 복제하십시오
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 이것은 클로닝 후 vits2 뿌리로 탐색했다고 가정합니다.
참고 : 이것은 Conda Env와 함께 python3.11 에 따라 테스트됩니다. 다른 Python 버전의 경우 버전 충돌이 발생할 수 있습니다.
Pytorch 2.0 요구 사항을 참조하십시오 .txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " LJ Speech, VCTK 또는 사용자 정의 데이터 세트의 세 가지 옵션이 있습니다.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yaml전처리 텍스트. 준비/filelists.ipynb를 참조하십시오
데이터 세트 폴더에 대한 이름을 바꾸거나 만듭니다.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(선택 사항) : 오디오 파일을 22050 Hz로 다운 샘플링합니다. Audio_resample.ipynb를 참조하십시오
전처리 멜 스피어 그램. mel_transform.py를 참조하십시오
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yaml전처리 텍스트. 준비/filelists.ipynb를 참조하십시오
데이터 세트 폴더에 대한 이름을 바꾸거나 만듭니다.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2datasets 디렉토리에서 ljs_base 복제하고 custom_base 로 이름을 바꿉니다.config.yaml 에서 다음 필드를 변경하십시오. data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml 참고 : phonemize_text Cleaner를 사용하려면 espeak-ng 설치해야 할 수도 있습니다. ESPEAK-NG를 참조하십시오
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_base추론 .ipynb 및 inference_batch.ipynb를 참조하십시오
[진행 중]


