vits2
1.0.0
Les modèles de texte à dissolution à un étage ont été activement étudiés récemment et leurs résultats ont surpassé les systèmes de pipelines à deux étapes. Bien que le modèle précédent à un stade ait fait de grands progrès, il y a une place à l'amélioration en termes de sa nature intermittente, de son efficacité de calcul et de sa forte dépendance à la conversion des phonèmes. Dans ce travail, nous introduisons VITS2, un modèle de texte à dispection à un étage qui synthétise efficacement un discours plus naturel en améliorant plusieurs aspects des travaux précédents. Nous proposons des structures et des mécanismes d'entraînement améliorés et présentons que les méthodes proposées sont efficaces pour améliorer le naturel, la similitude des caractéristiques de la parole dans un modèle multi-haut-parleurs et l'efficacité de l'entraînement et de l'inférence. En outre, nous démontrons que la forte dépendance à la conversion des phonèmes dans les travaux précédents peut être considérablement réduite avec notre méthode, ce qui permet une approche à un étage de bout en bout.
Demo: https://vits-2.github.io/demo/
Papier: https://arxiv.org/abs/2307.16430
Implémentation non officielle de VITS2. Ceci est un travail en cours. Veuillez vous référer à TODO pour plus de détails.
| Prédicteur de durée | Normaliser les flux | Encodeur de texte |
|---|---|---|
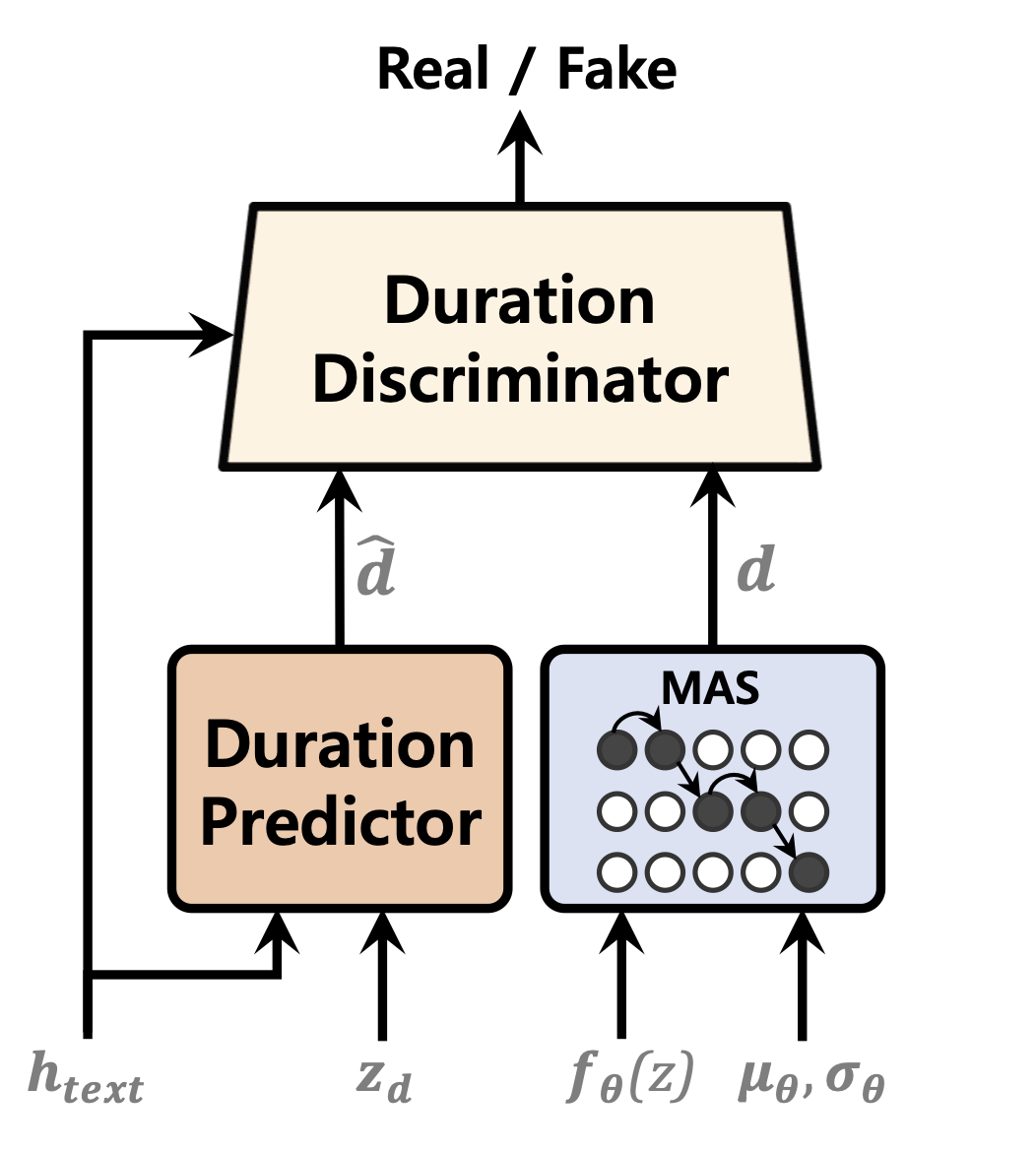 | 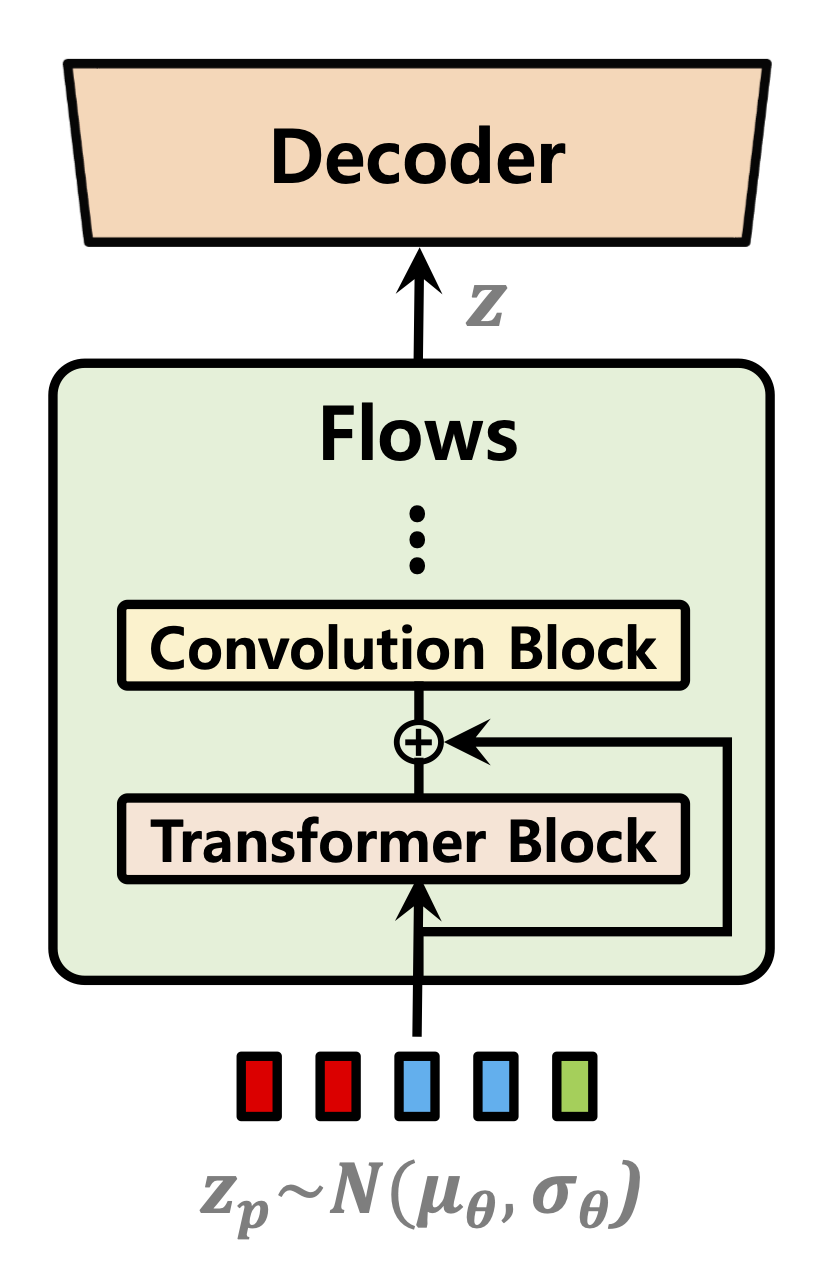 | 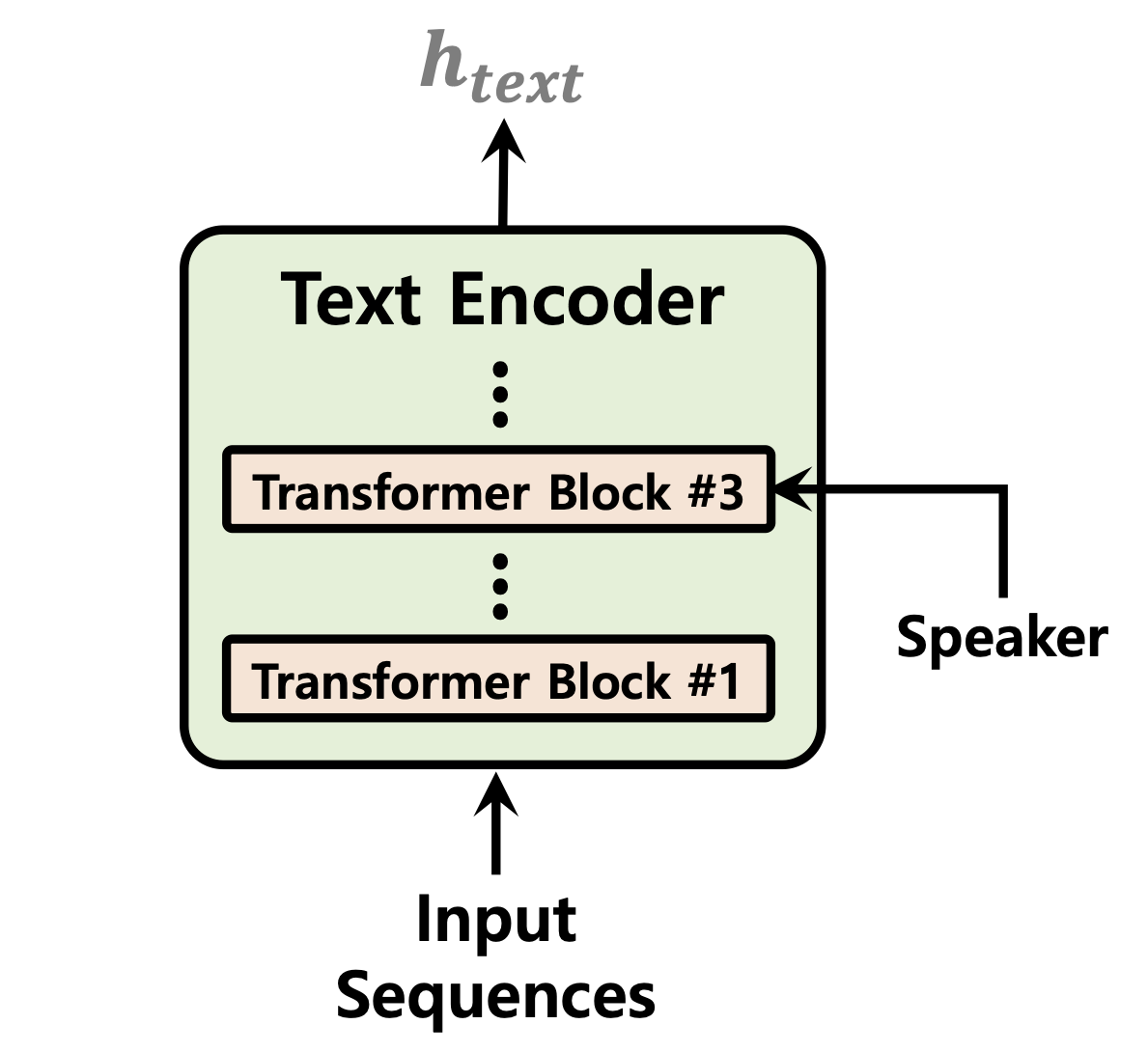 |
[En cours]
Échantillon audio après 52 000 étapes de formation sur 1 GPU pour LJSpeech Dataset: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d783
Cloner le repo
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Cela suppose que vous avez navigué vers la racine vits2 après l'avoir cloné.
Remarque: Ceci est testé sous python3.11 avec conda env. Pour d'autres versions Python, vous pourriez rencontrer des conflits de version.
Pytorch 2.0 Veuillez référer les exigences.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Il existe trois options que vous pouvez choisir: LJ Speech, VCTK ou DataSet personnalisé.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamltexte prétraitement. Voir Préparer / FileLististes.Ipynb
renommer ou créer un lien vers le dossier de l'ensemble de données.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(Facultatif): réduisez les fichiers audio à 22050 Hz. Voir audio_resample.ipynb
Spectrogrammes de MEL du prétraitement. Voir mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamltexte prétraitement. Voir Préparer / FileLististes.Ipynb
renommer ou créer un lien vers le dossier de l'ensemble de données.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base dans datasets et renomment-le à custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml Remarque: vous devrez peut-être installer espeak-ng si vous souhaitez utiliser un nettoyant phonemize_text . Veuillez référer Espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseVoir inférence.ipynb et inférence_batch.ipynb
[En cours]


