vits2
1.0.0
Os modelos de texto para fala em estágio foi estudado recentemente recentemente e seus resultados superaram os sistemas de pipeline de duas etapas. Embora o modelo anterior tenha feito um grande progresso, há espaço para melhorias em termos de sua não natura intermitente, eficiência computacional e forte dependência da conversão do fonema. Neste trabalho, introduzimos o VITS2, um modelo de texto em fala em estágio que sintetiza com eficiência um discurso mais natural, melhorando vários aspectos do trabalho anterior. Propomos estruturas e mecanismos de treinamento aprimorados e apresentamos que os métodos propostos são eficazes para melhorar a naturalidade, a similaridade das características da fala em um modelo de vários falantes e a eficiência do treinamento e da inferência. Além disso, demonstramos que a forte dependência da conversão do fonema em trabalhos anteriores pode ser significativamente reduzida com o nosso método, o que permite uma abordagem de estágio único de ponta a ponta.
Demo: https://vits-2.github.io/demo/
Papel: https://arxiv.org/abs/2307.16430
Implementação não oficial de Vits2. Este é um trabalho em andamento. Consulte o TODO para obter mais detalhes.
| Predictor de duração | Fluxos normalizando | Codificador de texto |
|---|---|---|
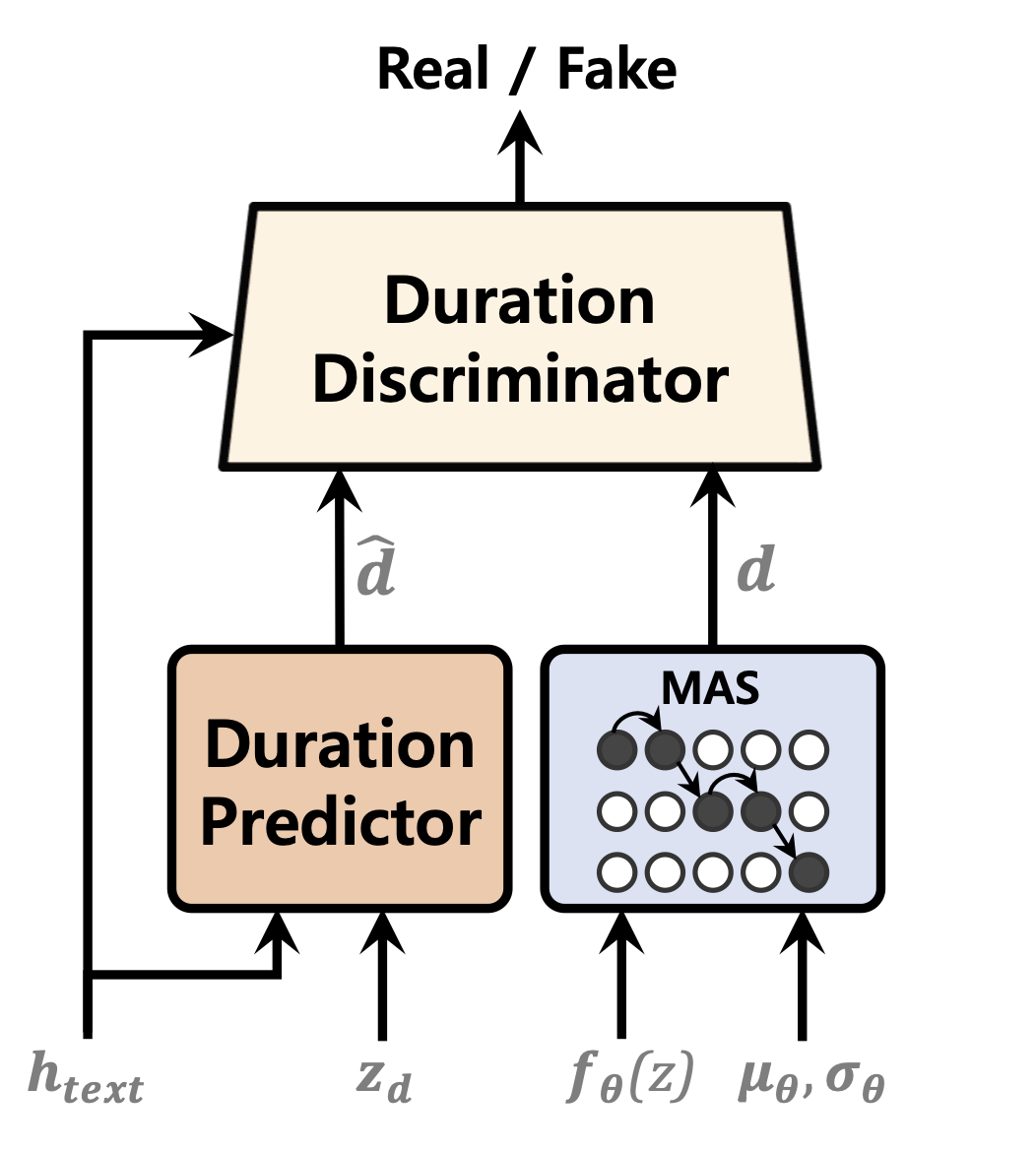 | 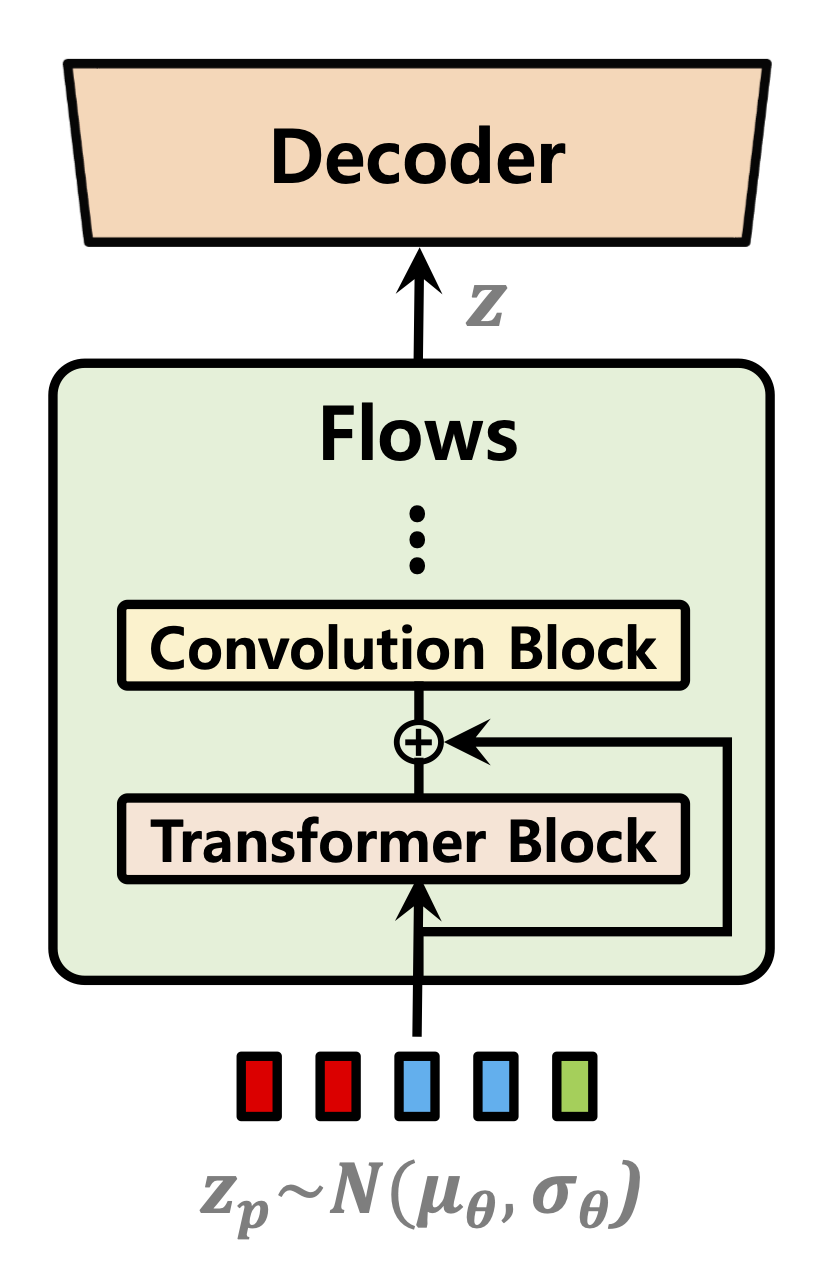 | 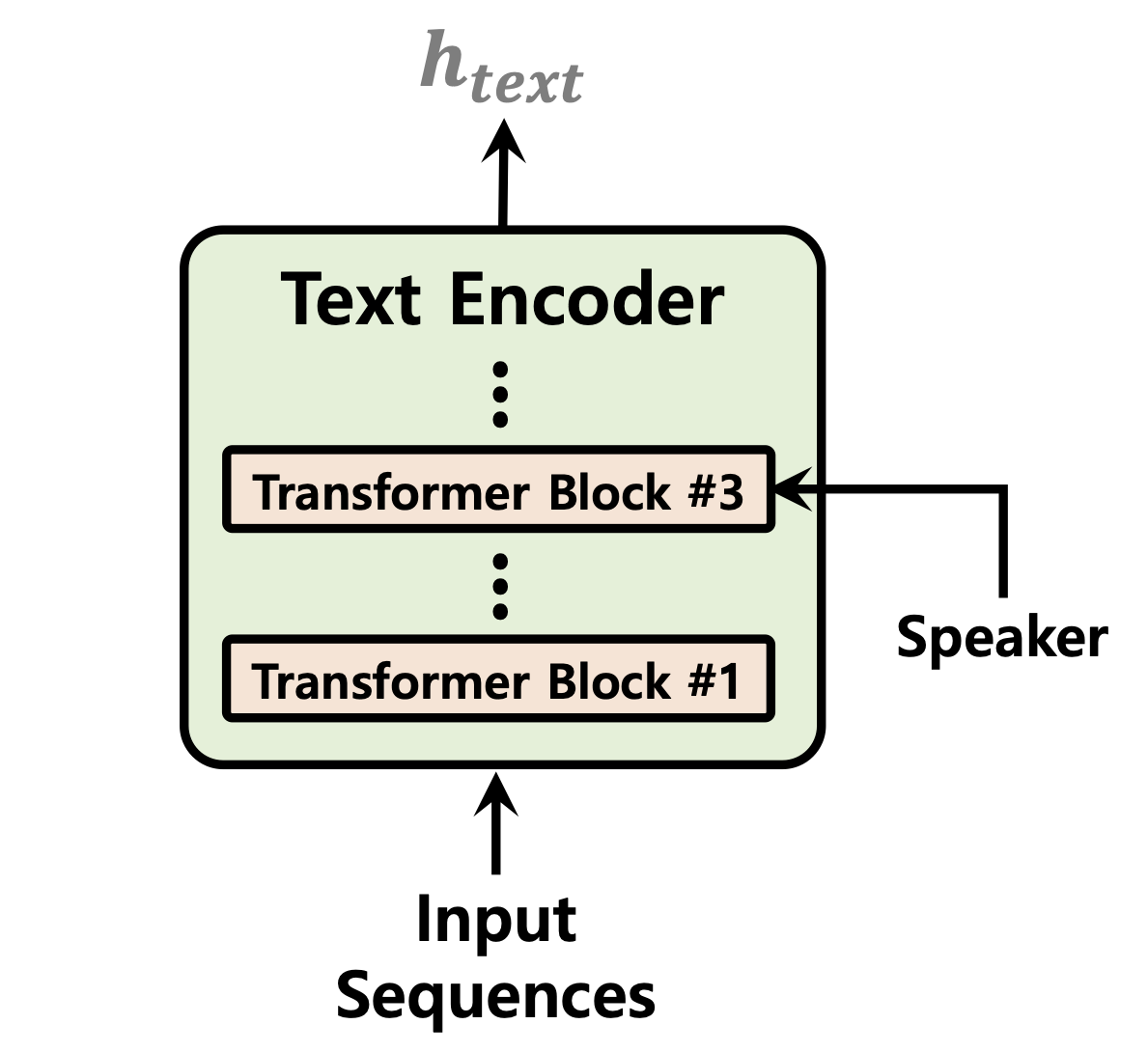 |
[Em andamento]
Amostra de áudio após 52.000 etapas de treinamento em 1 GPU para LJSpeech DataSet: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d783
Clone o repo
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Isso supõe que você tenha navegado na raiz vits2 após cloná -la.
NOTA: Isso é testado em python3.11 com conda Env. Para outras versões do Python, você pode encontrar conflitos de versão.
Pytorch 2.0 Consulte os requisitos.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Existem três opções que você pode escolher: LJ Speech, VCTK ou DataSet personalizado.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamltexto pré -processado. Consulte Prepare/filelists.ipynb
Renomeie ou crie um link para a pasta do conjunto de dados.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(Opcional): Downsample os arquivos de áudio para 22050 Hz. Consulte Audio_resample.ipynb
pré-processamento Mel-espectrogramas. Veja mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamltexto pré -processado. Consulte Prepare/filelists.ipynb
Renomeie ou crie um link para a pasta do conjunto de dados.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base no diretório datasets e renomeie -o para custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml NOTA: Pode ser necessário instalar espeak-ng se desejar usar phonemize_text Cleaner. Por favor, consulte Espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseVeja inference.ipynb e inference_batch.ipynb
[Em andamento]


