vits2
1.0.0
Model teks-ke-speech tunggal telah dipelajari secara aktif baru-baru ini, dan hasilnya telah mengungguli sistem pipa dua tahap. Meskipun model tahap tunggal sebelumnya telah membuat kemajuan besar, ada ruang untuk perbaikan dalam hal ketidaksopanan yang terputus-putus, efisiensi komputasi, dan ketergantungan yang kuat pada konversi fonem. Dalam karya ini, kami memperkenalkan VITS2, model teks-ke-speech tunggal yang secara efisien mensintesis pidato yang lebih alami dengan meningkatkan beberapa aspek dari karya sebelumnya. Kami mengusulkan peningkatan struktur dan mekanisme pelatihan dan menunjukkan bahwa metode yang diusulkan efektif dalam meningkatkan kealamian, kesamaan karakteristik bicara dalam model multi-speaker, dan efisiensi pelatihan dan inferensi. Selain itu, kami menunjukkan bahwa ketergantungan yang kuat pada konversi fonem dalam karya sebelumnya dapat dikurangi secara signifikan dengan metode kami, yang memungkinkan pendekatan tahap tunggal ujung ke ujung.
Demo: https://vits-2.github.io/demo/
Kertas: https://arxiv.org/abs/2307.16430
Implementasi Vits2 tidak resmi. Ini adalah pekerjaan yang sedang berlangsung. Silakan merujuk ke Todo untuk detail lebih lanjut.
| Prediktor durasi | Aliran normalisasi | Encoder Teks |
|---|---|---|
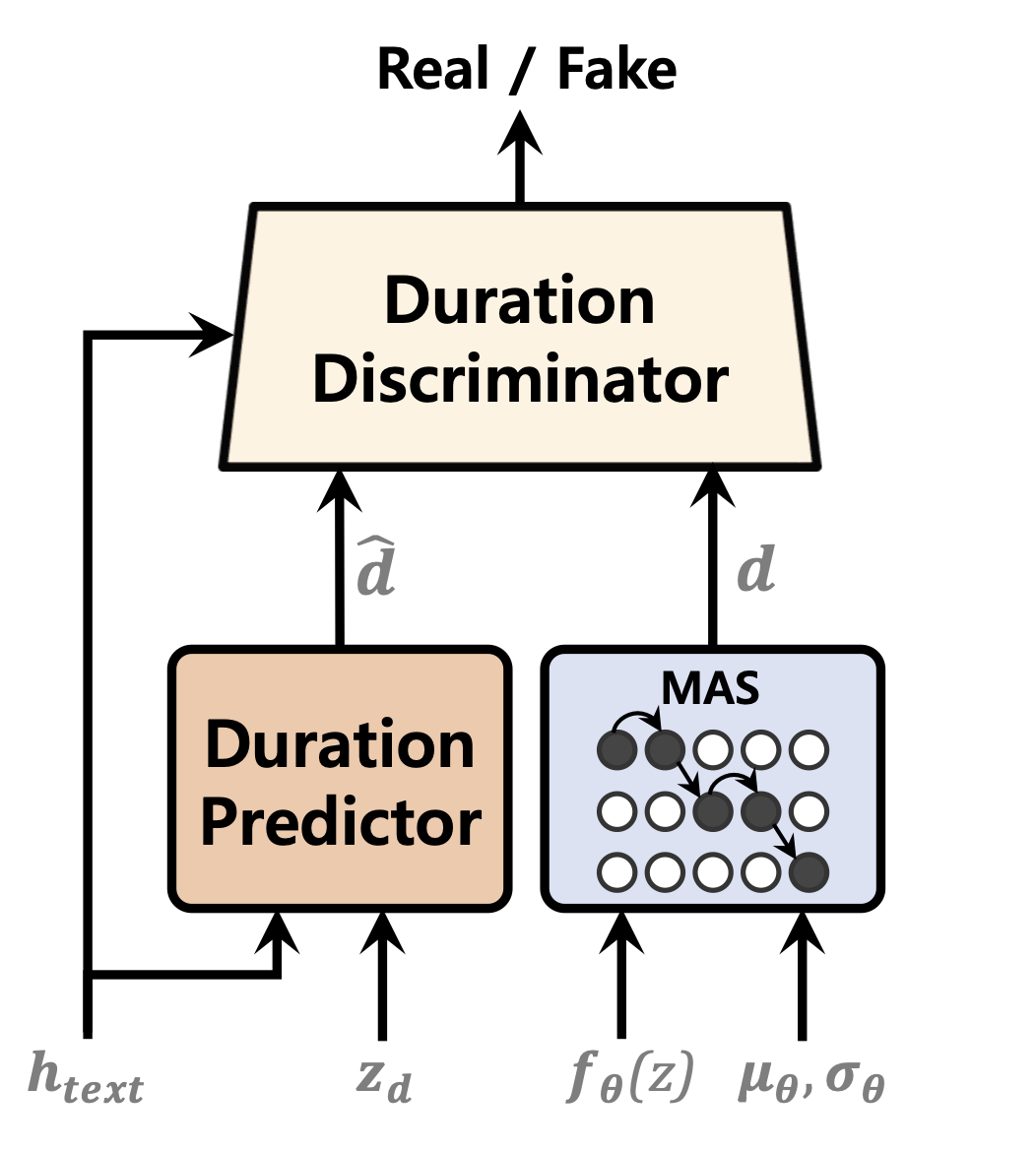 | 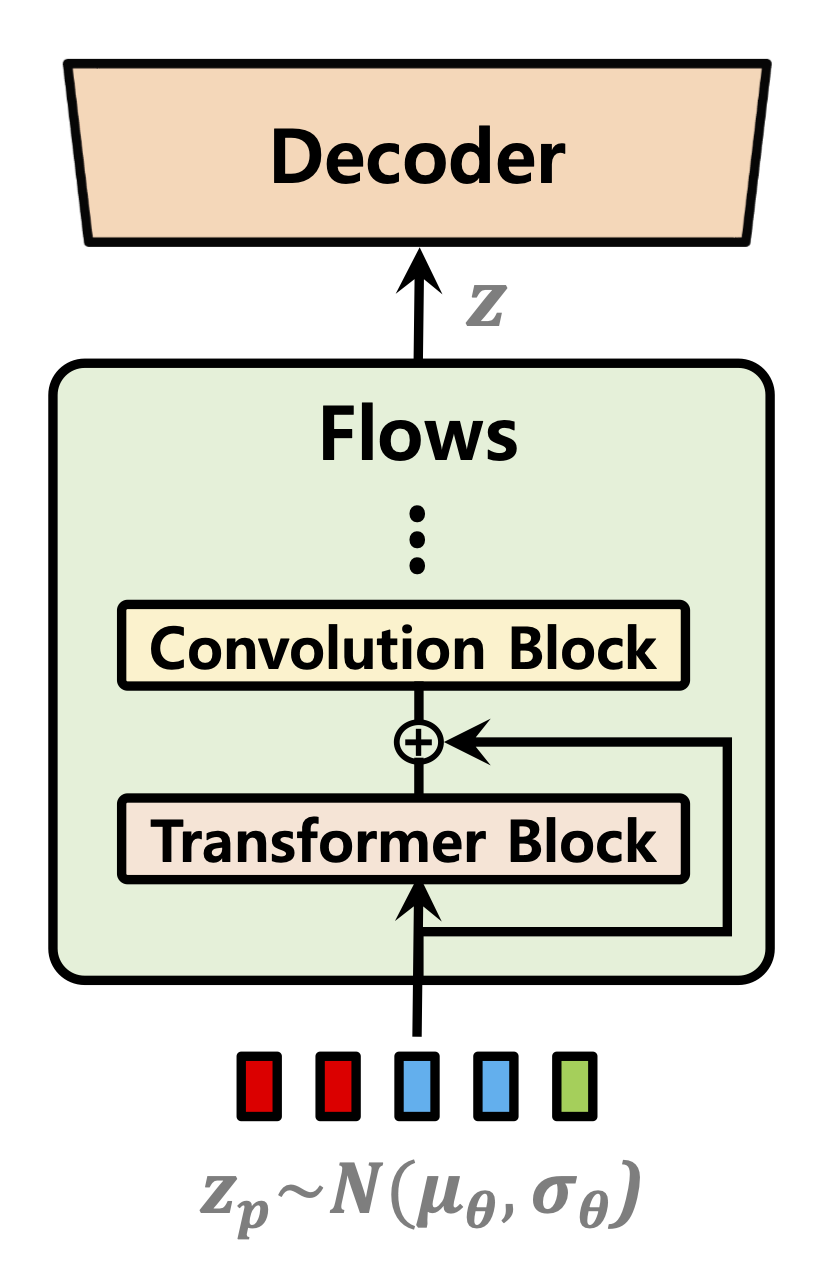 | 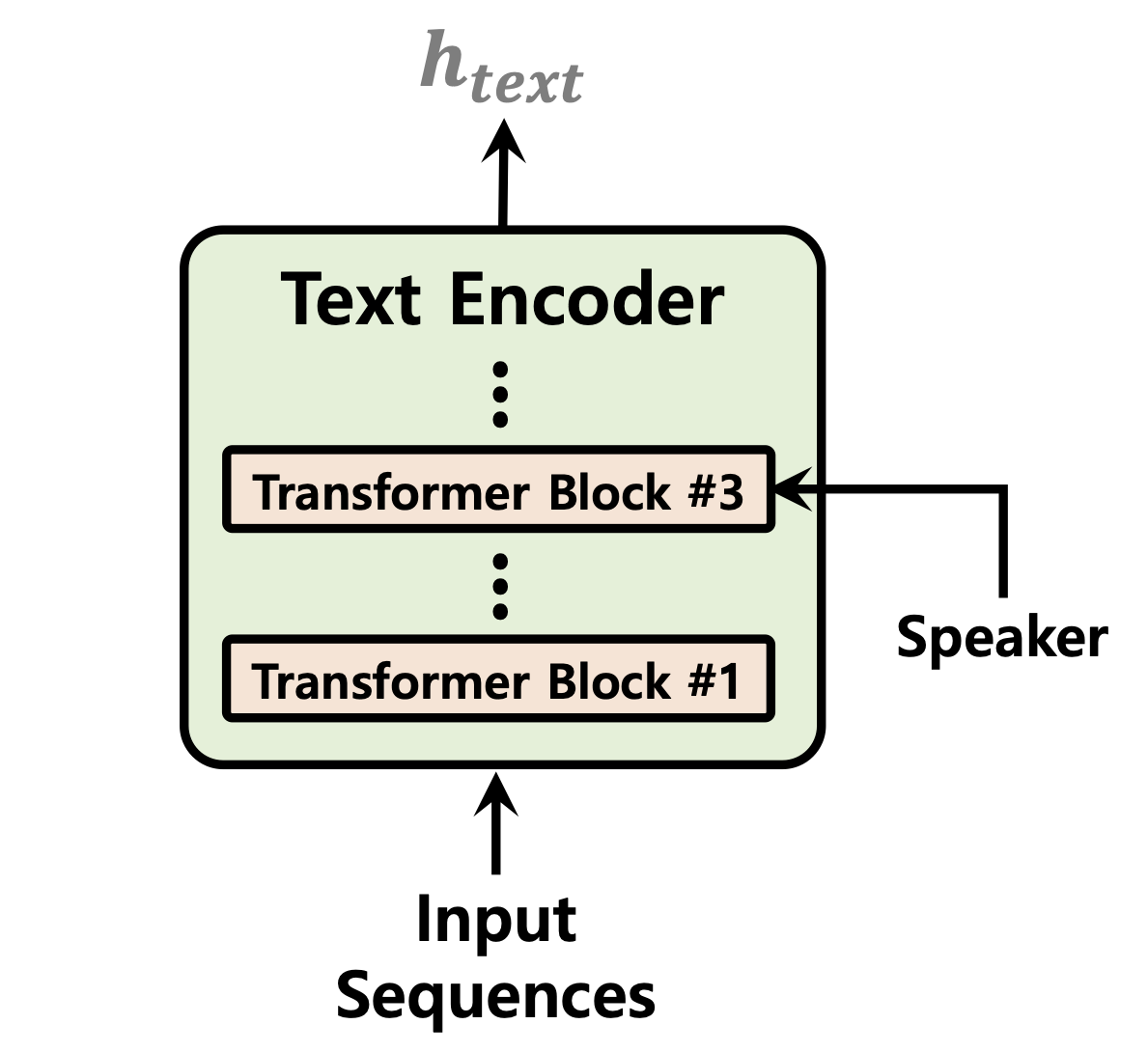 |
[Sedang berlangsung]
Sampel audio setelah 52.000 langkah pelatihan pada 1 GPU untuk dataset ljspeech: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d783
Kloning repo
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Ini dengan asumsi Anda telah menavigasi ke root vits2 setelah mengkloningnya.
Catatan: Ini diuji di bawah python3.11 dengan conda env. Untuk versi Python lainnya, Anda mungkin menghadapi konflik versi.
Pytorch 2.0 silakan merujuk persyaratan.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Ada tiga opsi yang dapat Anda pilih: LJ Speech, VCTK, atau Dataset Kustom.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlteks preprocess. Lihat Siapkan/Filelist.ipynb
Ganti nama atau buat tautan ke folder dataset.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(Opsional): Downsampel file audio ke 22050 Hz. Lihat audio_resample.ipynb
preprocess Mel-spectrograms. Lihat Mel_Transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlteks preprocess. Lihat Siapkan/Filelist.ipynb
Ganti nama atau buat tautan ke folder dataset.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base di direktori datasets dan ganti namanya menjadi custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml Catatan: Anda mungkin perlu menginstal espeak-ng jika Anda ingin menggunakan phonemize_text cleaner. Silakan merujuk Espeak-Ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseLihat inferensi.ipynb dan inference_batch.ipynb
[Sedang berlangsung]


