vits2
1.0.0
Одноступенчатые модели текста в речь были активно изучены недавно, и их результаты превзошли двухэтапные трубопроводные системы. Хотя предыдущая одноступенчатая модель добилась большого прогресса, существует место для улучшения с точки зрения ее прерывистой неестественности, вычислительной эффективности и сильной зависимости от преобразования фонем. В этой работе мы вводим VITS2, одноэтапную модель текста в речь, которая эффективно синтезирует более естественную речь, улучшая несколько аспектов предыдущей работы. Мы предлагаем улучшенные структуры и механизмы обучения и представляем, что предлагаемые методы эффективны для улучшения естественности, сходства речевых характеристик в модели с несколькими динамиками и эффективность обучения и вывода. Кроме того, мы демонстрируем, что сильная зависимость от преобразования фонем в предыдущих работах может быть значительно снижена с помощью нашего метода, что позволяет полностью запланировать одноступенчатый подход.
Демо: https://vits-2.github.io/demo/
Бумага: https://arxiv.org/abs/2307.16430
Неофициальная реализация VITS2. Это работа в процессе. Пожалуйста, обратитесь к TODO для получения более подробной информации.
| Продолжительность предиктора | Нормализация потоков | Текстовый энкодер |
|---|---|---|
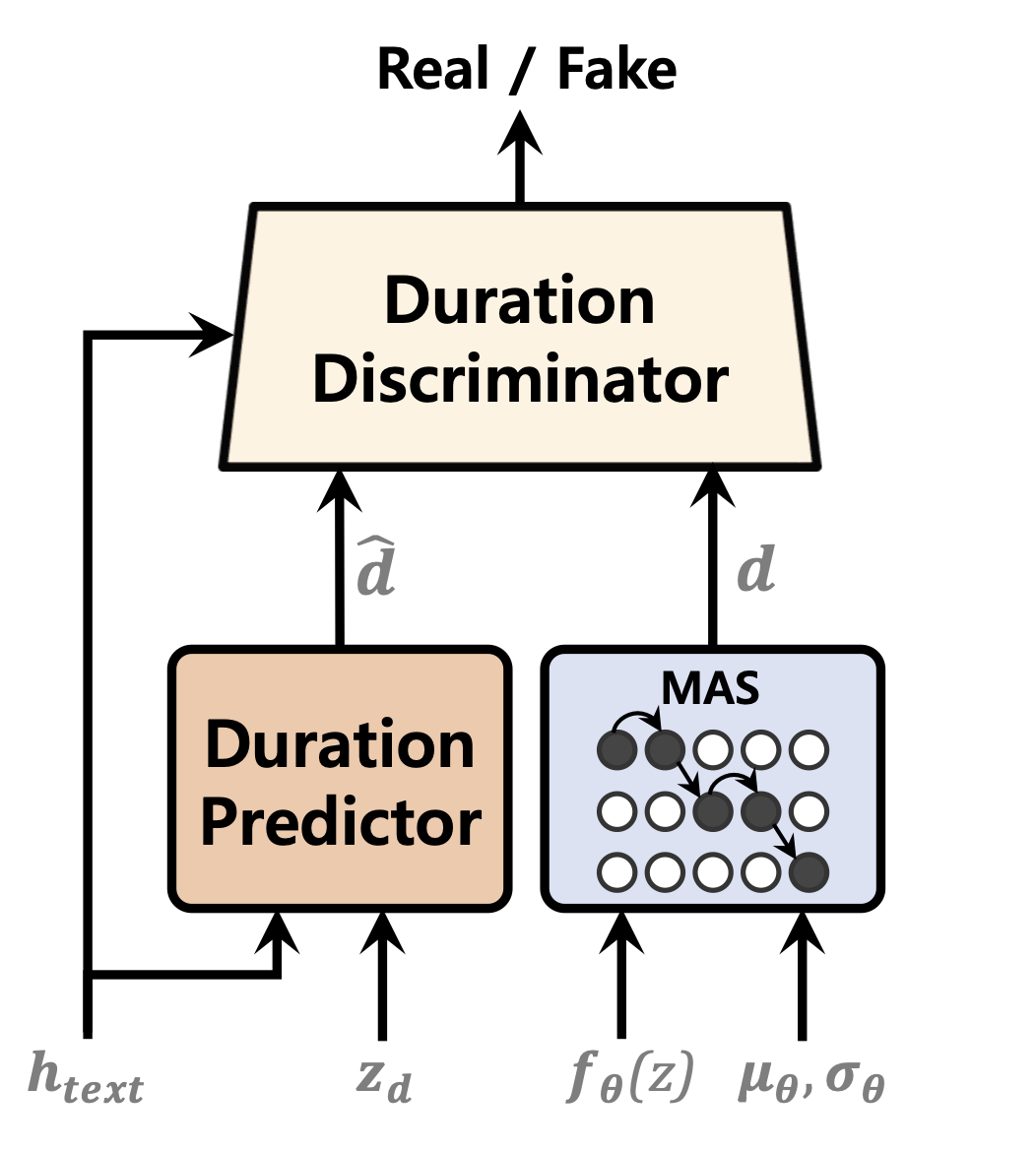 | 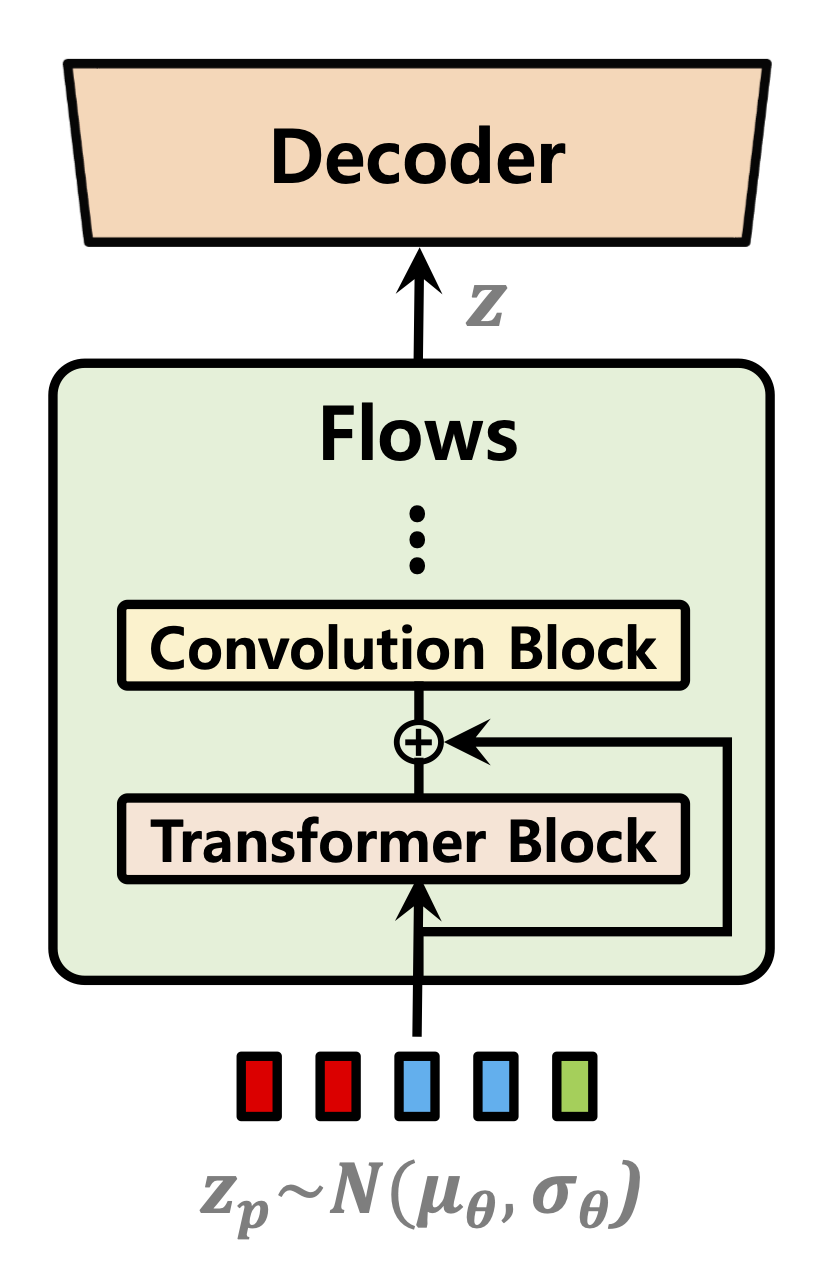 | 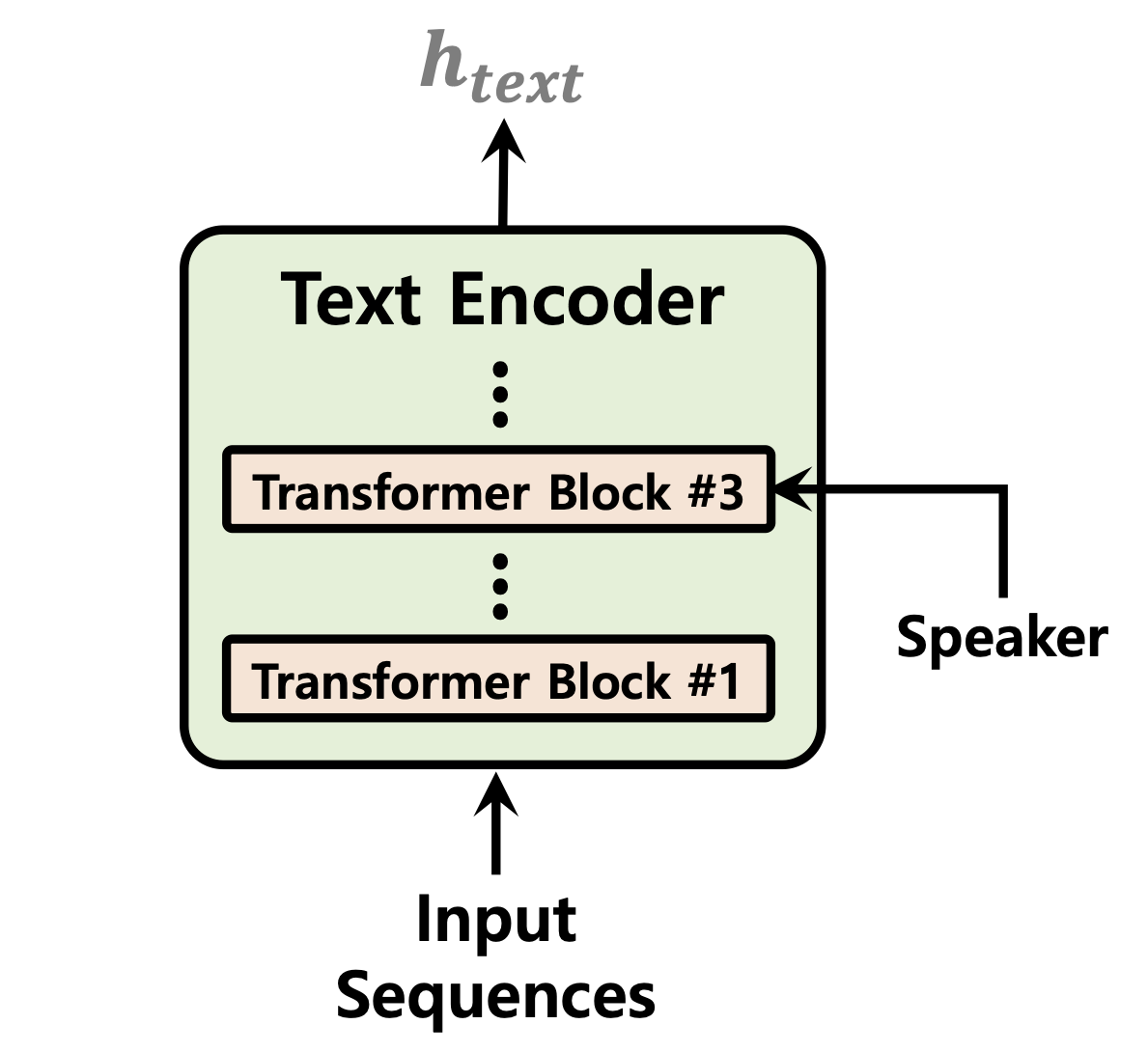 |
[В ходе выполнения]
Образец аудио после 52 000 этапов обучения на 1 графическом процессоре для набора данных LJSPEECH: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96e7-ab53bf50d783
Клонировать репо
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 Это предполагает, что вы перемещались до корня vits2 после его клонирования.
Примечание: это тестируется под python3.11 с Conda Env. Для других версий Python вы можете столкнуться с конфликтами версий.
Pytorch 2.0 обратитесь к требованиям.txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " Есть три варианта, которые вы можете выбрать: LJ Speech, VCTK или пользовательский набор данных.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlПрепроцесс текст. См. Prepare/filelists.ipynb
Переименовать или создать ссылку на папку набора данных.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(необязательно): Downsample Audio -файлы до 22050 Гц. См. Audio_Resample.ipynb
Предварительная обработка мель-спектрограммы. См. Mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlПрепроцесс текст. См. Prepare/filelists.ipynb
Переименовать или создать ссылку на папку набора данных.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base в каталоге datasets и переименование в custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml Примечание: вам может потребоваться установить espeak-ng если вы хотите использовать phonemize_text Cleaner. Пожалуйста, обратитесь к Espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseСм. Spece.ipynb and spence_batch.ipynb
[В ходе выполнения]


