vits2
1.0.0
โมเดลข้อความเป็นระยะเดียวได้รับการศึกษาอย่างแข็งขันเมื่อเร็ว ๆ นี้และผลลัพธ์ของพวกเขาได้รับการปรับปรุงระบบท่อส่งสองขั้นตอน แม้ว่าโมเดลเวทีเดี่ยวก่อนหน้านี้มีความคืบหน้าอย่างมาก แต่ก็มีช่องว่างสำหรับการปรับปรุงในแง่ของความผิดธรรมชาติที่ไม่ต่อเนื่องประสิทธิภาพการคำนวณและการพึ่งพาการแปลงฟอนิมอย่างมาก ในงานนี้เราแนะนำ VITS2 ซึ่งเป็นโมเดลข้อความเป็นระยะเดียวที่สังเคราะห์การพูดที่เป็นธรรมชาติมากขึ้นโดยการปรับปรุงหลายแง่มุมของงานก่อนหน้านี้ เราเสนอโครงสร้างที่ดีขึ้นและกลไกการฝึกอบรมและนำเสนอว่าวิธีการที่เสนอนั้นมีประสิทธิภาพในการปรับปรุงความเป็นธรรมชาติความคล้ายคลึงกันของลักษณะการพูดในแบบจำลองหลายลำโพงและประสิทธิภาพของการฝึกอบรมและการอนุมาน นอกจากนี้เราแสดงให้เห็นว่าการพึ่งพาการแปลงฟอนิมในงานก่อนหน้านี้สามารถลดลงอย่างมีนัยสำคัญด้วยวิธีการของเราซึ่งช่วยให้วิธีการขั้นตอนเดียวแบบครบวงจรอย่างเต็มที่
ตัวอย่าง: https://vits-2.github.io/demo/
กระดาษ: https://arxiv.org/abs/2307.16430
การใช้งานอย่างไม่เป็นทางการของ VITS2 นี่คืองานที่กำลังดำเนินการ โปรดดูที่ Todo สำหรับรายละเอียดเพิ่มเติม
| ตัวทำนายระยะเวลา | การทำให้ไหลเป็นปกติ | ตัวเข้ารหัสข้อความ |
|---|---|---|
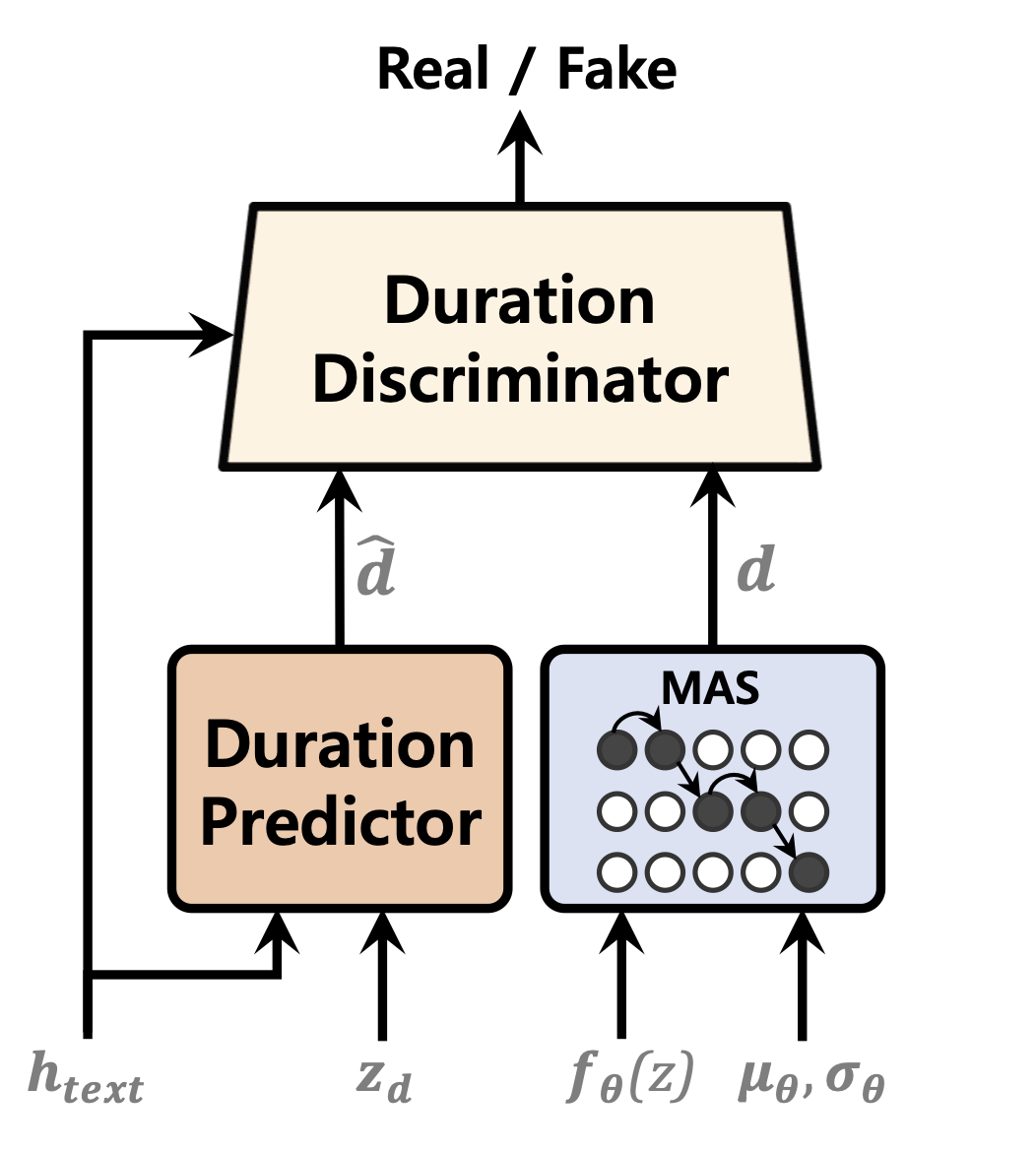 | 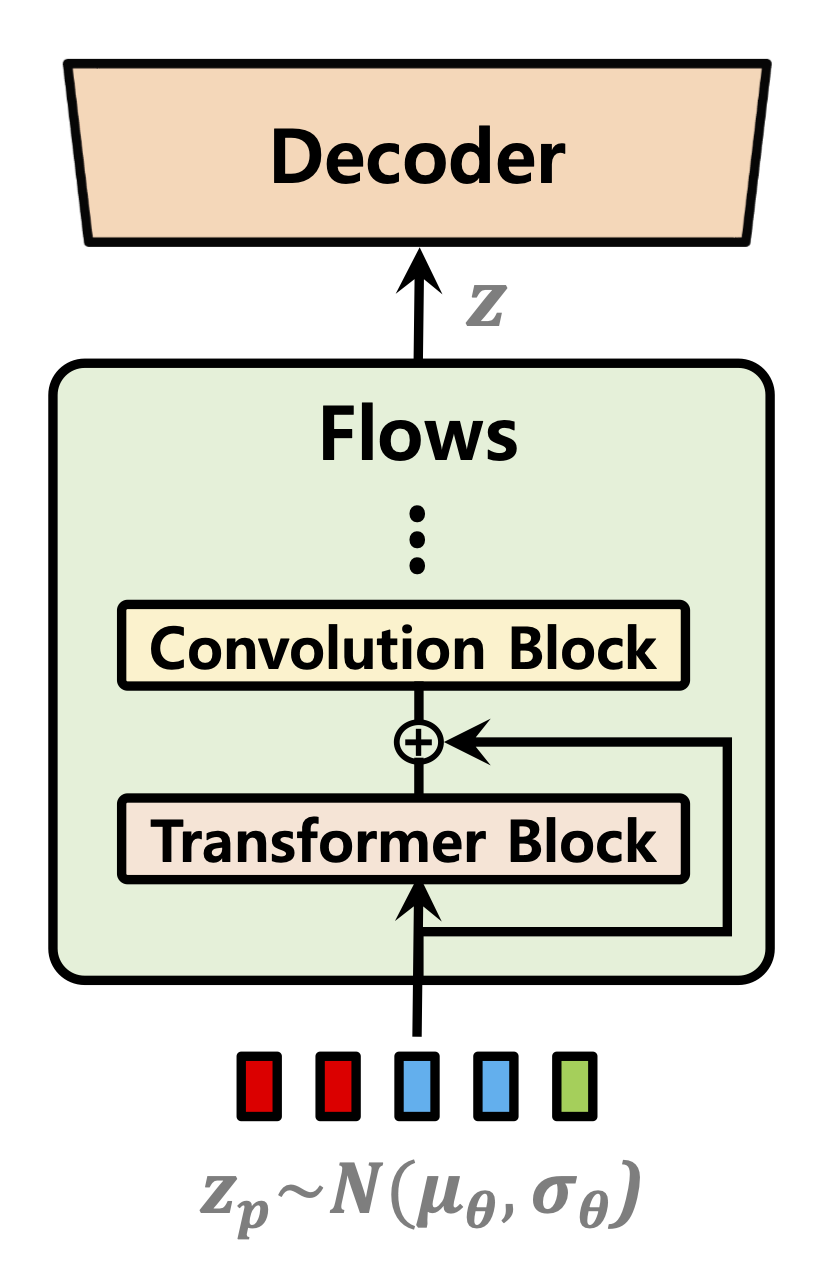 | 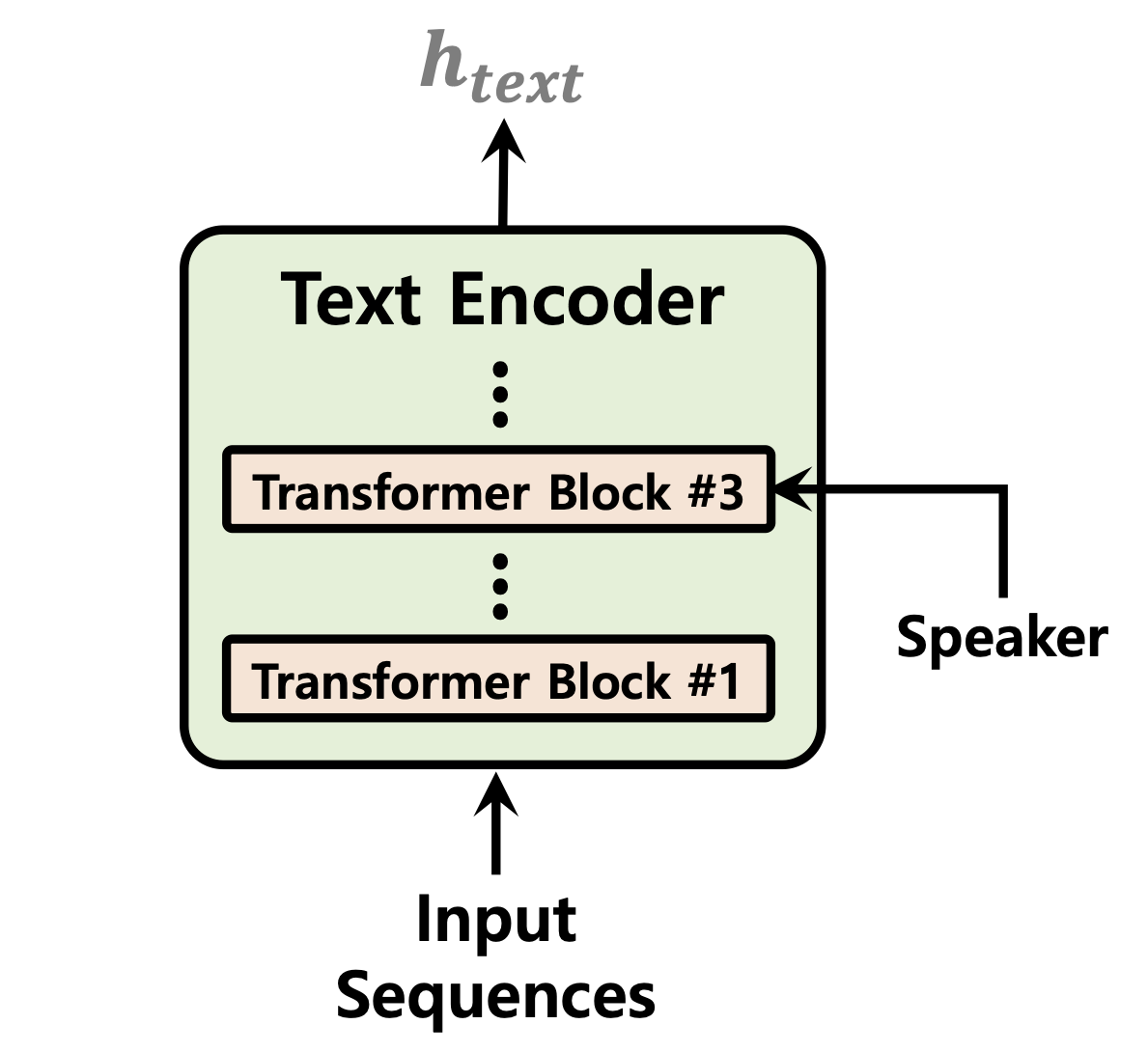 |
[กำลังดำเนินการ]
ตัวอย่างเสียงหลังจาก 52,000 ขั้นตอนของการฝึกอบรมใน 1 GPU สำหรับชุดข้อมูล ljspeech: https://github.com/daniilrobnikov/vits2/assets/91742765/d769c77a-bd92-4732-96E7-AB53BF50D783
โคลน repo
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 นี่คือสมมติว่าคุณได้นำทางไปยังรูท vits2 หลังจากโคลนมัน
หมายเหตุ: นี่คือการทดสอบภายใต้ python3.11 ด้วย Conda Env สำหรับรุ่น Python อื่น ๆ คุณอาจพบกับความขัดแย้งของเวอร์ชัน
Pytorch 2.0 โปรดอ้างอิงข้อกำหนด. txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " มีสามตัวเลือกที่คุณสามารถเลือกได้: LJ Speech, VCTK หรือชุดข้อมูลที่กำหนดเอง
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlข้อความประมวลผลล่วงหน้า ดูเตรียม/filelists.ipynb
เปลี่ยนชื่อหรือสร้างลิงก์ไปยังโฟลเดอร์ชุดข้อมูล
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(ไม่บังคับ): ลดตัวอย่างไฟล์เสียงเป็น 22050 Hz ดู AUDIO_RESAMPLE.IPYNB
Preprocess Mel-Spectrograms ดู mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlข้อความประมวลผลล่วงหน้า ดูเตรียม/filelists.ipynb
เปลี่ยนชื่อหรือสร้างลิงก์ไปยังโฟลเดอร์ชุดข้อมูล
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base ในไดเรกทอรีชุด datasets และเปลี่ยนชื่อเป็น custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml หมายเหตุ: คุณอาจต้องติดตั้ง espeak-ng หากคุณต้องการใช้เครื่องทำความสะอาด phonemize_text โปรดดู espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseดู inference.ipynb และ inference_batch.ipynb
[กำลังดำเนินการ]


