vits2
1.0.0
تمت دراسة نماذج النص إلى الكلام أحادي المرحلة مؤخرًا ، وقد تفوقت نتائجها على أنظمة خطوط أنابيب على مرحلتين. على الرغم من أن النموذج السابق للمرحلة الواحدة قد أحرز تقدمًا كبيرًا ، إلا أن هناك مجالًا للتحسين من حيث غير طبيعي ، وكفاءة حسابية ، والاعتماد القوي على تحويل الصوت. في هذا العمل ، نقدم VITS2 ، وهو نموذج نص إلى خطاب من مرحلة واحدة يقوم بتجميع خطاب أكثر طبيعية بكفاءة من خلال تحسين عدة جوانب من العمل السابق. نقترح تحسين الهياكل وآليات التدريب ونحضر أن الأساليب المقترحة فعالة في تحسين الطبيعية ، وتشابه خصائص الكلام في نموذج متعدد المتحدثين ، وكفاءة التدريب والاستدلال. علاوة على ذلك ، نثبت أن الاعتماد القوي على تحويل الصوت في الأعمال السابقة يمكن تقليله بشكل كبير مع طريقتنا ، مما يسمح بنهج مرحلة واحدة من طرف إلى طرف.
العرض التوضيحي: https://vits-2.github.io/demo/
ورقة: https://arxiv.org/abs/2307.16430
التنفيذ غير الرسمي لـ VITS2. هذا عمل مستمر. يرجى الرجوع إلى TODO لمزيد من التفاصيل.
| تنبؤ المدة | تطبيع التدفقات | تشفير النص |
|---|---|---|
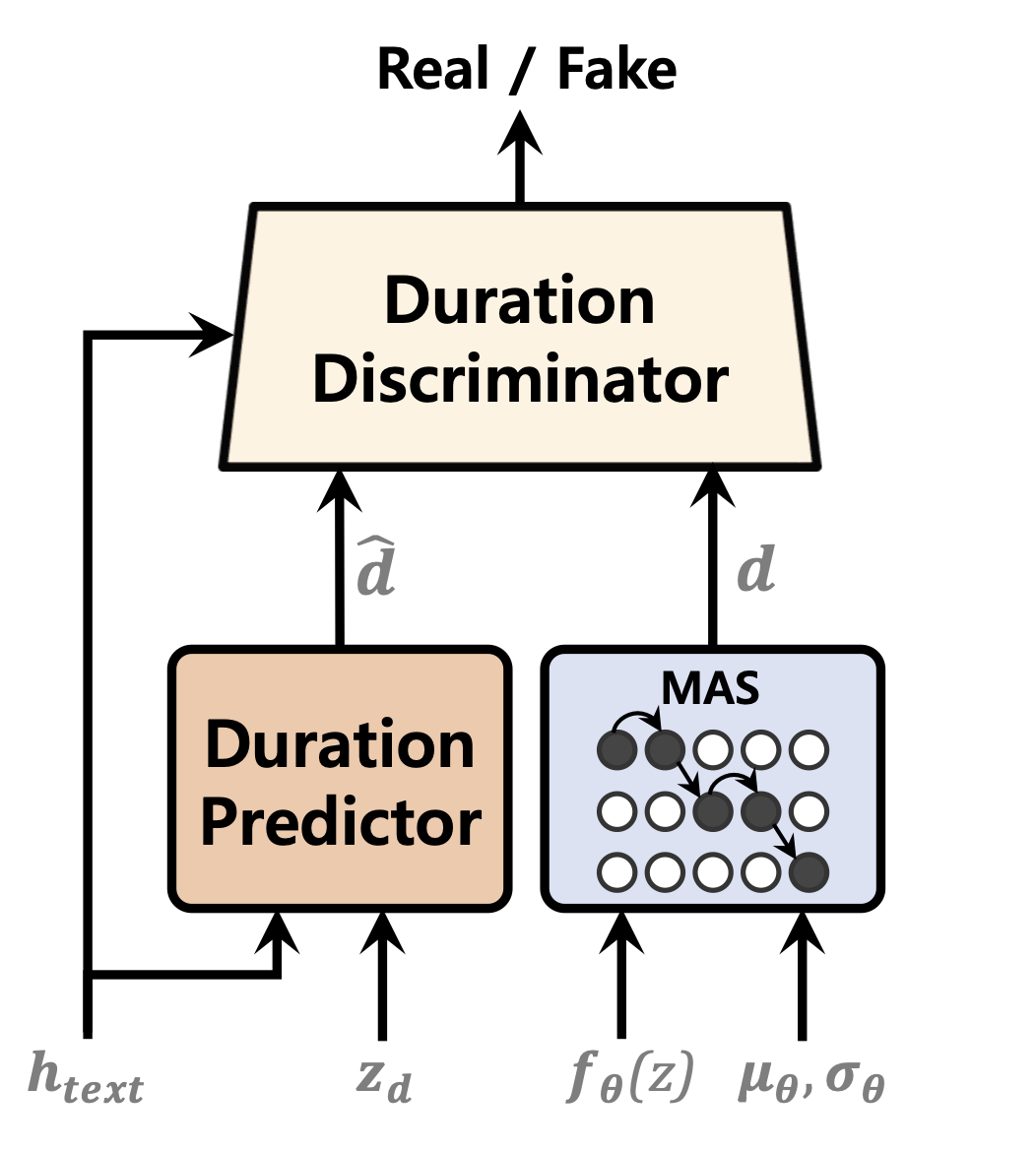 | 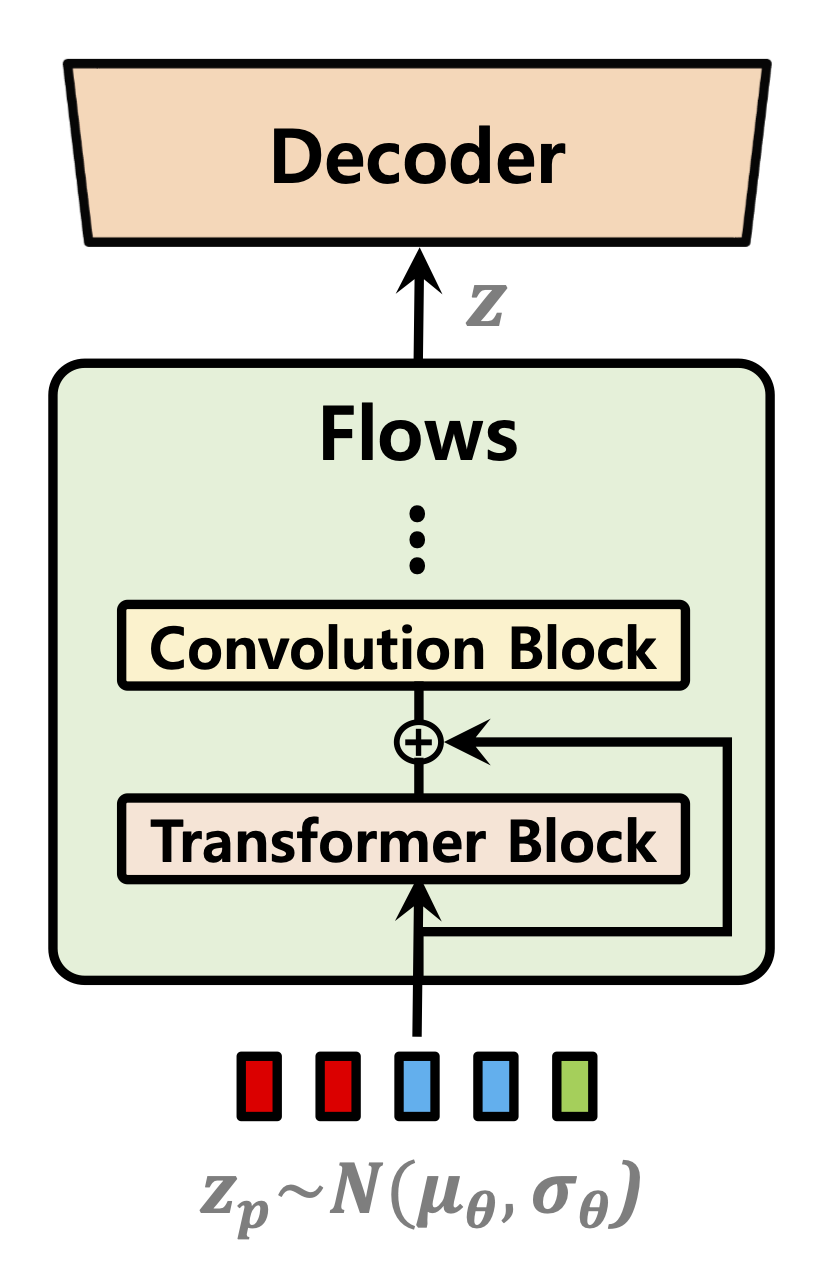 | 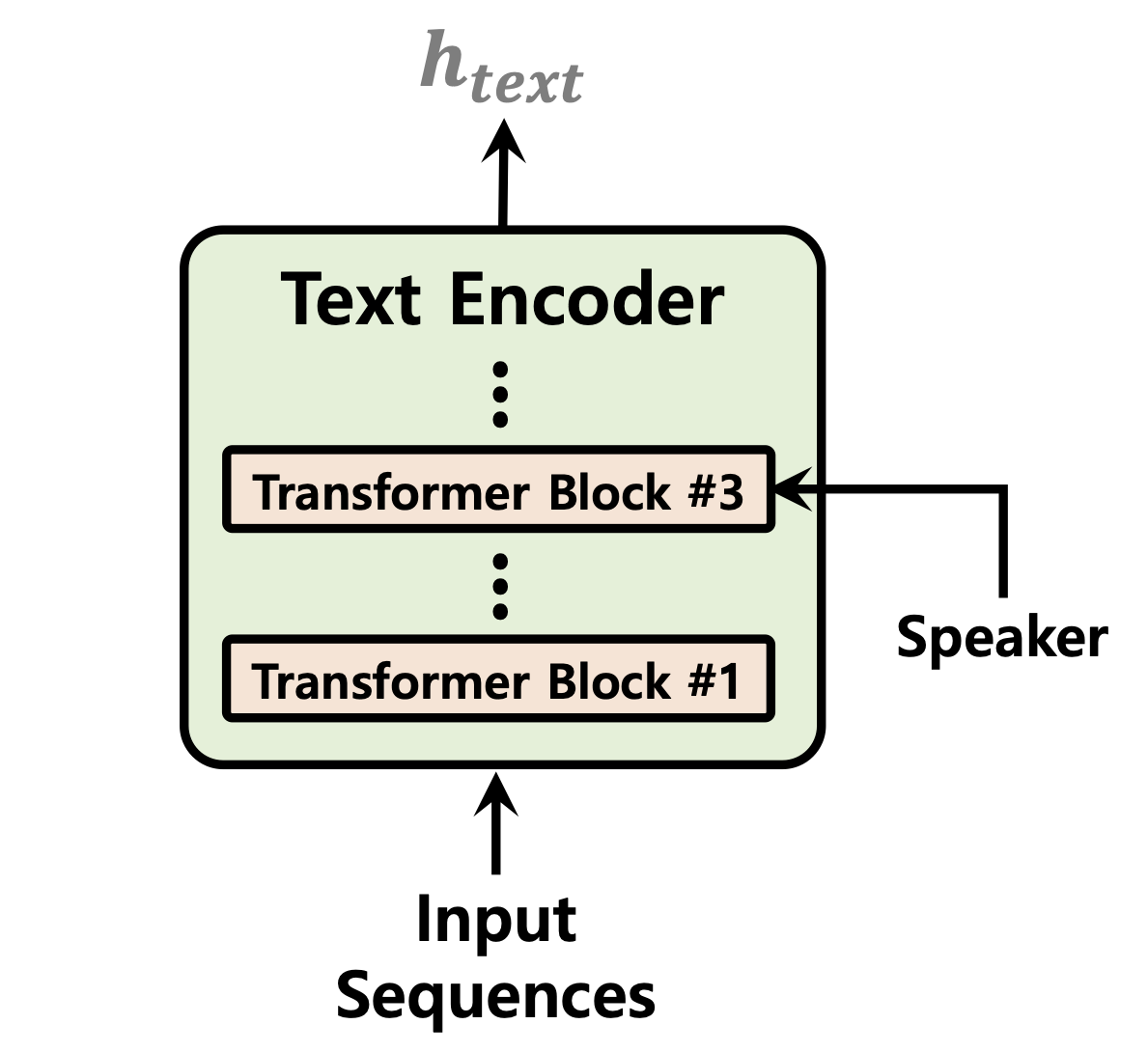 |
[في تَقَدم]
عينة من الصوت بعد 52000 خطوة من التدريب على وحدة معالجة الرسومات 1 لمجموعة بيانات LJSPEESHE:
استنساخ الريبو
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2 هذا على افتراض أنك انتقلت إلى جذر vits2 بعد استنساخه.
ملاحظة: يتم اختبار هذا تحت python3.11 مع Conda Env. بالنسبة للإصدارات الأخرى من Python ، قد تواجه صراعات الإصدار.
Pytorch 2.0 يرجى الرجوع إلى المتطلبات. txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " هناك ثلاثة خيارات يمكنك الاختيار من بينها: LJ Speech ، VCTK ، أو مجموعة بيانات مخصصة.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlنص المعالجة. انظر إعداد/filelists.ipynb
إعادة تسمية أو إنشاء رابط إلى مجلد مجموعة البيانات.
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(اختياري): Downsample ملفات الصوت إلى 22050 هرتز. انظر Audio_resample.ipynb
المعالجة المسبقة الطيف. انظر mel_transform.py
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlنص المعالجة. انظر إعداد/filelists.ipynb
إعادة تسمية أو إنشاء رابط إلى مجلد مجموعة البيانات.
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2ljs_base في دليل datasets وقم بإعادة تسميته إلى custom_baseconfig.yaml : data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml ملاحظة: قد تحتاج إلى تثبيت espeak-ng إذا كنت ترغب في استخدام منظف phonemize_text . يرجى إحالة espeak-ng
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseانظر الاستدلال.
[في تَقَدم]


