vits2
1.0.0
単一段階のテキストからスピーチへのモデルが最近積極的に研究されており、その結果は2段階のパイプラインシステムを上回っています。以前の単一段階モデルは大きな進歩を遂げましたが、断続的な不自然さ、計算効率、音素変換への強い依存の点で改善の余地があります。この作業では、以前の研究のいくつかの側面を改善することにより、より自然なスピーチを効率的に合成する単一段階のテキストからスピーチへのモデルであるVits2を紹介します。改善された構造とトレーニングメカニズムを提案し、提案された方法は、自然性の改善、マルチスピーカーモデルの音声特性の類似性、およびトレーニングと推論の効率を効果的に効果的にすることを提示します。さらに、以前の作品における音素変換への強い依存性が、完全にエンドツーエンドのシングルステージアプローチを可能にする方法で大幅に削減できることを実証します。
デモ:https://vits-2.github.io/demo/
論文:https://arxiv.org/abs/2307.16430
Vits2の非公式の実装。これは進行中の作業です。詳細については、TODOを参照してください。
| 期間予測因子 | フローの正規化 | テキストエンコーダー |
|---|---|---|
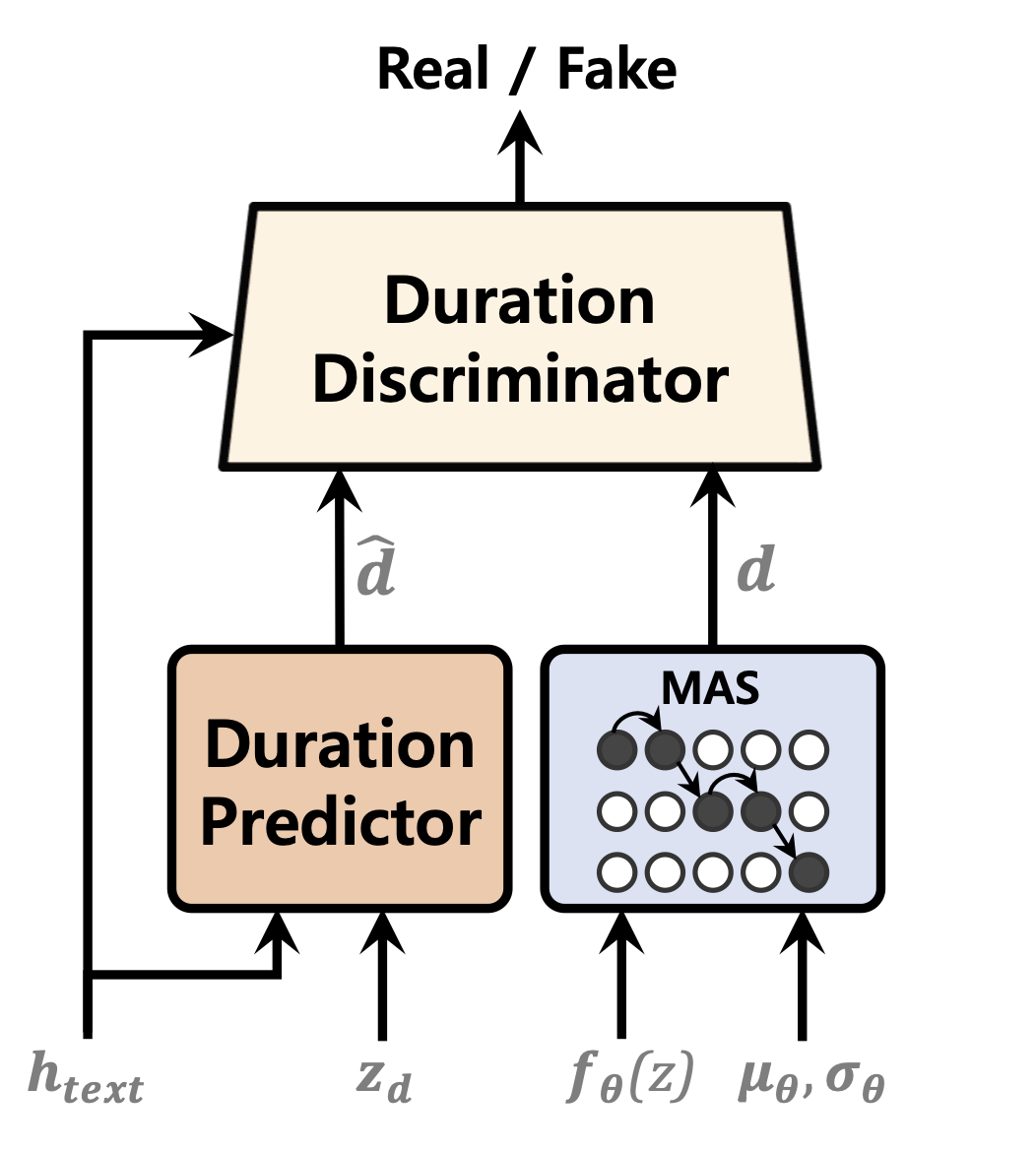 | 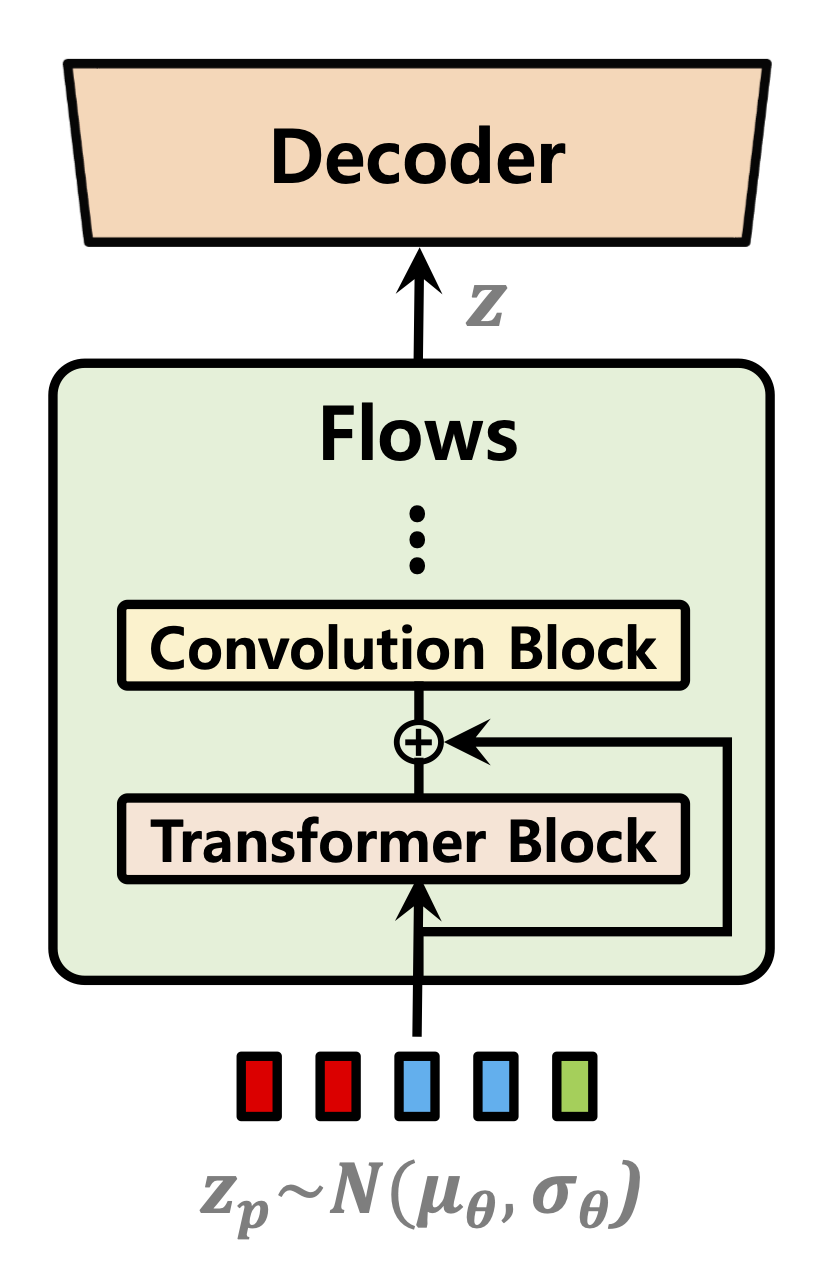 | 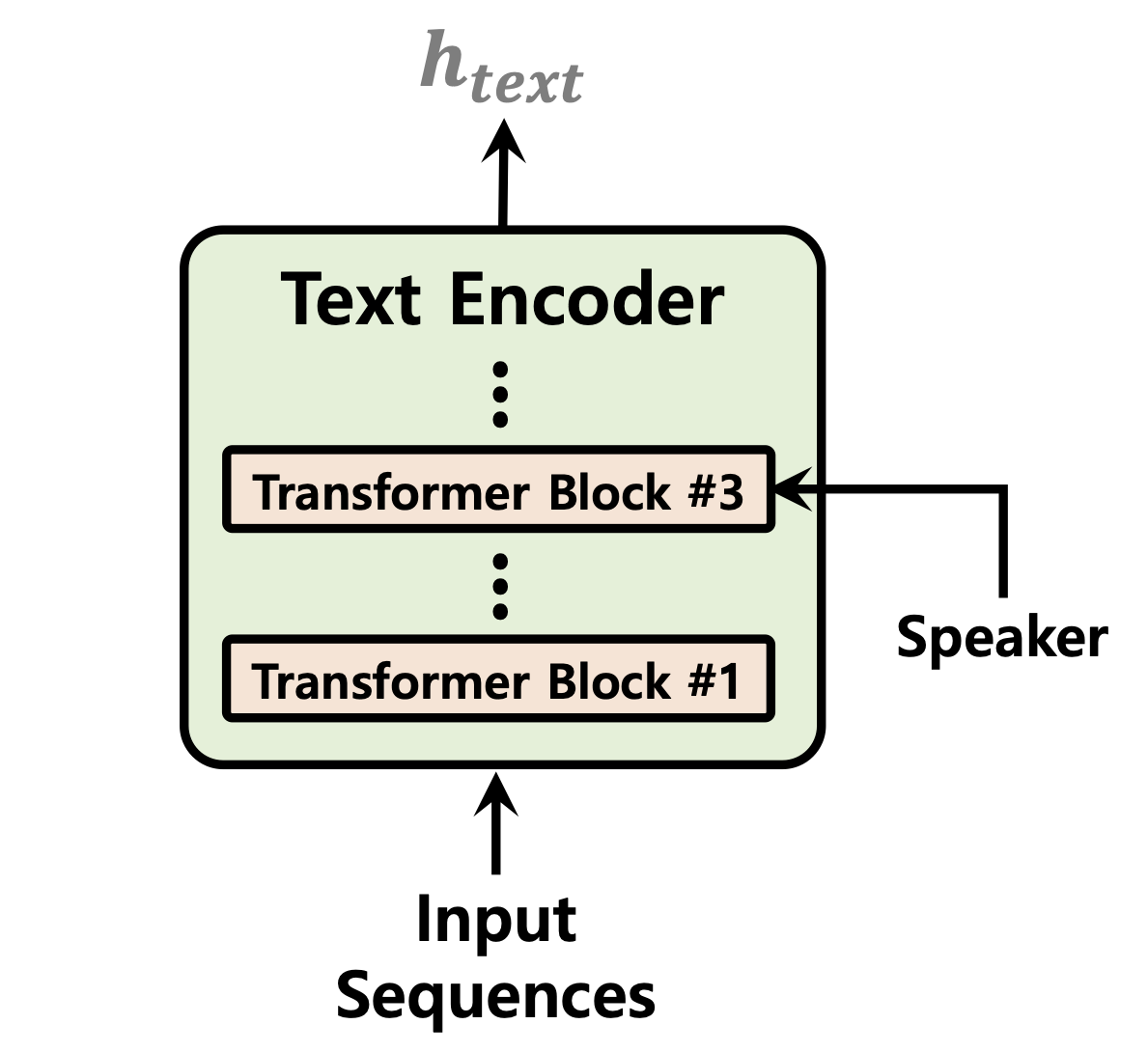 |
[進行中]
ljspeechデータセット用の1 GPUでの52,000段階のトレーニング後のオーディオサンプル:https://github.com/daniilrobnikov/vits2/assets/91742765/D769C77A-BD92-4732-96E7-AB53BFF50D78383BF50D783
レポをクローンします
git clone [email protected]:daniilrobnikov/vits2.git
cd vits2これは、クローン後にvits2ルートに移動したと仮定しています。
注:これは、conda envでpython3.11でテストされています。他のPythonバージョンの場合、バージョンの競合に遭遇する可能性があります。
pytorch 2.0は、要件を参照してください。txt
# install required packages (for pytorch 2.0)
conda create -n vits2 python=3.11
conda activate vits2
pip install -r requirements.txt
conda env config vars set PYTHONPATH= " /path/to/vits2 " LJ Speech、VCTK、またはカスタムデータセットから選択できる3つのオプションがあります。
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvf LJSpeech-1.1.tar.bz2
cd LJSpeech-1.1/wavs
rm -rf wavspython preprocess/mel_transform.py --data_dir /path/to/LJSpeech-1.1 -c datasets/ljs_base/config.yamlプリプローステキスト。 prepare/filelists.ipynbを参照してください
データセットフォルダーへのリンクの名前を変更または作成します。
ln -s /path/to/LJSpeech-1.1 DUMMY1wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3443/VCTK-Corpus-0.92.zip
unzip VCTK-Corpus-0.92.zip(オプション):オーディオファイルを22050 Hzにダウンサンプリングします。 audio_resample.ipynbを参照してください
プリプロースメルスペクトルグラム。 mel_transform.pyを参照してください
python preprocess/mel_transform.py --data_dir /path/to/VCTK-Corpus-0.92 -c datasets/vctk_base/config.yamlプリプローステキスト。 prepare/filelists.ipynbを参照してください
データセットフォルダーへのリンクの名前を変更または作成します。
ln -s /path/to/VCTK-Corpus-0.92 DUMMY2datasetsセットディレクトリのljs_baseを複製し、 custom_baseに変更しますconfig.yamlの次のフィールドを変更します。 data :
training_files : datasets/custom_base/filelists/train.txt
validation_files : datasets/custom_base/filelists/val.txt
text_cleaners : # See text/cleaners.py
- phonemize_text
- tokenize_text
- add_bos_eos
cleaned_text : true # True if you ran step 6.
language : en-us # language of your dataset. See espeak-ng
sample_rate : 22050 # sample rate, based on your dataset
...
n_speakers : 0 # 0 for single speaker, > 0 for multi-speakerpython preprocess/mel_transform.py --data_dir /path/to/custom_dataset -c datasets/custom_base/config.yaml注: phonemize_textクリーナーを使用する場合は、 espeak-ngをインストールする必要がある場合があります。 Espeak-ngを参照してください
ln -s /path/to/custom_dataset DUMMY3 # LJ Speech
python train.py -c datasets/ljs_base/config.yaml -m ljs_base
# VCTK
python train_ms.py -c datasets/vctk_base/config.yaml -m vctk_base
# Custom dataset (multi-speaker)
python train_ms.py -c datasets/custom_base/config.yaml -m custom_baseInference.ipynbおよびInference_Batch.ipynbを参照してください
[進行中]


