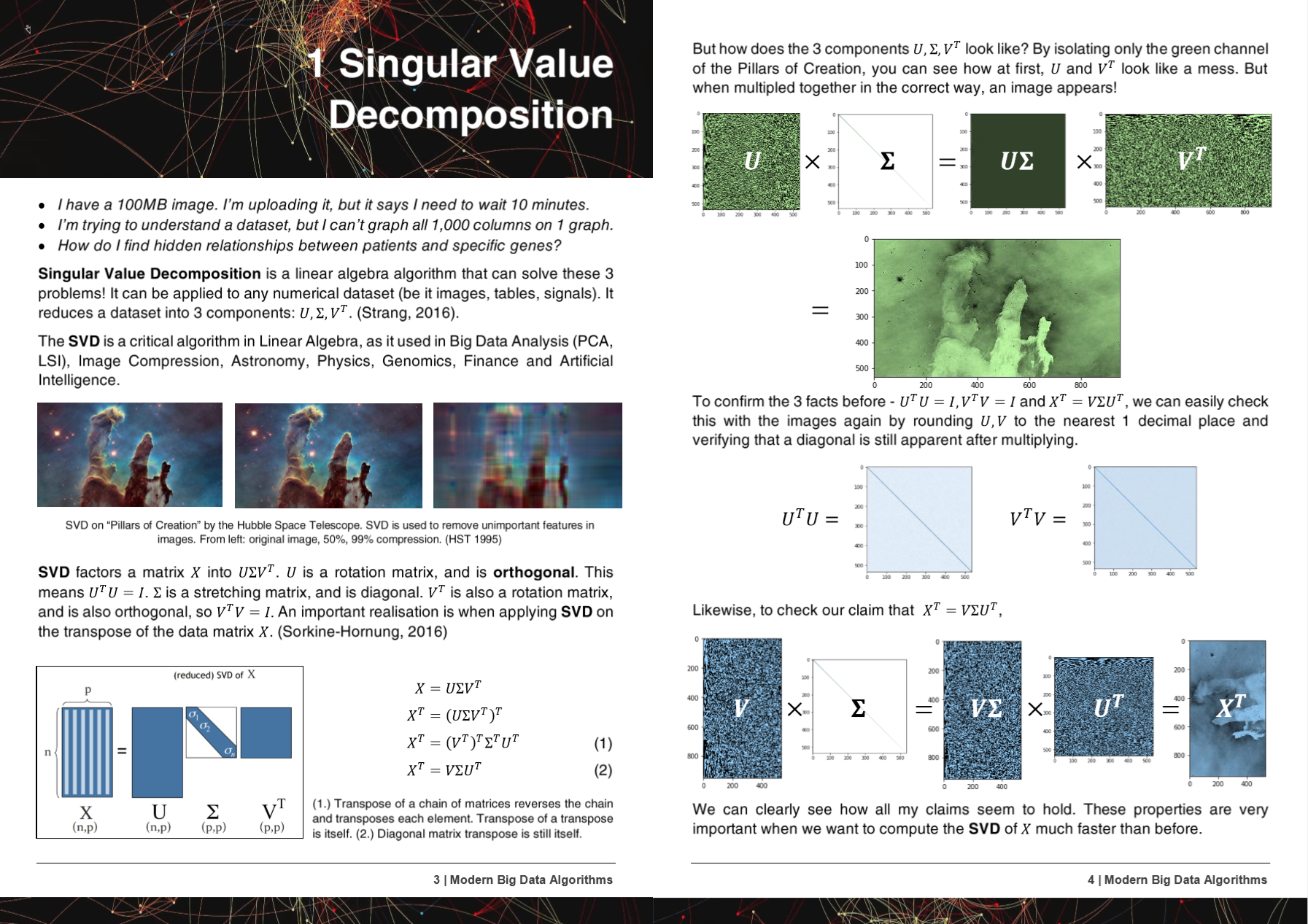
2-2000x更快的算法,减少50%的内存使用情况,可用于所有硬件 - 新的和旧的。
如果您想使用快速算法合作 - msg me!加入我们的Discord服务器以更快地制作AI,或者您只是想谈论AI! https://discord.gg/unsloth
Unsploth网站
文档
50页现代大数据算法PDF
HyperLearn的算法,方法和回购已在5篇研究论文中得到或提及!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- 微软:Yu等。使古典机器学习管道可区分http://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- 华盛顿大学:Ariel Rokem,Kendrick Kay。分数山脊回归:山脊回归的快速,可解释的重新聚集化https://arxiv.org/abs/2005.03220
- 国家科学研究中心“ Demokritos”,希腊:克里斯托斯·柏拉图,乔治奥斯·佩塔西斯。数据插补的机器学习方法的比较https://dl.acm.org/doi/10.1145/3411408.3411465
- 加州大学伯克利分校大卫·陈。 GPU加速t-Distrib的随机邻居嵌入https://digitalassets.lib.berkeley.edu/techreports/ucb/ucb/incoming/eecs-2020-89.pdf (在NVIDIA RAPIDS TSNE中融合到Nvidia rappeds)
- Nvidia :Raschka等。急流:Python中的机器学习:数据科学,机器学习和人工智能的主要发展和技术趋势
Hyperlearn的方法和算法已纳入了6个以上的组织和存储库中!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Facebook的Pytorch :SVD非常慢,凝胶给Nans,-inf#11174 pytorch/pytorch#11174
- Scipy :Eigh非常非常慢 - >建议一个简单的修复#9212 Scipy/Scipy#9212
- CUPY :制作SVD覆盖临时阵列x cupy/cupy#2277
- NVIDIA :加速与GPU一起加速TSNE:从小时到秒https://medium.com/rapids-ai/tsne-with-gpus-hours-hours-to-seconds-seconds-9d9c941db
- UNSW Abdussalam等。社交媒体图像和销售性能中的大型SKU级产品检测https://www.abstractsonline.com/pp8/# !/9305/presentation/465
在HyperLearn的开发过程中,通知GCC的错误和问题!
- GCC 10忽略函数属性优化所有X86以来,自R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- 矢量扩展对齐(1)不生成不规则的负载/商店https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- gcc> = 6不能在sse目标上直列_mm_cmp_ps https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512蒙版回归来自GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

HyperLearn完全写在Pytorch,Nogil Numba,Numpy,Pandas,Scipy&Lapack,C ++,C,Python,Cython,Cython和Assembly以及镜子(主要是)Scikit学习。 HyperLearn还具有嵌入的统计推断指标,并且可以像Scikit Learn的语法一样称为。
Hyperlearn的一些关键当前成就:
- 比Sklearn + 50%的记忆使用量减少70%的时间最小二乘 /线性回归的时间
- 由于新的并行算法,与Sklearn相比,适合非矩阵分解的时间少50%
- 40%更快的全欧盟 /余弦距离算法
- 减少50%的时间LSMR迭代最小二乘
- 新的重建SVD-使用SVD将缺失的数据归为丢失!具有.fit和.transform。比平均插补大约30%
- 50%加快稀疏基质操作 - 并行
- 随机SVD现在快20-30%
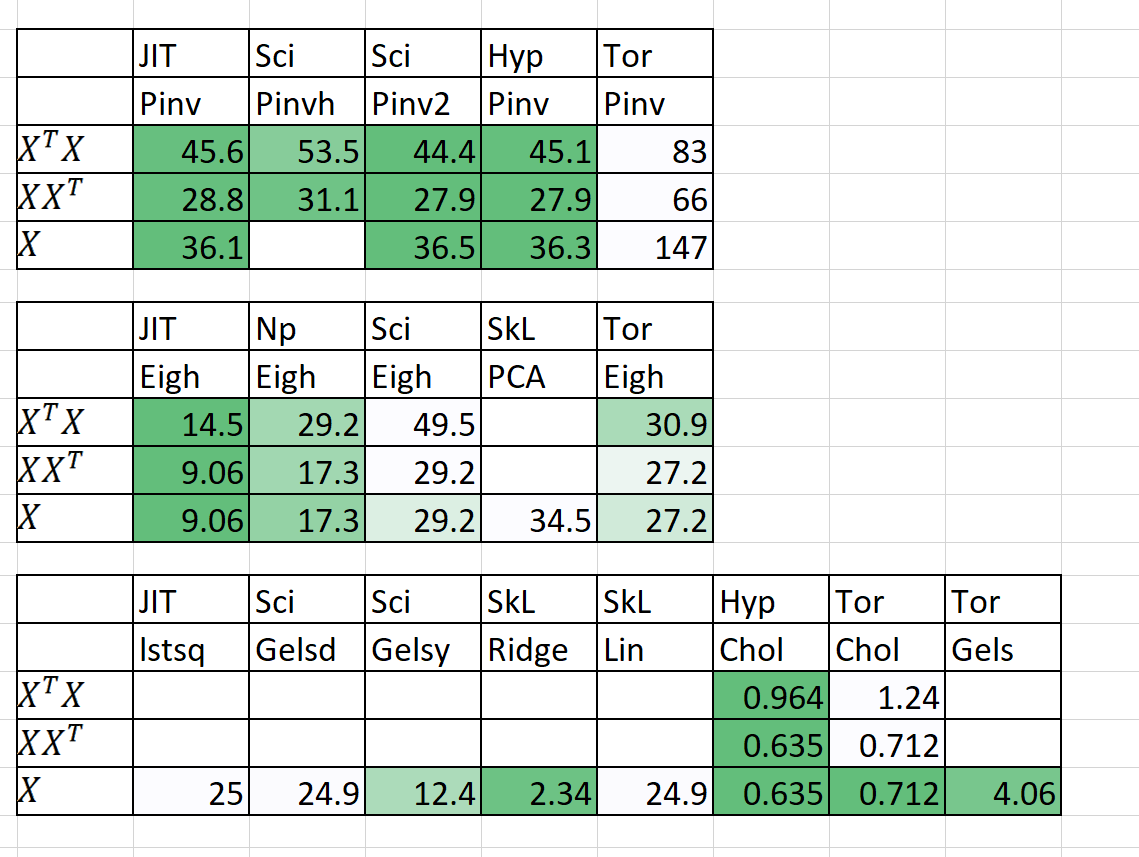
速度 /内存的比较
| 算法 | n | p | 时间 | | RAM(MB) | | 笔记 |
|---|
| | | Sklearn | 超清除 | Sklearn | 超清除 | |
| QDA(Quad dis a) | 1000000 | 100 | 54.2 | 22.25 | 2,700 | 1200 | 现在并行 |
| 线性回归 | 1000000 | 100 | 5.81 | 0.381 | 700 | 10 | 保证稳定和快速 |
时间 +预测时间。 RAM(MB)= Max(RAM(fit),RAM(预测))
我还为n = 5000,p = 6000添加了一些初步结果
确实需要帮助!给我发消息!
关键方法和目的
1。尴尬地平行于循环
2。50%+更快,50%+瘦
3。为什么StatsModels有时会难以忍受?
4。使用Pytorch模块的深度学习下降
5。20%+更少的代码,更清洁的清除代码
6。访问旧且令人兴奋的新算法
1。尴尬地平行于循环
- 包括内存共享,内存管理
- 通过pytorch&numba的cuda并行性
2。50%+更快,50%+瘦
- 矩阵乘法排序:https://en.wikipedia.org/wiki/matrix_chain_multiplication
- 元素明智的矩阵乘法将复杂性从O(n^3)降低至O(n^2):https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- 将矩阵操作简化为爱因斯坦符号:https://en.wikipedia.org/wiki/einstein_notation
- 连续评估一次性矩阵操作,以减少RAM开销。
- 如果p >> n,则可能分解XT比X好。
- 在某些情况下,应用QR分解然后SVD可能会更快。
- 利用矩阵的结构来更快地计算逆逆(例如三角矩阵,Hermitian矩阵)。
- 计算SVD(x)然后获得PINV(x)有时比纯PINV(x)快得多
3。为什么StatsModels有时会难以忍受?
- 优化了置信度,预测间隔,假设检验和线性模型的拟合测试优点。
- 在可能的情况下,使用爱因斯坦符号和哈达马产品。
- 仅计算计算的必要条件(矩阵的对角线,而不是整个矩阵)。
- 在符号,速度,内存问题和变量存储上固定统计模型的缺陷。
4。使用Pytorch模块的深度学习下降
- 使用pytorch创建Scikit-Learn,例如替换中的滴滴。
5。20%+更少的代码,更清洁的清除代码
- 尽可能使用装饰师和功能。
- 直观的中级函数名称,例如(ISTENSOR,同级)。
- 轻松通过超核能处理并行性。
6。访问旧且令人兴奋的新算法
- 矩阵完成算法 - 非负最小二乘,NNMF
- 批量相似性潜在dirichelt分配(BS-LDA)
- 相关回归
- 可行的概括最小二乘FGL
- 离群耐受回归
- 多维样条回归
- 广义小鼠(替换中的任何模型下降)
- 使用Uber的Pyro进行贝叶斯深度学习
额外的许可条款
- 采用Apache 2.0许可证。