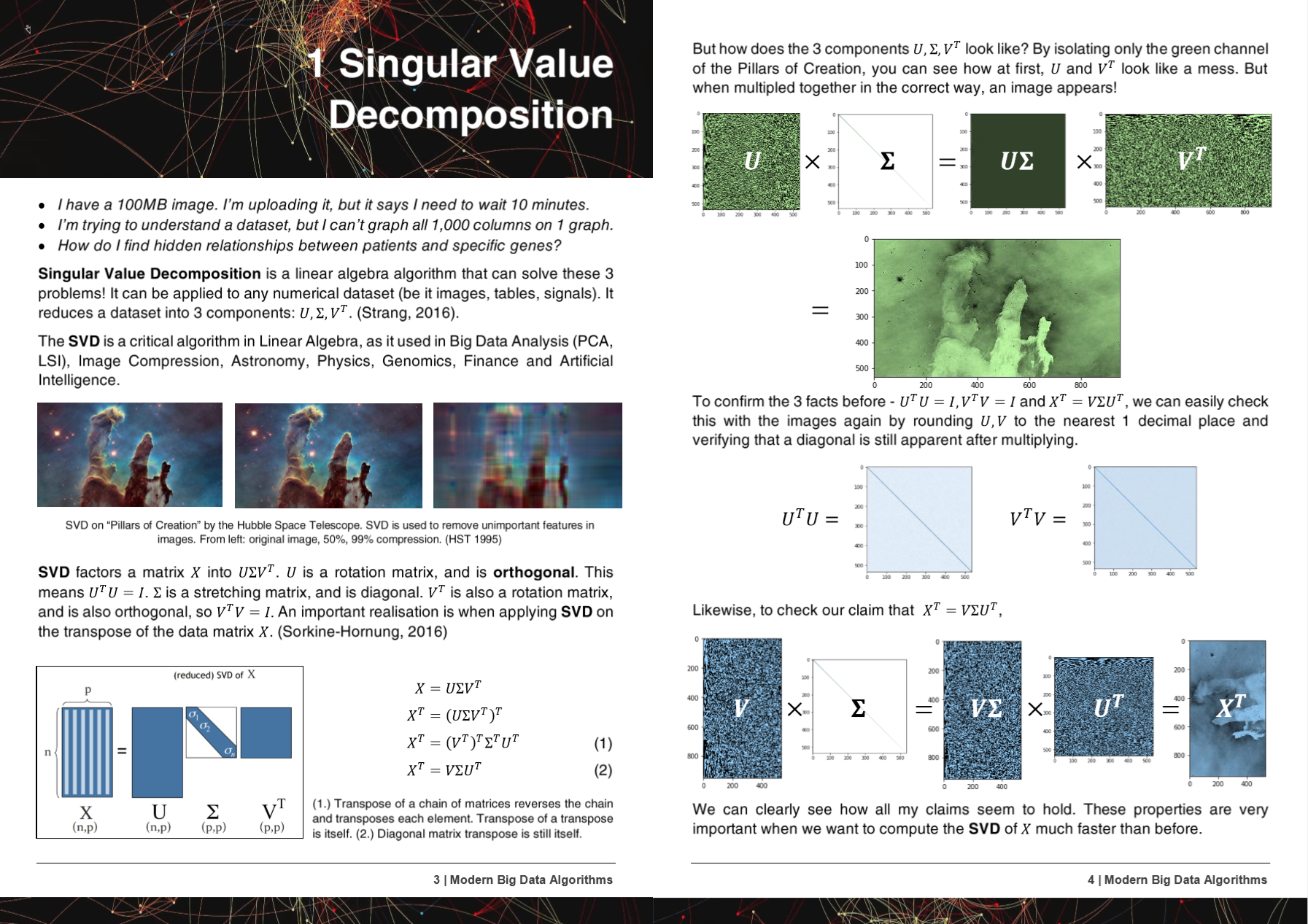
2-2000x algos plus rapides, 50% de consommation de mémoire en moins, fonctionne sur tout le matériel - nouveau et ancien.
Si vous souhaitez collaborer sur des algorithmes rapides - msg me !! Rejoignez notre serveur Discord sur la création d'IA plus rapidement, ou si vous voulez simplement discuter de l'IA !! https://discord.gg/unsloth
Site Web non
Documentation
50 pages algorithmes modernes de Big Data PDF
Les algorithmes, les méthodes et les référentiels d'HyperLerlearn ont été présentés ou mentionnés dans 5 articles de recherche!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. Faire des pipelines d'apprentissage automatique classiques différenciables http://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- Université de Washington : Ariel Rokem, Kendrick Kay. Régression fractionnaire de la crête: une réparamétrisation rapide et interprétable de la régression de la crête https://arxiv.org/abs/2005.03220
- Centre national de recherche scientifique «DeMokritos», Grèce : Christos Platias, Georgios Petasis. Une comparaison des méthodes d'apprentissage automatique pour l'imputation des données https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. GPU a accéléré le voisin stochastique T-Distributed https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf (méthodes hyperléleuses incorporées dans Nvidia rapids tsne)
- Nvidia : Raschka et al. Rapids: Machine Learning in Python: Principales développements et tendances technologiques en science des données, apprentissage automatique et intelligence artificielle https://arxiv.org/abs/2002.04803 (méthodes HyperLararn incorporées dans Nvidia Rapids Tsne)
Les méthodes et les algorithmes d'HyperLerlearn ont été incorporés dans plus de 6 organisations et référentiels!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Pytorch de Facebook : SVD très très lent et Gels donne nans, -inf # 11174 Pytorch / Pytorch # 11174
- Scipy : Huitième très très lent -> suggérant une solution facile # 9212 Scipy / Scipy # 9212
- Cupy : Faites en train d'écraser le SVD
- Nvidia : accélérer tsne avec gpus: des heures aux secondes https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam et al. Détection de produits de niveau SKU à grande échelle dans les images de médias sociaux et performances de vente https://www.abstractrsonline.com/pp8/#!/9305/presentation/465
Pendant le développement d'Hypeararn, les bogues et les problèmes ont été informés de GCC!
- GCC 10 Ignorer l'attribut de la fonction Optimiser pour tous les x86 depuis R11-1019 https://gcc.gnU.org/bugzilla/show_bug.cgi?id=96535
- Extensions vectorielles alignées (1) ne générant pas de charges / magasins non alignés https://gcc.gnU.org/bugzilla/show_bug.cgi?id=98317
- Gcc> = 6 ne peut pas en ligne _mm_cmp_ps sur les cibles SSE https://gcc.gnU.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512 Masque Régression de GCC 9 https://gcc.gnU.org/bugzilla/show_bug.cgi?id=98348

HyperLerlearn est entièrement écrit dans Pytorch, Nogil Numba, Numpy, Pandas, Scipy & Lapack, C ++, C, Python, Cython and Assembly, and Mirrors (principalement) Scikit Learn. HyperLerlearn a également des mesures d'inférence statistique intégrées et peut être appelée comme la syntaxe de Scikit Learn.
Quelques réalisations actuelles clés de HyperLerlearn:
- 70% moins de temps pour s'adapter aux moindres carrés / régression linéaire que Sklearn + 50% moins d'utilisation de la mémoire
- 50% moins de temps pour ajuster la factorisation de matrice non négative que Sklearn en raison d'un nouvel algo parallélisé
- Algorithmes de distance euclidiens / cosinus 40% plus rapides
- 50% moins de temps lsmr les moindres carrés itératifs
- Nouveau SVD de reconstruction - Utilisez SVD pour imputer les données manquantes! A .fit et .transform. Environ 30% mieux que l'imputation moyenne
- 50% d'opérations matricielles clairsemées plus rapides - parallélisé
- Randomizedsvd est maintenant de 20 à 30% plus rapidement
Comparaison de la vitesse / de la mémoire
| Algorithme | n | p | Fois) | | RAM (MB) | | Notes |
|---|
| | | Sklearn | Hyperléraire | Sklearn | Hyperléraire | |
| QDA (quad dis a) | 1000000 | 100 | 54.2 | 22.25 | 2 700 | 1 200 | Maintenant parallélisé |
| Linéaire | 1000000 | 100 | 5.81 | 0,381 | 700 | 10 | Garanti stable et rapide |
Le temps (s) est ajusté + prédire. RAM (MB) = Max (RAM (FIT), RAM (Prédire))
J'ai également ajouté quelques résultats préliminaires pour n = 5000, p = 6000
L'aide est vraiment nécessaire! Envoyez-moi un message!
Méthodologies et objectifs clés
1. Parallèlement embarrassant pour les boucles
2. 50% + plus rapide, 50% + maigre
3. Pourquoi les modèles de statistiques sont-ils parfois insupportablement lents?
4. Deep Learning Drop dans les modules avec Pytorch
5. 20% + Code moins, code plus clair
6. Accéder à de nouveaux algorithmes anciens et passionnants
1. Parallèlement embarrassant pour les boucles
- Y compris le partage de mémoire, la gestion de la mémoire
- Parallélisme de Cuda à travers Pytorch & Numba
2. 50% + plus rapide, 50% + maigre
- Matrix Multiplication Ordering: https://en.wikipedia.org/wiki/Matrix_Chain_Multiplication
- Element Wise Matrix Multiplication réduisant la complexité à O (n ^ 2) de O (n ^ 3): https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- Réduire les opérations matricielles à la notation d'Einstein: https://en.wikipedia.org/wiki/einstein_notation
- Évaluer successivement les opérations matricielles ponctuelles pour réduire les frais généraux de RAM.
- Si P >> N, peut-être que décomposer XT est meilleur que X.
- L'application de la décomposition de QR alors SVD pourrait être plus rapide dans certains cas.
- Utilisez la structure de la matrice pour calculer l'inverse plus rapide (par exemple les matrices triangulaires, les matrices hérmitiennes).
- L'informatique SVD (x) puis obtient PINV (x) est parfois plus rapide que PINV pur (x)
3. Pourquoi les modèles de statistiques sont-ils parfois insupportablement lents?
- La confiance, les intervalles de prédiction, les tests d'hypothèse et la bonté des tests d'ajustement pour les modèles linéaires sont optimisés.
- Utilisation de produits Einstein Notation et Hadamard dans la mesure du possible.
- Calculer uniquement ce qui est nécessaire à calculer (diagonale de la matrice et non en toute matrice).
- Fixation des défauts des modèles de statistiques sur la notation, la vitesse, les problèmes de mémoire et le stockage des variables.
4. Deep Learning Drop dans les modules avec Pytorch
- Utilisation de Pytorch pour créer des remplacements de la gamme de scikit.
5. 20% + Code moins, code plus clair
- Utilisation des décorateurs et des fonctions dans la mesure du possible.
- Noms de fonction de niveau intermédiaire intuitifs comme (istensor, isiterable).
- Gère facilement le parallélisme à travers HyperLerlearn.Multiprocessing
6. Accéder à de nouveaux algorithmes anciens et passionnants
- Algorithmes d'achèvement de la matrice - moindres carrés non négatifs, NNMF
- Similitude par lots allocation de Dirichelt (BS-LDA)
- Régression de corrélation
- FGLS des moindres carrés généralisés réalisables
- Régression tolérante aberrante
- Régression multidimensionnelle des spline
- Souris généralisées (n'importe quelle chute de modèle en remplacement)
- Utiliser le pyro d'Uber pour l'apprentissage en profondeur bayésien
Conditions de licence supplémentaire
- La licence Apache 2.0 est adoptée.