2-2000X Algos mais rápidos, 50% menos uso de memória, funciona em todo o hardware - novo e antigo.
Se você quiser colaborar em algoritmos rápidos - MSG -ME !! Junte -se ao nosso servidor Discord para tornar a IA mais rápida, ou se você só quiser conversar sobre ai !! https://discord.gg/unsloth
Site não -lotado
Documentação
Algoritmos de big data modernos de 50 páginas
Os algoritmos, métodos e repositórios da Hyperlearn foram apresentados ou mencionados em 5 trabalhos de pesquisa!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. Fazendo pipelines de aprendizado de máquina clássicos diferenciáveis http://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- Universidade de Washington : Ariel Rokem, Kendrick Kay. Regressão fracionária de cume: um reparameterização rápida e interpretável da regressão de cume https://arxiv.org/abs/2005.03220
- Centro Nacional de Pesquisa Científica 'Demokritos', Grécia : Christos Platias, Georgios Petasis. Uma comparação dos métodos de aprendizado de máquina para imputação de dados https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. A GPU acelerou o vizinho estocástico distribuído em T incorporando https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf (métodos hiperleares incorporados em nvidia tsne)
- Nvidia : Raschka et al. Rapids: Aprendizado de Máquina em Python: Desenvolvimentos principais e tendências tecnológicas em ciência de dados, aprendizado de máquina e inteligência artificial https://arxiv.org/abs/2002.04803 (Métodos Hyperlearn incorporados em Nvidia Rapids TSNE)
Os métodos e algoritmos da Hyperlearn foram incorporados a mais de 6 organizações e repositórios!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Pytorch do Facebook : SVD muito lento e géis dá a Nans, -inf #11174 Pytorch/Pytorch #11174
- SCIPY : Eight muito lento -> sugerindo uma correção fácil #9212 Scipy/Scipy #9212
- Cupy : Faça SVD substituir a matriz temporária x Cupy/Cupy#2277
- NVIDIA : acelerando TSNE com GPUs: de horas a segundos https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam et al. Detecção de produtos de nível de escala em larga escala em imagens de mídia social e desempenho de vendas https://www.abstractsonline.com/pp8/#!/9305/presentation/465
Durante o desenvolvimento da Hyperlearn, os insetos e os problemas foram notificados para o GCC!
- GCC 10 Ignorando o atributo da função Optimize para todos os x86 desde R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- Extensões vetoriais alinhadas (1) não gerando cargas/lojas não alinhadas https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- Gcc> = 6 não pode embalar _mm_cmp_ps nos alvos sse https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512 Regressão de máscara do GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

O Hyperlearn está escrito completamente em Pytorch, Nogil Numba, Numpy, Pandas, Scipy & LaPack, C ++, C, Python, Cython e Assembly e espelhos (principalmente) Scikit Learn. O Hyperlearn também possui medidas estatísticas de inferência incorporada e pode ser chamada de sintaxe do Scikit Learn.
Algumas conquistas importantes do Hyperlearn:
- 70% menos tempo para ajustar os mínimos quadrados / regressão linear do que Sklearn + 50% menos uso de memória
- 50% menos tempo para se ajustar à fatoração de matriz não negativa do que a Sklearn devido a um novo algo paralelo
- 40% mais rápido de algoritmos de distância euclidiana / cosseno
- 50% menos tempo de mínimos quadrados iterativos
- New Reconstruction SVD - Use SVD para imputar dados ausentes! Tem .fit e .Transform. Aproximadamente 30% melhor que a imputação média
- 50% mais rápido operações de matriz esparsa - paralelamente
- Randomizedsvd agora é 20 - 30% mais rápido
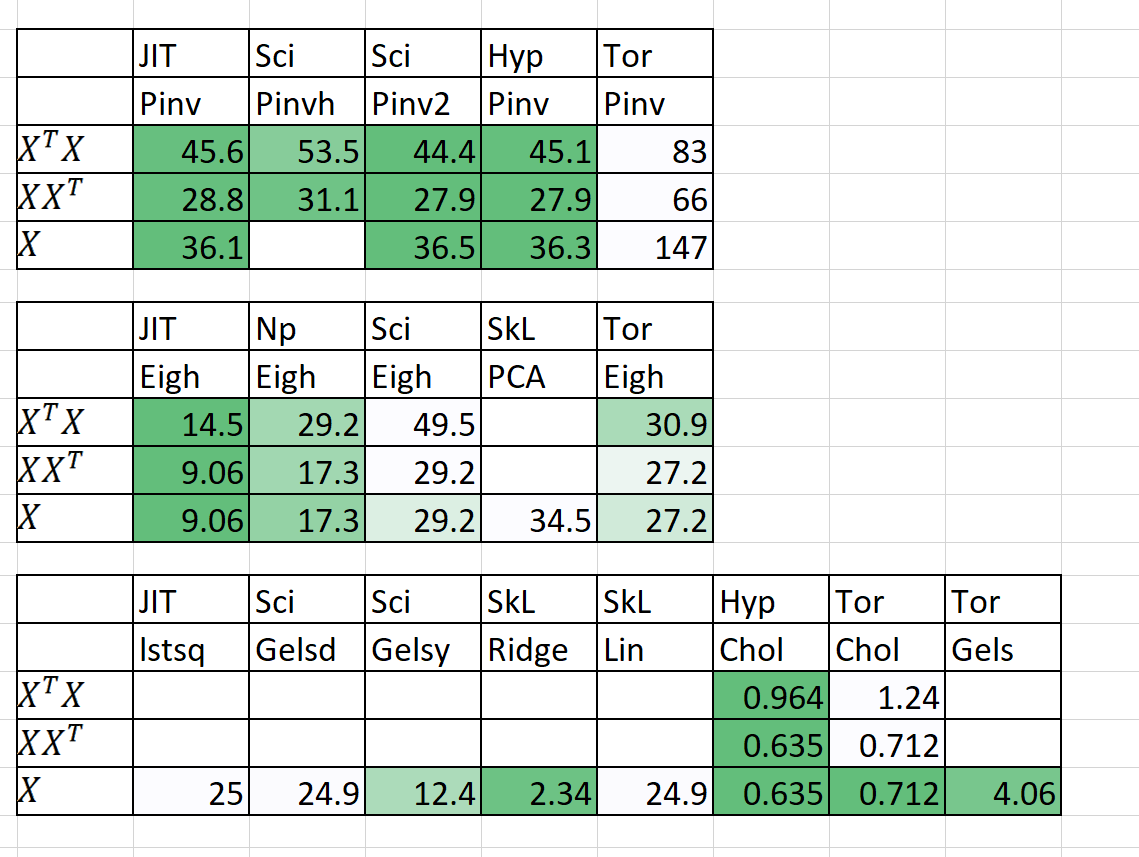
Comparação de velocidade / memória
| Algoritmo | n | p | Hora (s) | | RAM (MB) | | Notas |
|---|
| | | Sklearn | Hyperlearn | Sklearn | Hyperlearn | |
| QDA (Quad Dis A) | 1000000 | 100 | 54.2 | 22.25 | 2.700 | 1.200 | Agora paralelado |
| Regressão linear | 1000000 | 100 | 5.81 | 0,381 | 700 | 10 | Estável garantido e rápido |
O tempo (s) é adequado + previsão. RAM (MB) = Max (RAM (FIT), RAM (Preveja))
Eu também adicionei alguns resultados preliminares para n = 5000, p = 6000
A ajuda é realmente necessária! Envie -me uma mensagem!
Metodologias e objetivos principais
1. Embaraçosamente paralelo para loops
2. 50%+ mais rápido, 50%+ mais magro
3. Por que o STATSModels às vezes é insuportavelmente lento?
4. Deep Learning Drop em módulos com Pytorch
5. 20%+ menos código, código mais limpo mais limpo
6. Acessando novos e empolgantes algoritmos novos
1. Embaraçosamente paralelo para loops
- Incluindo compartilhamento de memória, gerenciamento de memória
- Paralelismo de Cuda através de Pytorch e Numba
2. 50%+ mais rápido, 50%+ mais magro
- Pedido de multiplicação da matriz: https://en.wikipedia.org/wiki/Matrix_Chain_Multiplication
- Multiplicação da matriz de elemento Reduzindo a complexidade a O (n^2) de O (n^3): https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- Reduzindo operações da matriz para a notação de Einstein: https://en.wikipedia.org/wiki/einstein_notation
- Avaliando operações de matriz única em sucessão para reduzir a sobrecarga da RAM.
- Se p >> n, talvez a decomposição do XT seja melhor que X.
- A aplicação de decomposição de QR e SVD pode ser mais rápida em alguns casos.
- Utilize a estrutura da matriz para calcular mais rápido inverso (por exemplo, matrizes triangulares, matrizes hermitianas).
- Computação SVD (x) então obter pinv (x) às vezes é mais rápido que o pinv puro (x)
3. Por que o STATSModels às vezes é insuportavelmente lento?
- Confiança, intervalos de previsão, testes de hipóteses e bondade de ajuste para modelos lineares são otimizados.
- Usando produtos Einstein Notation & Hadamard sempre que possível.
- Computando apenas o que é necessário calcular (diagonal da matriz e não uma matriz inteira).
- Corrigindo as falhas dos modelos STATSModels em notação, velocidade, problemas de memória e armazenamento de variáveis.
4. Deep Learning Drop em módulos com Pytorch
- Usando o Pytorch para criar queda no Scikit-Learn em substituições.
5. 20%+ menos código, código mais limpo mais limpo
- Usando decoradores e funções sempre que possível.
- Nomes de funções de nível médio intuitivos como (istensor, isiterable).
- Lida com o paralelismo facilmente através do hyperlearn.multiprocessing
6. Acessando novos e empolgantes algoritmos novos
- Algoritmos de conclusão da matriz - mínimos quadrados não negativos, nnmf
- Alocação de Dirichelt latente de similaridade em lote (BS-LDA)
- Regressão de correlação
- FGLS de mínimos mínimos generalizados
- Regressão tolerante de outlier
- Regressão multidimensional de spline
- Ratos generalizados (qualquer queda de modelo em substituição)
- Usando o piro do Uber para o aprendizado profundo bayesiano
Termos de licença extras
- A licença Apache 2.0 é adotada.