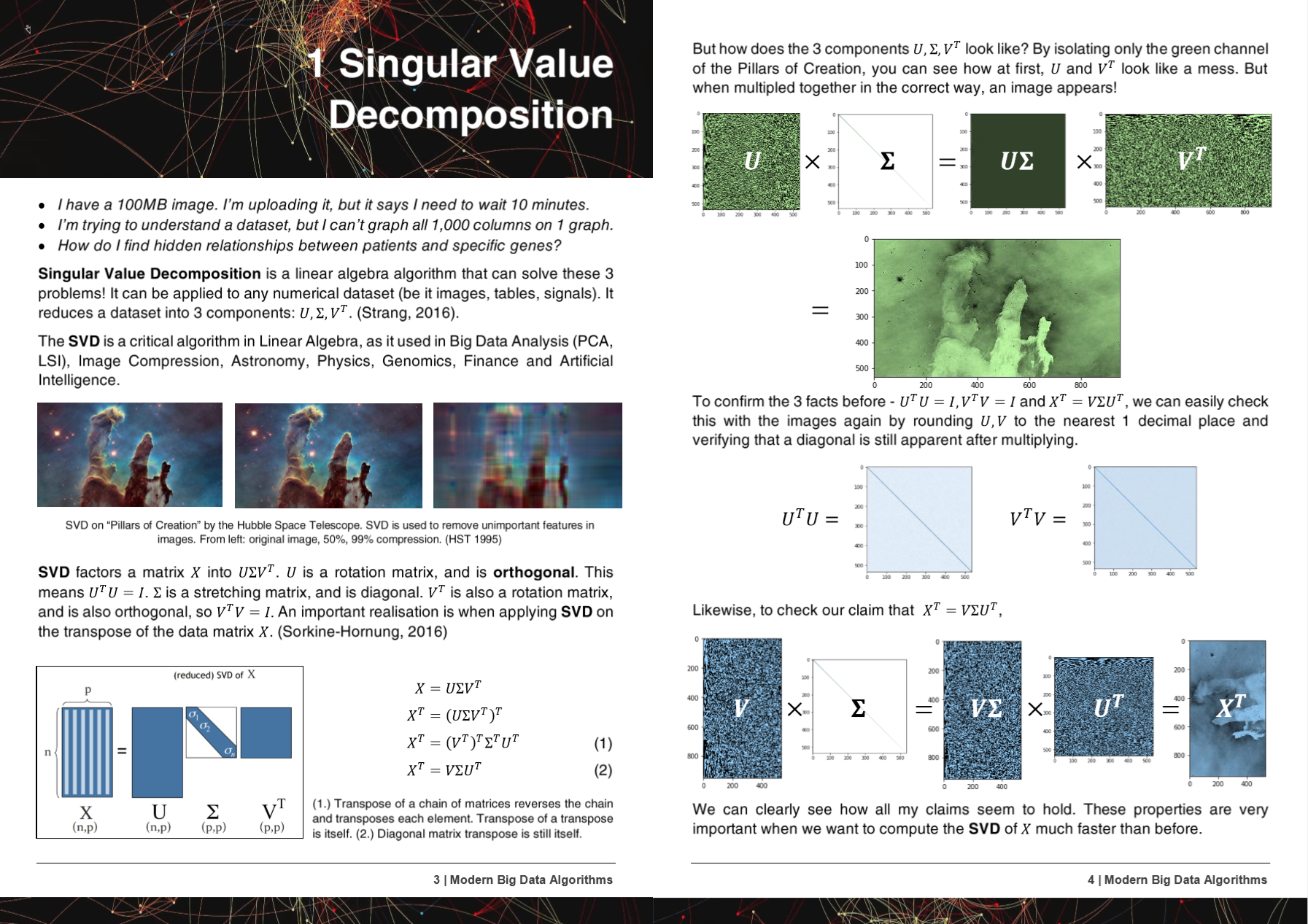
2-2000x الأطوار الأسرع ، و 50 ٪ استخدام الذاكرة ، يعمل على جميع الأجهزة - جديدة وقديمة.
إذا كنت تريد التعاون على خوارزميات سريعة - MSG ME !! انضم إلى خادم Discord الخاص بنا على جعل الذكاء الاصطناعي أسرع ، أو إذا كنت تريد فقط الدردشة حول الذكاء الاصطناعي !! https://discord.gg/unsloth
موقع Unloth
الوثائق
50 صفحة خوارزميات البيانات الكبيرة الحديثة PDF
وقد تم عرض خوارزميات Hyperlearn والأساليب والإمكانية المذكورة في 5 أوراق بحثية!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. صنع خطوط أنابيب التعلم الآلي الكلاسيكي http://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- جامعة واشنطن : أرييل روكيم ، كيندريك كاي. انحدار التلال الكسري: إعادة تدوير سريعة يمكن تفسيرها لانحدار التلال https://arxiv.org/abs/2005.03220
- المركز الوطني للبحث العلمي "Demokritos" ، اليونان : كريستوس بلاتاس ، جورجيوس بيتاسيس. مقارنة بين أساليب التعلم الآلي لاتخاذة البيانات https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. GPU تسريع t-distributed جار العشوائي التضمين https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89
- Nvidia : Raschka et al. Rapids: التعلم الآلي في Python: التطورات الرئيسية واتجاهات التكنولوجيا في علوم البيانات ، والتعلم الآلي ، والذكاء الاصطناعي https://arxiv.org/abs/2002.04803 (أساليب Hyperlearn المدمجة في nvidia rapids tsne)
تم دمج أساليب Hyperlearn وخوارزميات في أكثر من 6 منظمات ومستودعات!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Pytorch على Facebook : SVD بطيء جدًا ويعطي المواد الهلامية nans ، -inf #11174 pytorch/pytorch #11174
- Scipy : Eigh بطيئة جدًا -> اقتراح إصلاح سهل #9212 Scipy/Scipy #9212
- Cupy : اجعل SVD Overtrite Array Array X Cupy/Cupy#2277
- nvidia : تسريع tsne مع وحدات معالجة الرسومات: من ساعات إلى ثوان https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW ABDUSSALAM et al. اكتشاف المنتج على مستوى SKU على نطاق واسع في صور وسائل التواصل الاجتماعي وأداء المبيعات https://www.abstractsonline.com/pp8/# !/9305/presentation/465
أثناء تطور Hyperlearn ، تم إخطار الأخطاء والقضايا في GCC!
- GCC 10 تجاهل سمة وظيفة تحسين لجميع x86 منذ R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi؟id=96535
- امتدادات المتجهات محاذاة (1) لا تولد أحمال/متاجر غير محددة https://gcc.gnu.org/bugzilla/show_bug.cgi؟id=98317
- GCC> = 6 لا يمكن مضمنة _mm_cmp_ps على أهداف SSE https://gcc.gnu.org/bugzilla/show_bug.cgi؟id=98387
- GCC 10.2 AVX512 انحدار قناع من GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi؟id=98348

تتم كتابة Hyperlearn بالكامل في Pytorch و Nogil Numba و Numpy و Pandas و Scipy & Lapack و C ++ و C و Python و Cython و Assembly و Mirrors (معظمها) Scikit Learn. يحتوي Hyperlearn أيضًا على تدابير استدلال إحصائية مضمنة ، ويمكن تسميتها تمامًا مثل بناء جملة Scikit Learn.
بعض الإنجازات الحالية الرئيسية للفرط:
- بنسبة 70 ٪ وقت أقل لتناسب المربعات الصغرى / الانحدار الخطي من Sklearn + 50 ٪ استخدام الذاكرة أقل
- 50 ٪ أقل وقت لتناسب معامل المصفوفة غير السلبية من Sklearn بسبب algo المتوازي الجديد
- 40 ٪ أسرع خوارزميات مسافة إقليدية / جيب التمام
- بنسبة 50 ٪ وقت أقل من LSMR المربعات الصغرى
- إعادة بناء جديدة SVD - استخدم SVD لفرض البيانات المفقودة! لديه .fit و .transform. حوالي 30 ٪ أفضل من التضمين يعني
- بنسبة 50 ٪ عمليات مصفوفة متناثرة أسرع - موازية
- عشوائيون الآن أسرع من 20 إلى 30 ٪
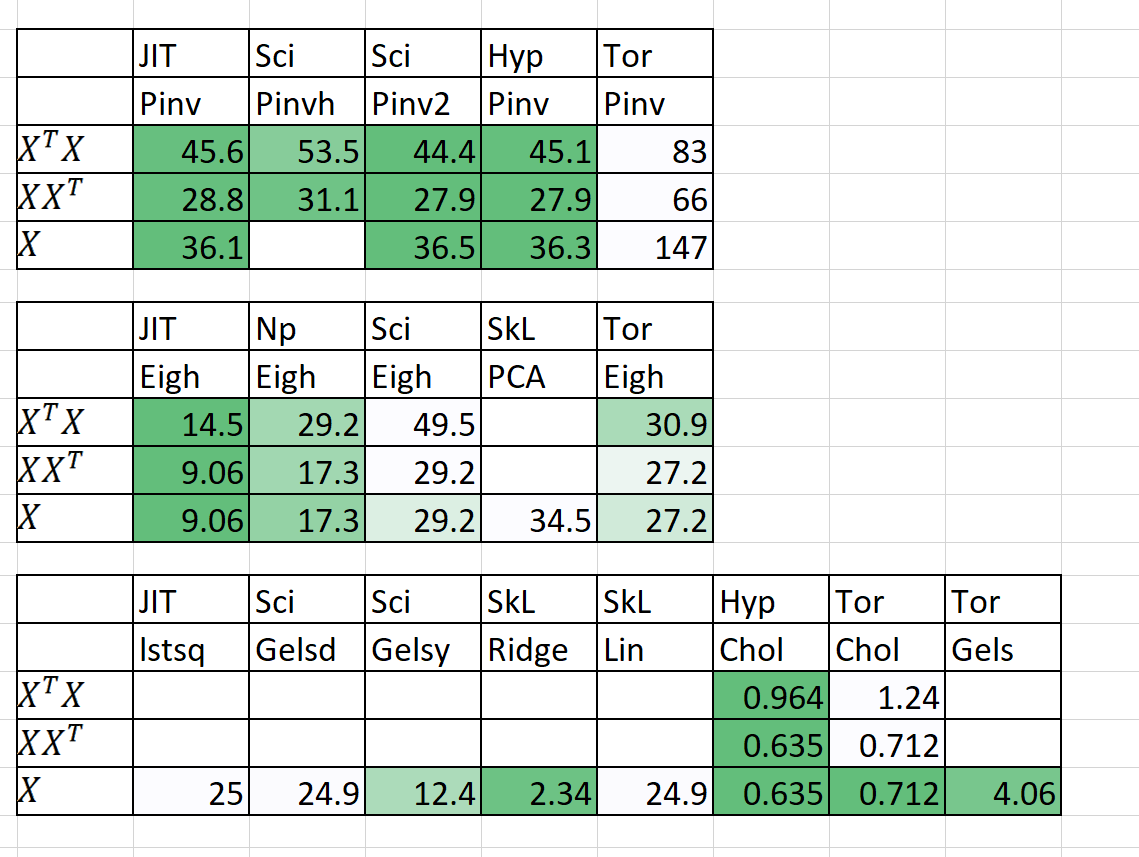
مقارنة السرعة / الذاكرة
| خوارزمية | ن | ص | الوقت (ق) | | رام (MB) | | ملحوظات |
|---|
| | | Sklearn | فرط | Sklearn | فرط | |
| QDA (Quad Dis A) | 1000000 | 100 | 54.2 | 22.25 | 2700 | 1200 | الآن موازية |
| الانحدار الخطي | 1000000 | 100 | 5.81 | 0.381 | 700 | 10 | مضمون مستقر وسريع |
الوقت (ق) هو مناسب + التنبؤ. ذاكرة الوصول العشوائي (MB) = الحد الأقصى (RAM (FIT) ، RAM (توقع))
لقد أضفت أيضًا بعض النتائج الأولية لـ N = 5000 ، P = 6000
المساعدة مطلوبة حقا! أرسل لي رسالة!
المنهجيات والأهداف الرئيسية
1. بالتوازي المحرج للحلقات
2. 50 ٪+ أسرع ، 50 ٪+ أصغر
3. لماذا هي عوامل الإحصائيات في بعض الأحيان بطيئة بشكل لا يطاق؟
4. قطرة التعلم العميق في الوحدات النمطية مع Pytorch
5. 20 ٪+ رمز أقل ، رمز أكثر وضوحا نظافة
6. الوصول إلى خوارزميات جديدة ومثيرة
1. بالتوازي المحرج للحلقات
- بما في ذلك مشاركة الذاكرة وإدارة الذاكرة
- CUDA التوازي من خلال Pytorch & Numba
2. 50 ٪+ أسرع ، 50 ٪+ أصغر
- طلب مضاعفة المصفوفة: https://en.wikipedia.org/wiki/matrix_chain_multiplication
- العنصر الحكيم مصفوفة الضرب تقليل التعقيد إلى O (n^2) من O (n^3): https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- تقليل عمليات المصفوفة إلى تدوين آينشتاين: https://en.wikipedia.org/wiki/einstein_notation
- تقييم عمليات المصفوفة لمرة واحدة على التوالي للحد من ذاكرة الوصول العشوائي.
- إذا كان p >> n ، ربما يكون تحلل XT أفضل من X.
- قد يكون تطبيق تحلل QR ثم SVD أسرع في بعض الحالات.
- الاستفادة من بنية المصفوفة لحساب عكسي أسرع (مثل المصفوفات الثلاثي ، مصفوفات هيرميت).
- الحوسبة SVD (x) ثم الحصول على pinv (x) في بعض الأحيان أسرع من pinv النقي (x)
3. لماذا هي عوامل الإحصائيات في بعض الأحيان بطيئة بشكل لا يطاق؟
- يتم تحسين الثقة ، فترات التنبؤ ، اختبارات الفرضيات وخير اختبارات الملاءمة للنماذج الخطية.
- باستخدام منتجات Einstein تدوين ومنتجات Hadamard حيثما أمكن ذلك.
- حساب فقط ما هو ضروري لحساب (قطري المصفوفة وليس المصفوفة بأكملها).
- إصلاح عيوب النماذج الإحصائية على التدوين والسرعة ومشكلات الذاكرة وتخزين المتغيرات.
4. قطرة التعلم العميق في الوحدات النمطية مع Pytorch
- باستخدام Pytorch لإنشاء Scikit-Learn مثل Drop في البدائل.
5. 20 ٪+ رمز أقل ، رمز أكثر وضوحا نظافة
- باستخدام الديكور والوظائف حيثما أمكن ذلك.
- أسماء وظائف المستوى المتوسط البديهي مثل (iStensor ، Isiterable).
- يتعامل مع التوازي بسهولة من خلال التشويش.
6. الوصول إلى خوارزميات جديدة ومثيرة
- خوارزميات إكمال المصفوفة - المربعات الصغرى غير السلبية ، NNMF
- تخصيص تشابه الدُفعات الكامنة (BS-LDA)
- الانحدار الارتباط
- المربعات الصغرى الممكنة المعممة FGLS
- الانحدار الخارجي المتسامح
- الانحدار متعدد الخطوط متعدد الأبعاد
- الفئران المعممة (أي انخفاض في الاستبدال)
- باستخدام Pyro's Uber للتعلم العميق Bayesian
شروط ترخيص إضافية
- تم اعتماد ترخيص Apache 2.0.