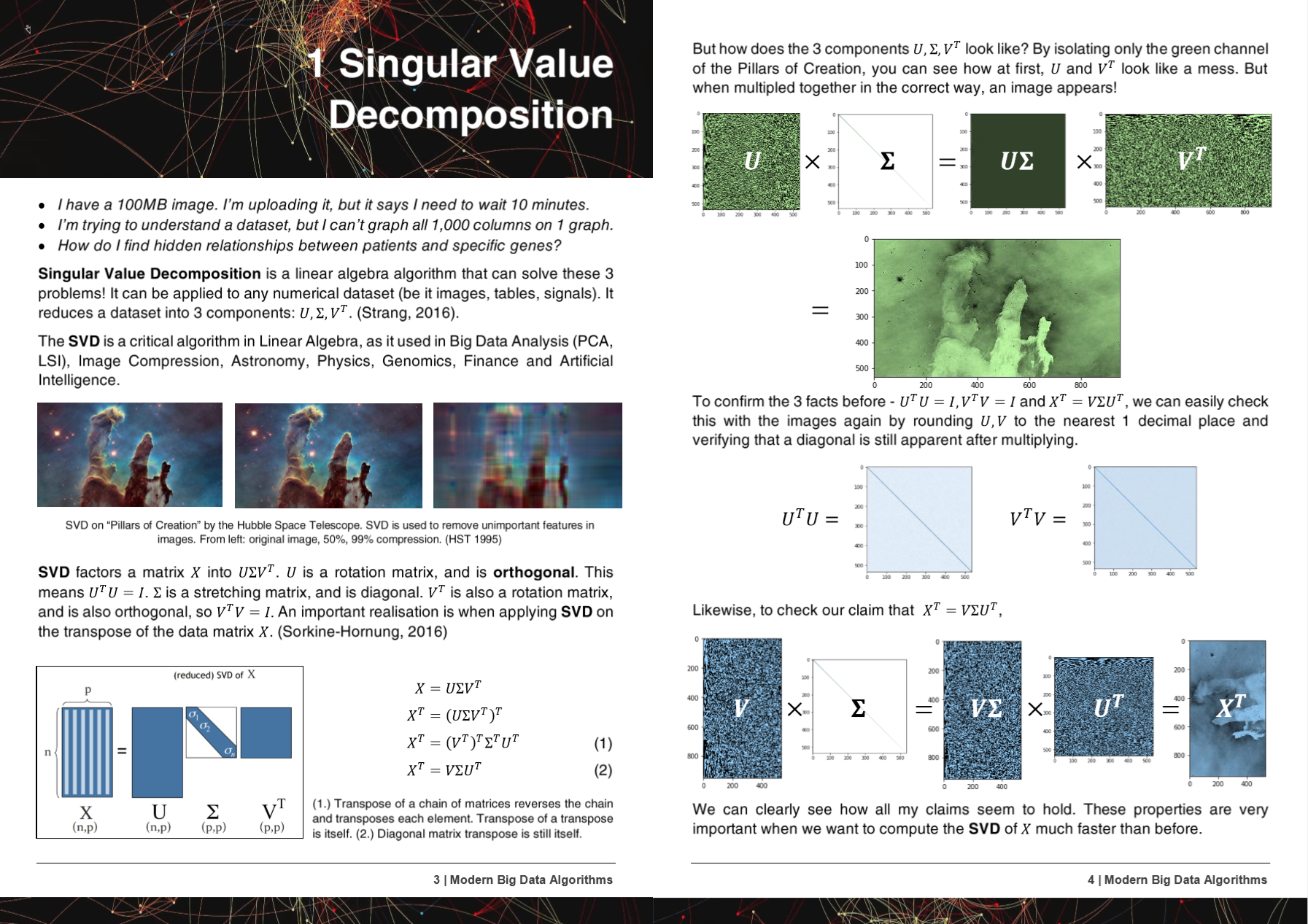
2-2000x faster algos, 50% less memory usage, works on all hardware - new and old.
If you want to collab on fast algorithms - msg me!!
Join our Discord server on making AI faster, or if you just wanna chat about AI!! https://discord.gg/unsloth
Unsloth Website
Documentation
50 Page Modern Big Data Algorithms PDF
Hyperlearn's algorithms, methods and repo has been featured or mentioned in 5 research papers!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft: Yu et al. Making Classical Machine Learning Pipelines Differentiable http://learningsys.org/nips18/assets/papers/45CameraReadySubmissionfinetune.pdf
- University of Washington: Ariel Rokem, Kendrick Kay. Fractional ridge regression: a fast, interpretable reparameterization of ridge regression https://arxiv.org/abs/2005.03220
- National Center for Scientific Research 'Demokritos', Greece: Christos Platias, Georgios Petasis. A Comparison of Machine Learning Methods for Data Imputation https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. GPU Accelerated T-Distributed Stochastic Neighbor Embedding https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/EECS-2020-89.pdf (Incorporated Hyperlearn methods into NVIDIA RAPIDS TSNE)
- NVIDIA: Raschka et al. RAPIDS: Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence https://arxiv.org/abs/2002.04803 (Incorporated Hyperlearn methods into NVIDIA RAPIDS TSNE)
Hyperlearn's methods and algorithms have been incorporated into more than 6 organizations and repositories!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Facebook's Pytorch: SVD very very slow and GELS gives nans, -inf #11174 pytorch/pytorch#11174
- Scipy: EIGH very very slow --> suggesting an easy fix #9212 scipy/scipy#9212
- Cupy: Make SVD overwrite temporary array x cupy/cupy#2277
- NVIDIA: Accelerating TSNE with GPUs: From hours to seconds https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam et al. Large-scale Sku-level Product Detection In Social Media Images And Sales Performance https://www.abstractsonline.com/pp8/#!/9305/presentation/465
During Hyperlearn's development, bugs and issues were notified to GCC!
- GCC 10 ignoring function attribute optimize for all x86 since r11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- Vector Extensions aligned(1) not generating unaligned loads/stores https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- GCC >= 6 cannot inline _mm_cmp_ps on SSE targets https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512 Mask regression from GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

HyperLearn is written completely in PyTorch, NoGil Numba, Numpy, Pandas, Scipy & LAPACK, C++, C, Python, Cython and Assembly, and mirrors (mostly) Scikit Learn.
HyperLearn also has statistical inference measures embedded, and can be called just like Scikit Learn's syntax.
Some key current achievements of HyperLearn:
- 70% less time to fit Least Squares / Linear Regression than sklearn + 50% less memory usage
- 50% less time to fit Non Negative Matrix Factorization than sklearn due to new parallelized algo
- 40% faster full Euclidean / Cosine distance algorithms
- 50% less time LSMR iterative least squares
- New Reconstruction SVD - use SVD to impute missing data! Has .fit AND .transform. Approx 30% better than mean imputation
- 50% faster Sparse Matrix operations - parallelized
- RandomizedSVD is now 20 - 30% faster
Comparison of Speed / Memory
| Algorithm |
n |
p |
Time(s) |
|
RAM(mb) |
|
Notes |
|
|
|
Sklearn |
Hyperlearn |
Sklearn |
Hyperlearn |
|
| QDA (Quad Dis A) |
1000000 |
100 |
54.2 |
22.25 |
2,700 |
1,200 |
Now parallelized |
| LinearRegression |
1000000 |
100 |
5.81 |
0.381 |
700 |
10 |
Guaranteed stable & fast |
Time(s) is Fit + Predict. RAM(mb) = max( RAM(Fit), RAM(Predict) )
I've also added some preliminary results for N = 5000, P = 6000
Help is really needed! Message me!
Key Methodologies and Aims
1. Embarrassingly Parallel For Loops
2. 50%+ Faster, 50%+ Leaner
3. Why is Statsmodels sometimes unbearably slow?
4. Deep Learning Drop In Modules with PyTorch
5. 20%+ Less Code, Cleaner Clearer Code
6. Accessing Old and Exciting New Algorithms
1. Embarrassingly Parallel For Loops
- Including Memory Sharing, Memory Management
- CUDA Parallelism through PyTorch & Numba
2. 50%+ Faster, 50%+ Leaner
- Matrix Multiplication Ordering: https://en.wikipedia.org/wiki/Matrix_chain_multiplication
- Element Wise Matrix Multiplication reducing complexity to O(n^2) from O(n^3): https://en.wikipedia.org/wiki/Hadamard_product_(matrices)
- Reducing Matrix Operations to Einstein Notation: https://en.wikipedia.org/wiki/Einstein_notation
- Evaluating one-time Matrix Operations in succession to reduce RAM overhead.
- If p>>n, maybe decomposing X.T is better than X.
- Applying QR Decomposition then SVD might be faster in some cases.
- Utilise the structure of the matrix to compute faster inverse (eg triangular matrices, Hermitian matrices).
- Computing SVD(X) then getting pinv(X) is sometimes faster than pure pinv(X)
3. Why is Statsmodels sometimes unbearably slow?
- Confidence, Prediction Intervals, Hypothesis Tests & Goodness of Fit tests for linear models are optimized.
- Using Einstein Notation & Hadamard Products where possible.
- Computing only what is neccessary to compute (Diagonal of matrix and not entire matrix).
- Fixing the flaws of Statsmodels on notation, speed, memory issues and storage of variables.
4. Deep Learning Drop In Modules with PyTorch
- Using PyTorch to create Scikit-Learn like drop in replacements.
5. 20%+ Less Code, Cleaner Clearer Code
- Using Decorators & Functions where possible.
- Intuitive Middle Level Function names like (isTensor, isIterable).
- Handles Parallelism easily through hyperlearn.multiprocessing
6. Accessing Old and Exciting New Algorithms
- Matrix Completion algorithms - Non Negative Least Squares, NNMF
- Batch Similarity Latent Dirichelt Allocation (BS-LDA)
- Correlation Regression
- Feasible Generalized Least Squares FGLS
- Outlier Tolerant Regression
- Multidimensional Spline Regression
- Generalized MICE (any model drop in replacement)
- Using Uber's Pyro for Bayesian Deep Learning
Extra License Terms
- The Apache 2.0 license is adopted.