2-2000X Algos más rápidos, 50% menos de uso de memoria, funciona en todo el hardware: nuevo y antiguo.
Si quieres colaborar en algoritmos rápidos, ¡msg yo! ¡Únase a nuestro servidor de Discord para hacer AI más rápido, o si solo quiere chatear sobre AI! https://discord.gg/unsloth
Sitio web nocturno
Documentación
50 páginas Algoritmos de Big Data Modern PDF
¡Los algoritmos, métodos y repositorio de Hyperlearn se han presentado o mencionado en 5 trabajos de investigación!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. Hacer tuberías de aprendizaje automático clásico diferenciable http://learningsys.org/nips18/assets/papers/45cameraradysubmissionfinetune.pdf
- Universidad de Washington : Ariel Rokem, Kendrick Kay. Regresión de la cresta fraccional: una reparametrización rápida e interpretable de la regresión de cresta https://arxiv.org/abs/2005.03220
- Centro Nacional de Investigación Científica 'Demokritos', Grecia : Christos Platias, Georgios Petasis. Una comparación de los métodos de aprendizaje automático para la imputación de datos https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. GPU aceleró el vecino estocástico distribuido en T incrustado https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf (Incorporated HyperLearn Methods en Nvidia Rapids Tsne)
- Nvidia : Raschka et al. Rapids: Aprendizaje automático en Python: desarrollos principales y tendencias de tecnología en ciencia de datos, aprendizaje automático e inteligencia artificial https://arxiv.org/abs/2002.04803 (incorporados métodos de hiperlearn en Nvidia Rapids TSNE)
¡Los métodos y algoritmos de HyperLearn se han incorporado a más de 6 organizaciones y repositorios!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Pytorch de Facebook : SVD muy muy lento y Gels da NANS, -Inf #11174 Pytorch/Pytorch #11174
- Scipy : Muy, muy lento -> sugiriendo una solución fácil #9212 Scipy/Scipy #9212
- CUPY : Haga que SVD sobrescriba una matriz temporal x Cupy/Cupy#2277
- Nvidia : Acelerar TSNE con GPU: de horas a segundos https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam et al. Detección de productos de nivel SKU a gran escala en imágenes de redes sociales y rendimiento de ventas https://www.abstractsonline.com/pp8/#!/9305/presentation/465
¡Durante el desarrollo de Hyperlearn, se notificaron a los errores y problemas a GCC!
- GCC 10 Ignoring Función Atributo Optimizar para todos X86 desde R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- Extensiones vectoriales alineadas (1) No generar cargas/almacenes no alineadas https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- GCC> = 6 no puede en línea _mm_cmp_ps en los objetivos SSE https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 Avx512 Mask Regresion de GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

HyperLearn se escribe completamente en Pytorch, Nogil Numba, Numpy, Pandas, Scipy & Lapack, C ++, C, Python, Cython and Assembly, y Mirrors (en su mayoría) aprenden Scikit. HyperLearn también tiene medidas de inferencia estadística incrustadas, y se puede llamar al igual que la sintaxis de Scikit Learn.
Algunos logros actuales clave de HyperLearn:
- 70% menos tiempo para adaptarse a la regresión de mínimos cuadrados / lineal que Sklearn + 50% menos de uso de la memoria
- 50% menos tiempo para ajustar la factorización de la matriz no negativa que Sklearn debido al nuevo algo paralelo
- Algoritmos de distancia euclidiana / coseno completa de 40% más rápido
- 50% menos de tiempo LSMR Mínimos cuadrados iterativos
- Nuevo SVD de reconstrucción: ¡use SVD para imputar datos faltantes! Tiene .fit y .Transform. Aproximadamente un 30% mejor que la imputación media
- 50% de operaciones de matriz dispersa más rápidas: paralelo
- RandomizedSVD ahora es 20 - 30% más rápido
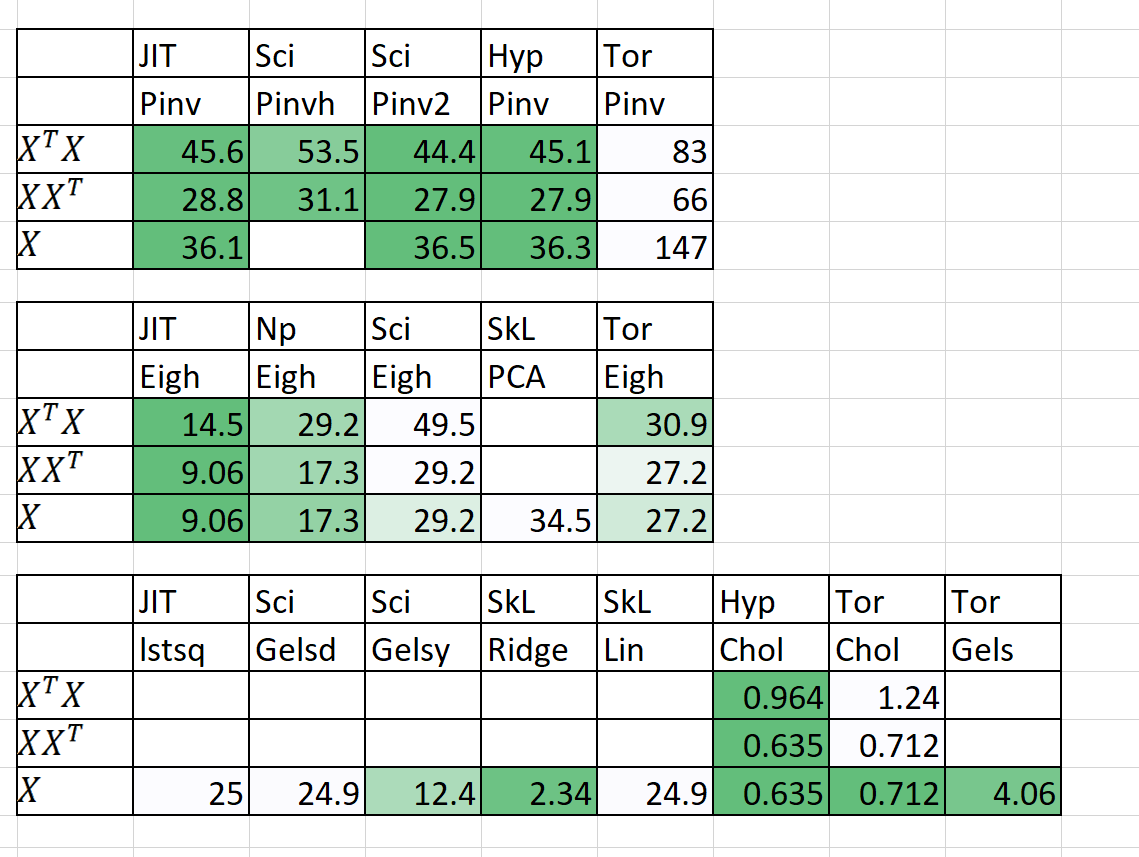
Comparación de la velocidad / memoria
| Algoritmo | norte | pag | Veces) | | RAM (MB) | | Notas |
|---|
| | | Sklearn | Hiperlear | Sklearn | Hiperlear | |
| QDA (Quad dis a) | 1000000 | 100 | 54.2 | 22.25 | 2.700 | 1.200 | Ahora en paralelo |
| Linealregresión | 1000000 | 100 | 5.81 | 0.381 | 700 | 10 | Estable garantizado y rápido |
El tiempo (s) es ajustado + predecir. RAM (MB) = Max (RAM (FIT), RAM (Predicte))
También he agregado algunos resultados preliminares para n = 5000, p = 6000
¡Realmente se necesita ayuda! ¡Envíame un mensaje!
Metodologías y objetivos clave
1. Vergonzosamente paralelo para bucles
2. 50%+ más rápido, 50%+ más delgado
3. ¿Por qué Statsmodels a veces es insoportablemente lento?
4. Drop de aprendizaje profundo en módulos con pytorch
5. 20%+ menos código, código más claro más claro
6. Acceder a nuevos y emocionantes algoritmos
1. Vergonzosamente paralelo para bucles
- Incluido el intercambio de memoria, la gestión de la memoria
- Paralelismo de Cuda a través de Pytorch y Numba
2. 50%+ más rápido, 50%+ más delgado
- Orden de multiplicación de matriz: https://en.wikipedia.org/wiki/matrix_chain_multiplication
- Elemento Wise Matrix Multiplicación reduce la complejidad a o (n^2) de o (n^3): https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- Reducir las operaciones de matriz a la notación de Einstein: https://en.wikipedia.org/wiki/einstein_notation
- Evaluación de operaciones de matriz única en sucesión para reducir la sobrecarga de RAM.
- Si p >> n, tal vez descomponerse XT es mejor que X.
- Aplicando la descomposición de QR, entonces SVD podría ser más rápido en algunos casos.
- Utilice la estructura de la matriz para calcular el inverso más rápido (por ejemplo, matrices triangulares, matrices hermitianas).
- Computar SVD (x) y luego obtener PINV (x) a veces es más rápido que Pinv (X)
3. ¿Por qué Statsmodels a veces es insoportablemente lento?
- Se optimizan la confianza, los intervalos de predicción, las pruebas de hipótesis y las pruebas de bondad de ajuste para modelos lineales.
- Usando la notación de Einstein y los productos Hadamard siempre que sea posible.
- Calculando solo lo que es necesario calcular (diagonal de matriz y no matriz completa).
- Arregle los defectos de Statsmodels en notación, velocidad, problemas de memoria y almacenamiento de variables.
4. Drop de aprendizaje profundo en módulos con pytorch
- Uso de Pytorch para crear Scikit-Learn como Drop en los reemplazos.
5. 20%+ menos código, código más claro más claro
- Uso de decoradores y funciones siempre que sea posible.
- Nombres intuitivos de funciones de nivel medio como (istensor, isiterable).
- Maneja el paralelismo fácilmente a través de hiperlearn.multiprocessing
6. Acceder a nuevos y emocionantes algoritmos
- Algoritmos de finalización de matriz: mínimos cuadrados no negativos, NNMF
- Asignación de lotes de similitud latente de Dirichelt (BS-LDA)
- Regresión de correlación
- FGLS de mínimos cuadrados generalizados factibles
- Regresión tolerante atípica
- Regresión de spline multidimensional
- Ratones generalizados (cualquier caída del modelo en el reemplazo)
- Usando Pyro de Uber para el aprendizaje profundo bayesiano
Términos de licencia adicional
- Se adopta la licencia Apache 2.0.