2-2000x schnellere Algen, 50% weniger Speicherverwendung, arbeitet für alle Hardware - neu und alt.
Wenn Sie mit schnellen Algorithmen zusammenarbeiten möchten - MSG Me !! Schließen Sie sich unserem Discord -Server an, um KI schneller zu machen, oder wenn Sie nur über KI chatten möchten !! https://discord.gg/unsloth
Unloth -Website
Dokumentation
50 Seiten moderne Big Data -Algorithmen PDF
Hyperlearns Algorithmen, Methoden und Repo wurden in 5 Forschungsarbeiten vorgestellt oder erwähnt!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. Machen Sie klassische maschinelle Lernen Pipelines differenzierbar
- Universität Washington : Ariel Rokem, Kendrick Kay. Fractional Ridge Regression: Eine schnelle, interpretierbare Reparameterisierung der Ridge -Regression https://arxiv.org/abs/2005.03220
- Nationales Zentrum für wissenschaftliche Forschung 'Demokritos', Griechenland : Christos Platias, Georgios Petasis. Ein Vergleich von Methoden für maschinelles Lernen für Daten Imputation https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan. GPU beschleunigten t-verteilte stochastische Nachbarn einbetten https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf (integrierte Hyperlearne-Methoden in NVIDIA-Vergewaltigungen TSne)
- Nvidia : Raschka et al. Rapids: maschinelles Lernen in Python: Hauptentwicklungen und Technologie -Trends in Datenwissenschaft, maschinellem Lernen und künstlicher Intelligenz https://arxiv.org/abs/2002.04803 (Incorporated Hyperlearn -Methoden in Nvidia Rapids Tsne)
Die Methoden und Algorithmen von Hyperlearn wurden in mehr als 6 Organisationen und Repositorys aufgenommen!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- Pytorch von Facebook : SVD sehr sehr langsam und Gele gibt Nans, -inf #11174 Pytorch/Pytorch #11174
- SCIPY : EIGH sehr sehr langsam -> Vorschlägt eine einfache Fix #9212 Scipy/Scipy #9212
- Cupy : Machen Sie SVD überschreiben Temporäres Array x Cupy/Cupy#2277
- Nvidia : Beschleunigung von Tsne mit GPUs: Von Stunden bis Sekunden
- Unw Abdussalam et al. Large-Skale-Produkterkennung in Social-Media-Bildern und Vertriebsleistung https://www.abstractsonline.com/pp8/#!/9305/presentation/465
Während der Entwicklung von Hyperlearn wurden GCC Bugs und Probleme mitgeteilt!
- GCC 10 Ignorieren von Funktionsattribut für alle x86 seit R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- Vektorerweiterungen ausgerichtet (1) Nicht ausgerichtete Lasten/Speichern https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- Gcc> = 6 kann nicht inline _mm_cmp_ps auf SSE -Zielen https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387 kann
- GCC 10.2 AVX512 Mask -Regression von GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

Hyperlearn ist vollständig in Pytorch, Nogil Numba, Numpy, Pandas, Scipy & Lapack, C ++, C, Python, Cython und Assembly und Spiegel (meistens) Scikit Learn geschrieben. Hyperlearn hat auch statistische Inferenzmaßnahmen eingebettet und kann genannt werden wie die Syntax von Scikit Learn.
Einige wichtige aktuelle Erfolge von Hyperlearn:
- 70% weniger Zeit, um die kleinsten Quadrate / lineare Regression zu erreichen als Sklearn + 50% weniger Speicherverwendung
- 50% weniger Zeit für die nicht negative Matrixfaktorisierung als sklearn aufgrund neuer parallelisierter Algo
- 40% schnellere volle euklidische / Cosinus -Distanzalgorithmen
- 50% weniger Zeit LSMR Iterative kleinste Quadrate
- Neue Rekonstruktion SVD - Verwenden Sie SVD, um fehlende Daten zu lindern! Hat .fit und .transform. Ca. 30% besser als mittlere Imputation
- 50% schnellere spärliche Matrixoperationen - parallelisiert
- RandomizedSvd ist jetzt 20 - 30% schneller
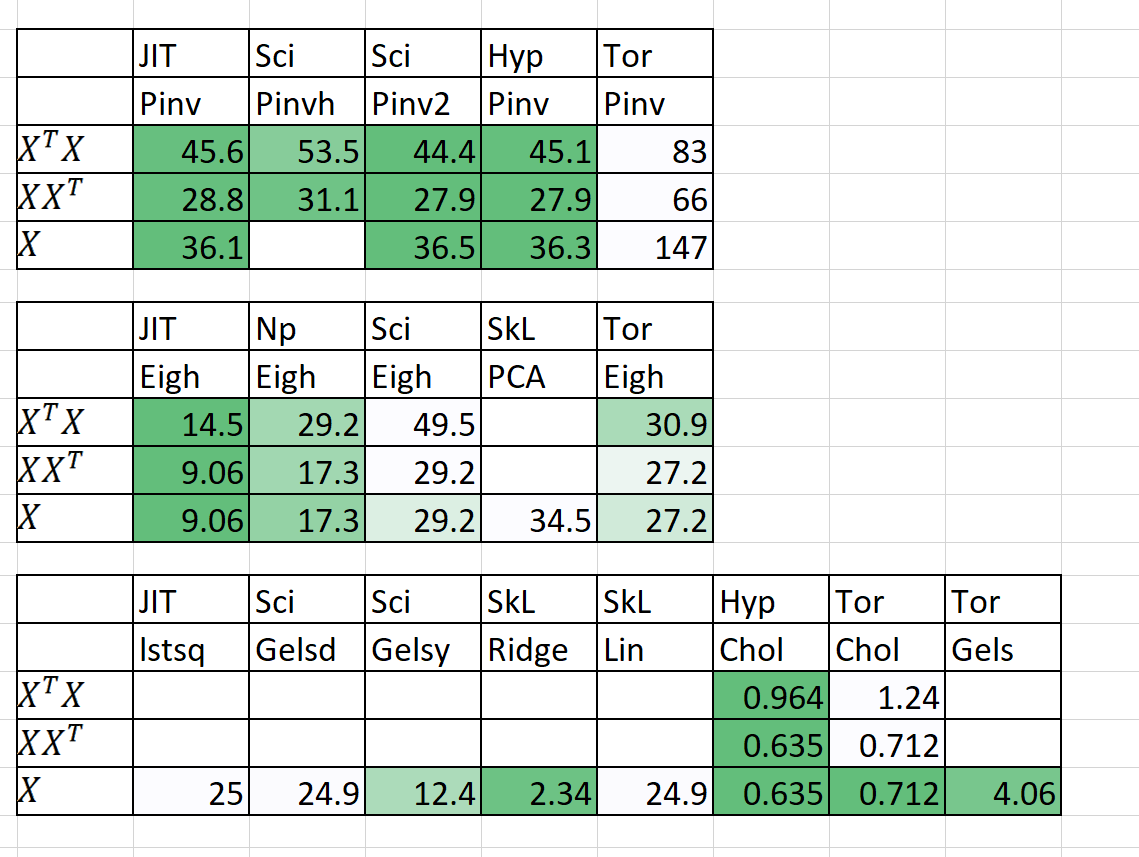
Vergleich von Geschwindigkeit / Speicher
| Algorithmus | N | P | Mal) | | RAM (MB) | | Notizen |
|---|
| | | Sklearn | Hyperlearn | Sklearn | Hyperlearn | |
| Qda (quad dis a) | 1000000 | 100 | 54.2 | 22.25 | 2.700 | 1.200 | Jetzt parallelisiert |
| Linearregression | 1000000 | 100 | 5.81 | 0,381 | 700 | 10 | Garantiert stabil und schnell |
Die Zeit (en) ist fit + vorhersagen. RAM (mb) = max (RAM (fit), RAM (vorhersagen))
Ich habe auch einige vorläufige Ergebnisse für n = 5000, p = 6000 hinzugefügt
Hilfe ist wirklich gebraucht! Nachricht an mich!
Schlüsselmethoden und Ziele
1. peinlich parallel für Schleifen
2. 50%+ schneller, 50%+ schlanker
3. Warum sind StatsModels manchmal unerträglich langsam?
4. Deep Learning Drop in Modulen mit Pytorch
5. 20%+ weniger Code, Cleaner Clearer Code
6. Zugriff auf alte und aufregende neue Algorithmen
1. peinlich parallel für Schleifen
- Einschließlich Speicherfreigabe, Speicherverwaltung
- CUDA -Parallelität durch Pytorch & Numba
2. 50%+ schneller, 50%+ schlanker
- Matrix -Multiplikationsbestellung: https://en.wikipedia.org/wiki/matrix_chain_multiplication
- Element Wise Matrix -Multiplikation reduzieren die Komplexität auf o (n^2) von o (n^3): https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- Reduzierende Matrixoperationen auf Einstein Notation: https://en.wikipedia.org/wiki/einstein_notation
- Bewertung der einmaligen Matrixoperationen nacheinander, um den RAM-Overhead zu reduzieren.
- Wenn p >> n, ist das Zerlegen von XT vielleicht besser als X.
- Anwendung der QR -Zerlegung, dann kann SVD in einigen Fällen schneller sein.
- Verwenden Sie die Struktur der Matrix, um schnellere inverse zu berechnen (z. B. dreieckige Matrizen, Hermitianmatrizen).
- Das Berechnen von SVD (x) und Pinv (x) ist manchmal schneller als reiner Pinv (x)
3. Warum sind StatsModels manchmal unerträglich langsam?
- Vertrauen, Vorhersageintervalle, Hypothesentests und Güte von Fit -Tests für lineare Modelle sind optimiert.
- Verwendung von Einstein Notation & Hadamard -Produkten, wo möglich.
- Berechnen Sie nur, was markiert ist, um zu berechnen (Diagonale der Matrix und nicht die gesamte Matrix).
- Behebung der Fehler von Statsmodels auf Notation, Geschwindigkeit, Speicherproblemen und Speicherung von Variablen.
4. Deep Learning Drop in Modulen mit Pytorch
- Verwenden Sie Pytorch zum Erstellen von Scikit-Learn wie Tropfen der Ersatz.
5. 20%+ weniger Code, Cleaner Clearer Code
- Verwenden von Dekoratoren und Funktionen nach Möglichkeit.
- Intuitive Funktionsnamen mit mittlerer Ebene wie (iStensor, iterable).
- Verarbeitet die Parallelität leicht durch Hyperlearn.multiprocessing
6. Zugriff auf alte und aufregende neue Algorithmen
- Matrix -Abschlussalgorithmen - nicht negative kleinste Quadrate, NNMF
- Batch-Ähnlichkeit Latent Dirichelt Allocation (BS-LDA)
- Korrelationsregression
- Realisierbare verallgemeinerte kleinste Quadrate fgls
- Ausreißer tolerante Regression
- Mehrdimensionale Spline -Regression
- Verallgemeinerte Mäuse (jeder Modellabfall des Austauschs)
- Verwenden Sie Ubers Pyro für Bayesian Deep Learning
Zusätzliche Lizenzbedingungen
- Die Apache 2.0 -Lizenz wird angenommen.