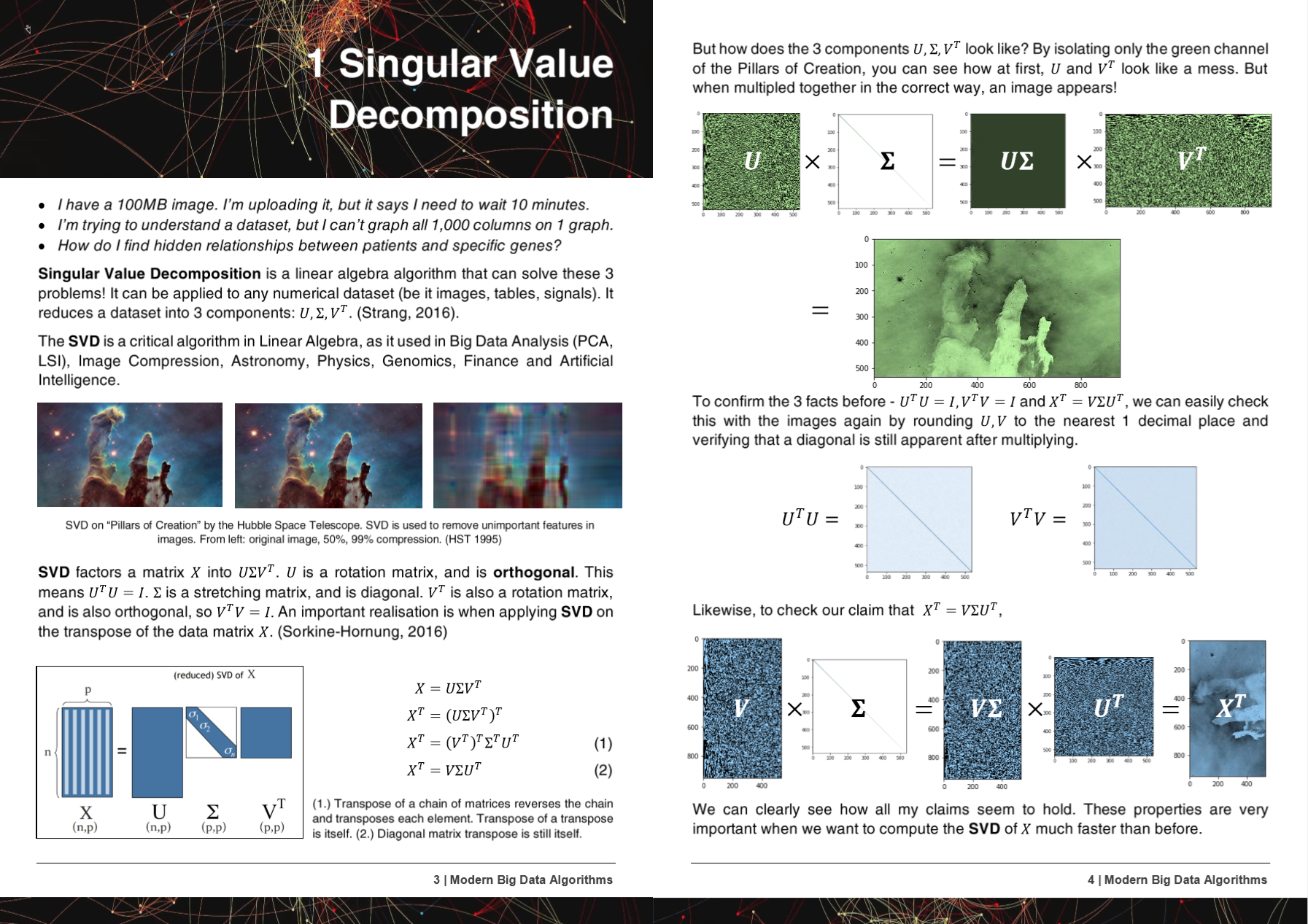
อัลกอสที่เร็วขึ้น 2-2000X การใช้หน่วยความจำน้อยกว่า 50% ทำงานกับฮาร์ดแวร์ทั้งหมด - ใหม่และเก่า
หากคุณต้องการร่วมมือกันในอัลกอริทึม Fast - MSG ME !! เข้าร่วมเซิร์ฟเวอร์ Discord ของเราในการทำให้ AI เร็วขึ้นหรือถ้าคุณแค่อยากคุยเกี่ยวกับ AI !! https://discord.gg/unsloth
เว็บไซต์ unsloth
เอกสาร
50 หน้าอัลกอริทึมข้อมูลขนาดใหญ่ที่ทันสมัย PDF
อัลกอริทึมวิธีการและ repo ของ Hyperlearn ได้รับการแนะนำหรือกล่าวถึงใน 5 งานวิจัย!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- Microsoft : Yu et al. การทำท่อการเรียนรู้ของเครื่องคลาสสิกที่แตกต่างกัน http://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- มหาวิทยาลัยวอชิงตัน : Ariel Rokem, Kendrick Kay การถดถอยของสันเขาเศษส่วน: การเปลี่ยนรูปแบบที่รวดเร็วและตีความได้ของการถดถอยสันเขา https://arxiv.org/abs/2005.03220
- ศูนย์วิจัยวิทยาศาสตร์แห่งชาติ 'Demokritos', กรีซ : Christos Platias, Georgios Petasis การเปรียบเทียบวิธีการเรียนรู้ของเครื่องสำหรับการใส่ข้อมูล https://dl.acm.org/doi/10.1145/3411408.3411465
- UC Berkeley David Chan GPU เร่ง T-Distributed เพื่อนบ้าน Stochastic Embedding https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf
- Nvidia : Raschka และคณะ Rapids: การเรียนรู้ของเครื่องจักรใน Python: การพัฒนาหลักและแนวโน้มเทคโนโลยีในวิทยาศาสตร์ข้อมูลการเรียนรู้ของเครื่องจักรและปัญญาประดิษฐ์ https://arxiv.org/abs/2002.04803
วิธีการและอัลกอริทึมของ Hyperlearn ได้ถูกรวมเข้ากับองค์กรและที่เก็บมากกว่า 6 แห่ง!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- pytorch ของ Facebook : SVD ช้ามากและเจลให้ NANS, -inf #11174 Pytorch/Pytorch #11174
- Scipy : Eigh มากช้ามาก -> แนะนำการแก้ไขง่าย ๆ #9212 Scipy/Scipy #9212
- Cupy : ทำ SVD overwrite อาร์เรย์ชั่วคราว x cupy/cupy#2277
- NVIDIA : เร่ง TSNE ด้วย GPU: จากชั่วโมงถึงวินาที https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam และคณะ การตรวจจับผลิตภัณฑ์ระดับ SKU ขนาดใหญ่ในภาพโซเชียลมีเดียและประสิทธิภาพการขาย
ในระหว่างการพัฒนาของ Hyperlearn ข้อบกพร่องและปัญหาได้รับแจ้งถึง GCC!
- GCC 10 การละเว้นแอตทริบิวต์ฟังก์ชั่นที่เหมาะสมสำหรับ x86 ทั้งหมดตั้งแต่ R11-1019 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- การขยายเวกเตอร์จัดตำแหน่ง (1) ไม่ได้สร้างโหลด/เก็บที่ไม่ได้จัดเรียง https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- gcc> = 6 ไม่สามารถ inline _mm_cmp_ps บนเป้าหมาย SSE https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512 การถดถอยหน้ากากจาก GCC 9 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

Hyperlearn เขียนขึ้นอย่างสมบูรณ์ใน Pytorch, Nogil Numba, Numpy, Pandas, Scipy & Lapack, C ++, C, Python, Cython และ Assembly และ Mirrors (ส่วนใหญ่) Scikit เรียนรู้ Hyperlearn ยังมีมาตรการการอนุมานทางสถิติที่ฝังอยู่และสามารถเรียกได้เช่นเดียวกับไวยากรณ์ของ Scikit Learn
ความสำเร็จในปัจจุบันของ Hyperlearn:
- เวลาน้อยลง 70% ในการพอดีกับการถดถอยแบบสี่เหลี่ยมจัตุรัสน้อยที่สุด
- ใช้เวลาน้อยลง 50% ในการปรับตัวประกอบเมทริกซ์เชิงลบมากกว่า Sklearn เนื่องจาก Algo แบบขนานใหม่
- อัลกอริทึมระยะทางยุคลิด / โคไซน์ที่เร็วขึ้น 40%
- เวลาน้อยกว่า 50% LSMR ITERATION Squares น้อยที่สุด
- ใหม่ใหม่ SVD - ใช้ SVD เพื่อระบุข้อมูลที่หายไป! มี. fit และ. transform ดีกว่าค่าเฉลี่ยประมาณ 30%
- การดำเนินการเมทริกซ์เบาบางที่เร็วกว่า 50% - ขนานกัน
- RandomizedSVD ตอนนี้เร็วขึ้น 20 - 30%
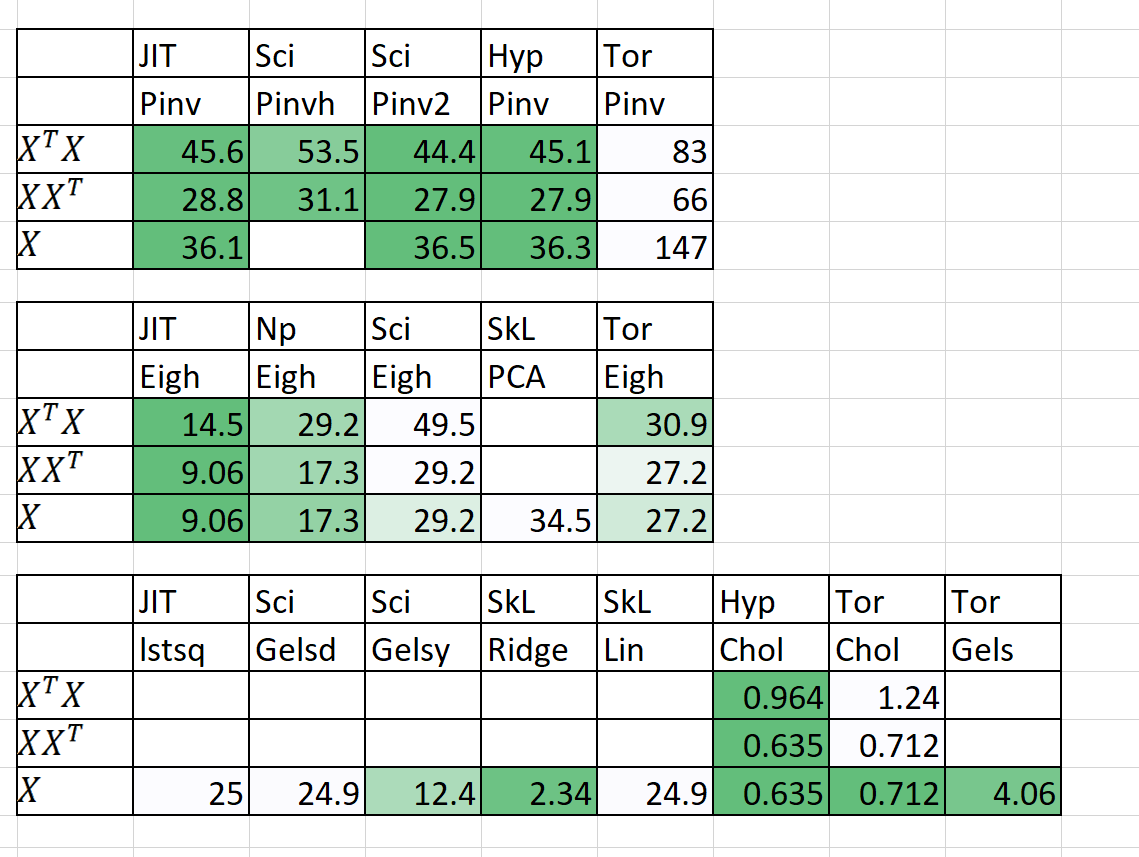
การเปรียบเทียบความเร็ว / หน่วยความจำ
| อัลกอริทึม | n | P | เวลา | | RAM (MB) | | หมายเหตุ |
|---|
| | | Sklearn | hyperlearn | Sklearn | hyperlearn | |
| QDA (Quad Dis A) | 10,00000 | 100 | 54.2 | 22.25 | 2,700 | 1,200 | ตอนนี้ขนานกัน |
| linearregression | 10,00000 | 100 | 5.81 | 0.381 | 700 | 10 | รับประกันเสถียรและรวดเร็ว |
เวลาคือพอดี + ทำนาย RAM (MB) = สูงสุด (RAM (พอดี), RAM (ทำนาย))
ฉันยังได้เพิ่มผลลัพธ์เบื้องต้นสำหรับ n = 5000, p = 6000
ความช่วยเหลือเป็นสิ่งจำเป็นจริงๆ! ส่งข้อความถึงฉัน!
วิธีการและจุดมุ่งหมายที่สำคัญ
1. ขนานกันอย่างน่าอายสำหรับลูป
2. 50%+ เร็วขึ้น 50%+ Leaner
3. ทำไมบางครั้ง Statsmodels จึงช้าเหลือทนไม่ได้?
4. การเรียนรู้อย่างลึกลงไปในโมดูลด้วย pytorch
5. รหัส 20%+ น้อยกว่ารหัสทำความสะอาดที่ชัดเจนขึ้นรหัส
6. การเข้าถึงอัลกอริทึมใหม่ที่เก่าและน่าตื่นเต้น
1. ขนานกันอย่างน่าอายสำหรับลูป
- รวมถึงการแชร์หน่วยความจำการจัดการหน่วยความจำ
- cuda parallelism ผ่าน pytorch & numba
2. 50%+ เร็วขึ้น 50%+ Leaner
- การสั่งสอนการคูณเมทริกซ์: https://en.wikipedia.org/wiki/Matrix_Chain_Multiplication
- องค์ประกอบที่ชาญฉลาดเมทริกซ์การคูณการลดความซับซ้อนของ o (n^2) จาก o (n^3): https://en.wikipedia.org/wiki/hadamard_product_(Matrices)
- การลดการดำเนินงานของเมทริกซ์ไปยังสัญกรณ์ Einstein: https://en.wikipedia.org/wiki/Einstein_Notation
- การประเมินการดำเนินการเมทริกซ์ครั้งเดียวอย่างต่อเนื่องเพื่อลดค่าใช้จ่าย RAM
- ถ้า p >> n อาจย่อยสลาย XT จะดีกว่า X
- การใช้การสลายตัวของ QR จากนั้น SVD อาจเร็วขึ้นในบางกรณี
- ใช้โครงสร้างของเมทริกซ์เพื่อคำนวณค่าผกผันเร็วขึ้น (เช่นเมทริกซ์สามเหลี่ยม, เมทริกซ์เฮอร์มิน)
- การคำนวณ SVD (X) จากนั้นรับ PINV (X) บางครั้งก็เร็วกว่า pinv บริสุทธิ์ (x)
3. ทำไมบางครั้ง Statsmodels จึงช้าเหลือทนไม่ได้?
- ความมั่นใจช่วงเวลาการทำนายการทดสอบสมมติฐานและความดีของการทดสอบแบบพอดีสำหรับแบบจำลองเชิงเส้นได้รับการปรับให้เหมาะสม
- ใช้ผลิตภัณฑ์ Notation & Hadamard Einstein หากเป็นไปได้
- การคำนวณเฉพาะสิ่งที่จำเป็นในการคำนวณ (เส้นทแยงมุมของเมทริกซ์และไม่ใช่เมทริกซ์ทั้งหมด)
- การแก้ไขข้อบกพร่องของ Statsmodels เกี่ยวกับสัญกรณ์ความเร็วปัญหาหน่วยความจำและการจัดเก็บของตัวแปร
4. การเรียนรู้อย่างลึกลงไปในโมดูลด้วย pytorch
- การใช้ pytorch เพื่อสร้าง scikit-learn เหมือน drop in replacements
5. รหัส 20%+ น้อยกว่ารหัสทำความสะอาดที่ชัดเจนขึ้นรหัส
- ใช้นักตกแต่งและฟังก์ชั่นที่เป็นไปได้
- ชื่อฟังก์ชั่นระดับกลางที่ใช้งานง่ายเช่น (istensor, isiterable)
- จัดการความเท่าเทียมได้อย่างง่ายดายผ่าน hyperlearn.multiprocessing
6. การเข้าถึงอัลกอริทึมใหม่ที่เก่าและน่าตื่นเต้น
- อัลกอริทึมการทำให้เสร็จสมบูรณ์ของเมทริกซ์ - ไม่ใช่กำลังสองลบอย่างน้อย, NNMF
- ชุดการจัดสรร Dirichelt ที่คล้ายคลึงกัน (BS-LDA)
- การถดถอยสหสัมพันธ์
- FGLS กำลังสองน้อยที่สุดที่เป็นไปได้ทั่วไป
- การถดถอยแบบทนต่อ
- การถดถอยแบบหลายมิติ
- หนูทั่วไป (แบบจำลองใด ๆ ลดลง)
- ใช้ Pyro ของ Uber สำหรับการเรียนรู้อย่างลึกซึ้งแบบเบย์
เงื่อนไขใบอนุญาตพิเศษ
- ใบอนุญาต Apache 2.0 ถูกนำมาใช้