2-2000 Xのより速いアルゴ、50%少ないメモリ使用量は、新旧のすべてのハードウェアで動作します。
高速アルゴリズムで協力したい場合-MSGME !! AIを高速にするために、またはAIについてチャットしたい場合は、Discordサーバーに参加してください!! https://discord.gg/unsloth
スロートウェブサイト
ドキュメント
50ページ最新のビッグデータアルゴリズムPDF
Hyperlearnのアルゴリズム、方法、およびレポは、5つの研究論文で紹介または言及されています!
+ Microsoft, UW, UC Berkeley, Greece, NVIDIA
- マイクロソフト:Yu et al。古典的な機械学習パイプラインを作成する差別化可能なhttp://learningsys.org/nips18/assets/papers/45camerareadysubmissionfinetune.pdf
- ワシントン大学:アリエル・ロケム、ケンドリック・ケイ。分数リッジ回帰:尾根回帰の高速で解釈可能な再評価https://arxiv.org/abs/2005.03220
- 国立科学研究センター「デモクリトス」、ギリシャ:クリストス・プラティアス、ゲオルギオス・ペタシス。データの代入https://dl.acm.org/doi/10.1145/3411408.3411465の機械学習方法の比較
- UC Berkeley David Chan。 GPUは、https://digitalassets.lib.berkeley.edu/techreports/ucb/incoming/eecs-2020-89.pdf (nvidia Rapids tsneに組み込まれたHyperlearn Methodsに組み込まれている)を加速しました。
- Nvidia :Raschka et al。ラピッズ:Pythonの機械学習:データサイエンス、機械学習、人工知能の主な開発と技術動向https://arxiv.org/abs/2002.04803
Hyperlearnの方法とアルゴリズムは、6つ以上の組織とリポジトリに組み込まれています!
+ NASA + Facebook's Pytorch, Scipy, Cupy, NVIDIA, UNSW
- FacebookのPytorch :SVDは非常に遅く、ゲルはNANSを提供します-INF#11174 Pytorch/Pytorch#11174
- scipy :非常に遅い - >簡単な修正を提案#9212 scipy/scipy#9212
- Cupy :SVDを上書きする一時的な配列x Cupy/Cupy#2277
- nvidia :gpusでtsneを加速する:営業時間から秒https://medium.com/rapids-ai/tsne-with-gpus-hours-to-seconds-9d9c17c941db
- UNSW Abdussalam et al。ソーシャルメディアイメージと販売パフォーマンスの大規模なSKUレベルの製品検出https://www.abstractsonline.com/pp8/# !/9305/presentation/465
Hyperlearnの開発中、バグと問題はGCCに通知されました!
- GCC 10無視機能属性r11-1019以降のすべてのx86の最適化https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96535
- アライメントされたベクトル拡張機能(1)整列されていない負荷/ストアが生成されないhttps://gcc.gnu.org/bugzilla/show_bug.cgi?id=98317
- gcc> = 6 SSEターゲットのインライン_mm_cmp_ps https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98387
- GCC 10.2 AVX512 GCCからのマスク回帰https://gcc.gnu.org/bugzilla/show_bug.cgi?id=98348

Hyperlearnは、Pytorch、Nogil Numba、Numpy、Pandas、Scipy&Lapack、C ++、C、Python、Cython and Assembly、およびMirrors(ほとんど)Scikit Learnで完全に書かれています。 HyperLearnには統計的推論測定値も組み込まれており、Scikit Learnの構文と同じように呼び出すことができます。
Hyperlearnのいくつかの重要な現在の成果:
- Sklearnよりも最小二乗 /線形回帰に適合するまでの時間が70% +メモリの使用量が50%少ない
- 新しい並列化されたアルゴのために、Sklearnよりも非負のマトリックス因数分解に適合する時間が50%短い
- 40%フルフルユークリッド /コサイン距離アルゴリズム
- 50%短い時間LSMR反復最小二乗
- New Reconstruction SVD -SVDを使用して欠落データを誘発します! .fitおよび.transformがあります。平均代入よりも約30%優れています
- 50%速いスパースマトリックス操作 - 並列
- ランダム化SVDは20〜30%高速になりました
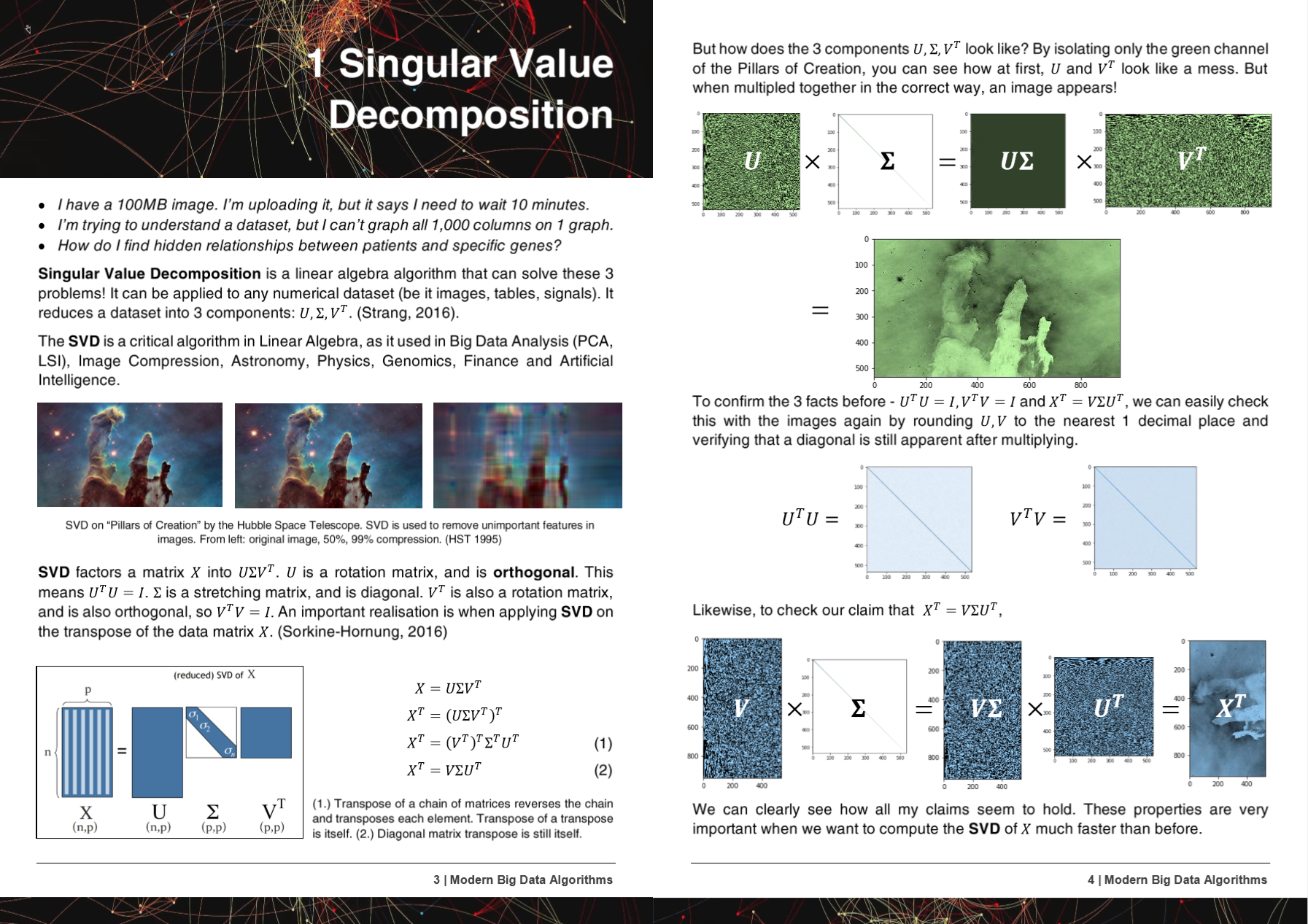
速度 /メモリの比較
| アルゴリズム | n | p | 時間 | | ラム(MB) | | メモ |
|---|
| | | Sklearn | Hyperlearn | Sklearn | Hyperlearn | |
| qda(quad dis a) | 1000000 | 100 | 54.2 | 22.25 | 2,700 | 1,200 | 現在平行になっています |
| 線形回帰 | 1000000 | 100 | 5.81 | 0.381 | 700 | 10 | 安定した高速で保証されています |
時間はフィット +予測です。 ram(mb)= max(ram(fit)、ram(predict))
また、n = 5000、p = 6000の予備結果も追加しました
本当に必要があります!私にメッセージを送ってください!
主要な方法論と目的
1。ループには恥ずかしいほど並行しています
2。50%+より速く、50%+ Leaner
3.なぜstatsmodelsが耐え難いほど遅いのはなぜですか?
4. Pytorchを使用したモジュールの深い学習ドロップ
5。20%以上コードが少なく、クリーンクリアコード
6.古くてエキサイティングな新しいアルゴリズムへのアクセス
1。ループには恥ずかしいほど並行しています
- メモリ共有、メモリ管理を含む
- Pytorch&Numbaを介したCuda並列処理
2。50%+より速く、50%+ Leaner
- マトリックス乗算順序:https://en.wikipedia.org/wiki/matrix_chain_multiplication
- Element Wise Matrix乗算複雑さをO(n^2)からO(n^3)からO(n^2)に減らす:https://en.wikipedia.org/wiki/hadamard_product_(matrices)
- アインシュタイン表記へのマトリックス操作の削減:https://en.wikipedia.org/wiki/einstein_notation
- 1回限りのマトリックス操作を連続して評価して、RAMオーバーヘッドを減らします。
- p >> nの場合、XTの分解がXよりも優れている可能性があります。
- QR分解を適用すると、SVDは場合によってはより速くなる可能性があります。
- マトリックスの構造を利用して、より速い逆数(例えば三角形のマトリックス、エルミートマトリックス)を計算します。
- コンピューティングSVD(x)その後、pinv(x)を取得することは、純粋なpinv(x)よりも高速になることがあります
3.なぜstatsmodelsが耐え難いほど遅いのはなぜですか?
- 信頼性、予測間隔、仮説テスト、線形モデルの適合度テストの良さが最適化されています。
- 可能であれば、Einstein Notation&Hadamard製品を使用します。
- 計算するためのネクサリーのみを計算します(マトリックス全体ではなく、マトリックスの対角線)。
- 表記、速度、メモリの問題、変数のストレージに関する統計誤った欠陥を修正します。
4. Pytorchを使用したモジュールの深い学習ドロップ
- Pytorchを使用して、交換のドロップなどのScikit-Learnを作成します。
5。20%以上コードが少なく、クリーンクリアコード
- 可能であればデコレーターと機能を使用します。
- (ISTENSOR、ISETERABLE)のような直感的な中間レベルの関数名。
- hyperlearn.multiprocessingを介して簡単に並行性を処理します
6.古くてエキサイティングな新しいアルゴリズムへのアクセス
- マトリックス完了アルゴリズム - 非負の最小二乗、NNMF
- バッチの類似性潜在的なディリチェルト割り当て(BS-LDA)
- 相関回帰
- 実行可能な一般化最小二乗FGL
- 異常値の耐性回帰
- 多次元スプライン回帰
- 一般化されたマウス(代替のモデルの低下)
- ベイジアンディープラーニングにUberのPyroを使用します
追加のライセンス条件
- Apache 2.0ライセンスが採用されています。