data efficient gans
1.0.0

仅使用100张奥巴马,脾气暴躁的猫,熊猫,叹息的桥,美第奇喷泉,天堂庙,没有预先训练而产生。
[new!]使用Diffaigment-Stylegan2-Pytorch进行的Pytorch培训现已上市!
[new!]我们的COLAB教程已发布!
[new!] FFHQ培训得到了支持!请参阅Diffaugment-Stylegan2 readme。
[new!]是时候使用generate_gif.py生成100张插值视频了!
[new!]我们的diffaigment-biggan-imagenet repo(用于TPU培训)已发布!
[new!]我们的diffaigment-biggan-cifar pytorch存储库已发布!
该存储库包含我们在Pytorch和TensorFlow中实现可区分的增强(差异)。它可用于显着提高GAN培训的数据效率。我们为GPU训练提供了diffaight-stylegan2(Tensorflow)和Diffaigment-Stylegan2-Pytorch,diffaigment-biggan-cifar(pytorch),以及用于TPU训练的diffaigment-biggan-imagenet(Tensorflow)。

低射击生成而没有预训练。使用Diffaigment,我们的模型只能使用我们收集的100张数据集,160只猫或389狗从Animalface数据集中以256×256分辨率从我们收集的100张猫或389只狗中产生高保真图像。
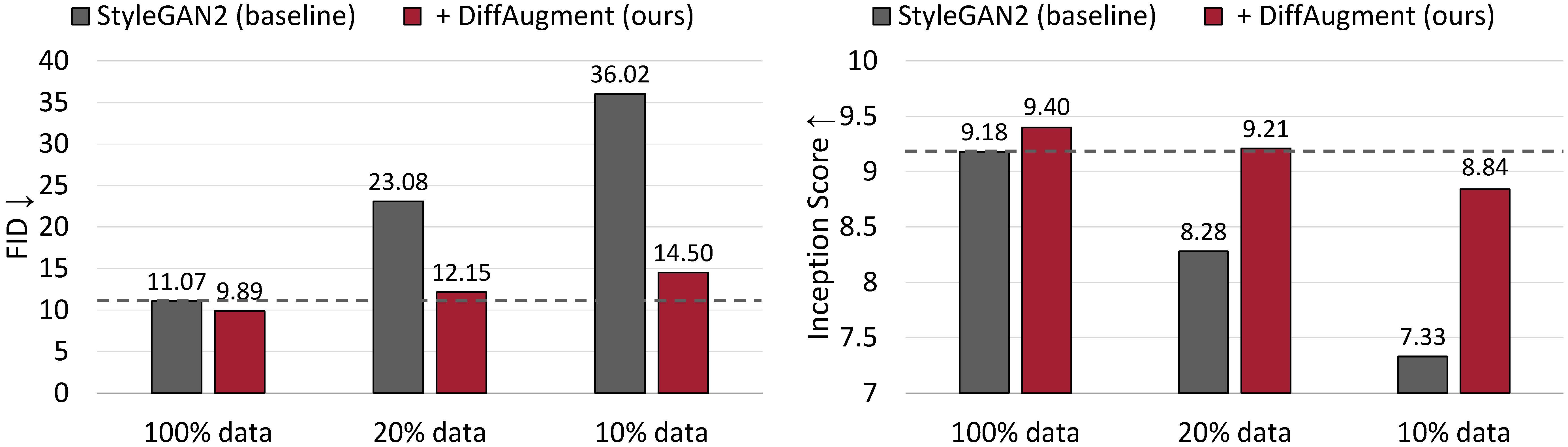
CIFAR-10的无条件产生结果。在培训数据的情况下,StyleGAN2的性能会大大降级。通过Diffaigment,我们只能使用20%的培训数据大致匹配其FID,并胜过其成立得分(IS)。
用于数据效率GAN培训的可区分增强
Shengyu Zhao,Zhijian Liu,Ji Lin,Jun-Yan Zhu和Song Han
MIT,Tsinghua大学,Adobe Research,CMU
arxiv

更新D(左)和G(右)的Diffaigment概述。 Diffaigment将增强t应用于真实样品X和生成的输出g(z)。当我们更新G时,需要通过t(iii)对梯度进行后传达,这需要t是可区分的输入。
使用我们的预训练模型生成插值视频:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gif或培训新型号:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4您也可以尝试100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen ,或包含您自己培训图像的文件夹。有关依赖项和详细信息,请参阅Diffaigment-Stylegan2 redme。
[new!] Pytorch培训现已上市:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1要在100张数据集(CIFAR,FFHQ或LSUN)上运行stylegan2 + diffaigment ,请参阅Diffaigment-Stylegan2 readme或diffaighatment-stylegan2-pytorch,以获取Pytorch版本。
请参阅diffaigment-biggan-cifar redme以在CIFAR(使用GPU)上运行Biggan + Diffaigment ,以及在Imagenet上运行的Diffaigment-biggan-Imagenet Readme(使用TPU)。
为了帮助您在自己的代码库中使用Diffaigment,我们在diffaugment_tf.py and diffaugment_pytorch.py中提供Tensorflow和Pytorch版本的便携式功能操作。通常,在任何模型中都可以轻松地通过将每个d(x)用d(t(x))替换,其中x可以是真实的图像或假图像, d是歧视器,而t是差异操作。例如,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...我们已经实施了颜色,翻译和切口差异,如下所示:

如果您发现此代码有帮助,请引用我们的论文:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
我们感谢NSF职业奖#1943349,MIT-IBM Watson AI实验室,Google,Adobe和Sony支持这项研究。 Google Tensorflow Research Cloud(TFRC)的Cloud TPU支持研究。我们感谢William S. Peebles和Yijun Li有用的评论。


