data efficient gans
1.0.0

Erzeugt nur 100 Bilder von Obama, mürrische Katzen, Pandas, die Brücke der Seufzen, den Medici-Brunnen, den Tempel des Himmels, ohne vor dem Training.
[Neu!] Pytorch-Training mit Diffaugment-Stylegan2-Pytorch ist jetzt verfügbar!
[Neu!] Unser Colab -Tutorial wird veröffentlicht!
[Neu!] FFHQ -Training wird unterstützt! Siehe das Diffaugment-Stil-Readme.
[Neu!] Zeit, um 100-Shot-Interpolationsvideos mit generate_gif.py zu generieren!
[Neu!] Unser Diffaugment-Biggan-Imagenet-Repo (für TPU-Training) wird veröffentlicht!
[Neu!] Unser Diffaugment-Biggan-Cifar Pytorch Repo wird veröffentlicht!
Dieses Repository enthält unsere Implementierung der differenzierbaren Augmentation (Diffaugment) sowohl in Pytorch als auch in Tensorflow. Es kann verwendet werden, um die Dateneffizienz für GaN -Training erheblich zu verbessern. Wir haben Diffaugment-Stylegan2 (Tensorflow) und Diffaugment-Stylegan2-Pytorch, Diffaugment-Biggan-Cifar (Pytorch) für GPU-Training und Diffaugment-Biggan-Imagenet (Tensorflow) für TPU-Training zur Verfügung gestellt.

Niedrig-Shot-Erzeugung ohne Voraberziehung. Mit Diffaugment kann unser Modell mit nur 100 Obama-Porträts, mürrischen Katzen oder Pandas aus unseren gesammelten 100-Schuss-Datensätzen, 160 Katzen oder 389 Hunden aus dem Animalface-Datensatz mit 256 × 256 Auflösung hochfreundliche Bilder erzeugen.
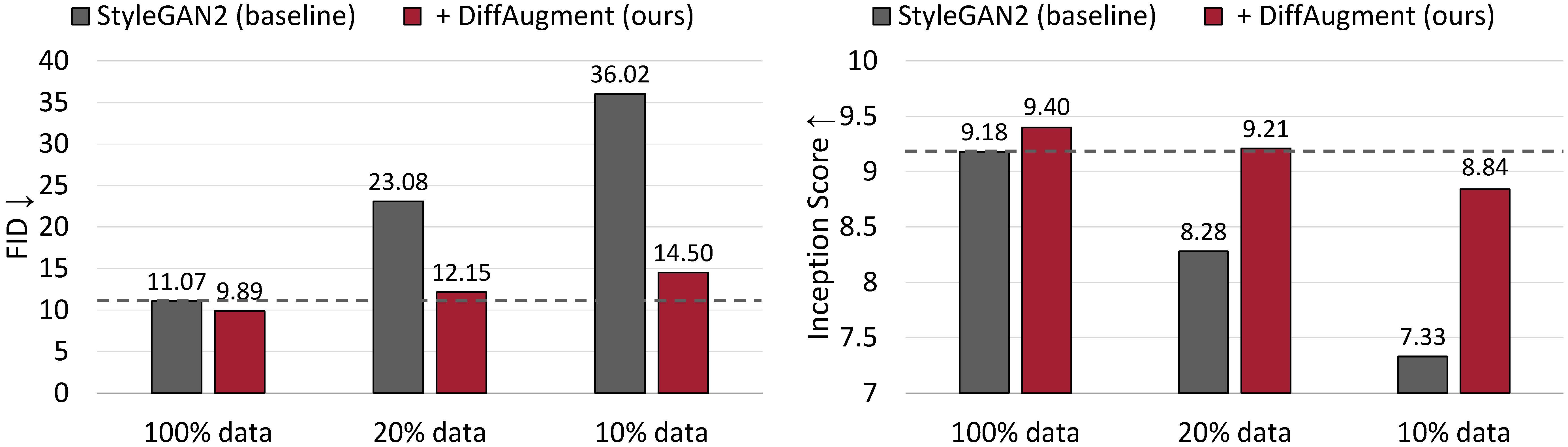
Bedingungslose Erzeugungsergebnisse zu CIFAR-10. Die Leistung von Stylegan2 verschlechtert sich drastisch, da weniger Trainingsdaten. Mit Diffaugment können wir mit nur 20% Trainingsdaten in grob mit seiner FID -FID -Leistung (IS) übereinstimmen und übertreffen.
Differenzierbare Augmentation für dateneffizientes GaN-Training
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu und Lied Han
MIT, Universität Tsinghua, Adobe Research, CMU
Arxiv

Überblick über die Differenzierung zur Aktualisierung von D (links) und G (rechts). Die Diffaugment wendet die Augmentation T sowohl auf die reale Probe x als auch auf den erzeugten Ausgang G (Z) an. Wenn wir G aktualisieren, müssen Gradienten über T (III) wieder propagiert werden, wodurch T den Eingang differenzierbar sein muss.
So generieren Sie ein Interpolationsvideo mit unseren vorgebildeten Modellen:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifoder um ein neues Modell zu trainieren:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 Sie können auch 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen oder der Ordner oder die eigenen Trainingsbilder ausprobieren. Weitere Informationen finden Sie in der Diffaugment-Stylegan2-Readme für die Abhängigkeiten und Details.
[Neu!] Pytorch Training ist jetzt verfügbar:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Um Stylegan2 + Diffaugment für die bedingungslose Generation auf den 100-Schuss-Datensätzen Cifar, FFHQ oder LSUN zu führen, lesen Sie bitte die Diffaugment-Stylegan2-Readme- oder Diffaugment-Stylegan2-Pytorch für die Pytorch-Version.
In der Diffaugment-Biggan-Cifar-Readme finden Sie Biggan + Diffaugment für die bedingte Erzeugung auf CIFAR (mit GPUs) und die Diffaugment-Biggan-Imagenet-Readme, um auf ImageNet (unter Verwendung von TPUs) zu laufen.
Um Ihnen dabei zu helfen, die Diffaugment in Ihrer eigenen Codebasis zu verwenden, bieten wir tragbare Different -Operationen sowohl von TensorFlow- als auch Pytorch -Versionen in Diffaugment_tf.py und diffaugment_pytorch.py bereit. Im Allgemeinen kann die Diffaugment in jedem Modell leicht übernommen werden, indem alle d (x) durch d (t (x)) ersetzt werden, wobei x echte Bilder oder gefälschte Bilder sein kann, D der Diskriminator ist und T der Diffaugment -Operation ist. Zum Beispiel,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Wir haben Farb-, Übersetzungs- und Ausschnittsdifferenzierung implementiert, wie sie unten sichtbar gemacht hat:

Wenn Sie diesen Code hilfreich finden, zitieren Sie bitte unser Papier:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Wir danken dem NSF Career Award #1943349, MIT-IBM Watson AI Lab, Google, Adobe und Sony für die Unterstützung dieser Forschung. Forschung, die mit Cloud -TPUs aus der TensorFlow Research Cloud (TFRC) von Google unterstützt wird. Wir danken William S. Peebles und Yijun Li für hilfreiche Kommentare.


