data efficient gans
1.0.0

Gerado usando apenas 100 imagens de Obama, gatos rabugentos, pandas, a ponte de suspiros, a fonte Medici, o templo do céu, sem pré-treinamento.
[NOVO!] Treinamento Pytorch com Difflaugment-Sylegan2-Pytorch já está disponível!
[NOVO!] Nosso tutorial do Colab foi lançado!
[Novo!] O treinamento FFHQ é suportado! Veja o readme de difnagment-stylegan2.
[Novo!] Hora de gerar vídeos de interpolação de 100 tiros com generate_gif.py!
[NOVO!] Nosso repo DiffAugment-Biggan-Imagenet (para treinamento de TPU) é lançado!
[NOVO!] Nosso repo de Pytorch DiffAugment-Biggan-Cifar é lançado!
Este repositório contém nossa implementação de aumento diferenciável (difíce de difundir) em Pytorch e Tensorflow. Pode ser usado para melhorar significativamente a eficiência dos dados para o treinamento da GaN. Fornecemos difinagment-estilogan2 (tensorflow) e difnagment-stylegan2-pytorch, difhagment-biggan-cifar (pytorch) para treinamento de GPU e difhagment-biggan-imagenet (tensorflow) para treinamento de TPU.

Geração de baixo tiro sem pré-treinamento. Com o Difflaugment, nosso modelo pode gerar imagens de alta fidelidade usando apenas 100 retratos de Obama, gatos mal-humorados ou pandas de nossos conjuntos de dados coletados de 100 tiros, 160 gatos ou 389 cães do conjunto de dados Animalface em resolução de 256 × 256.
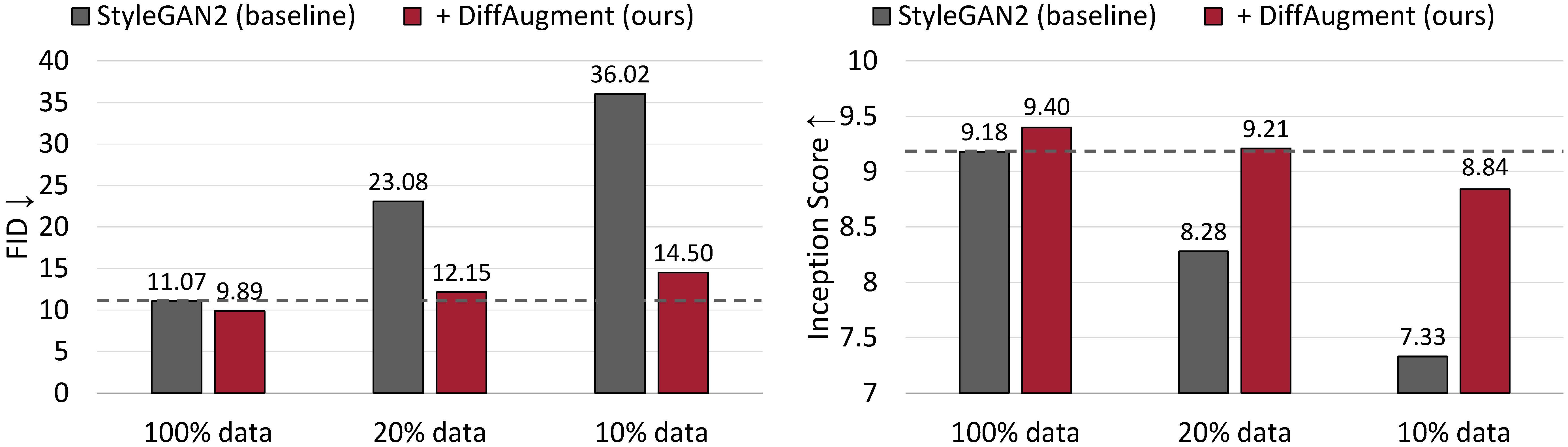
A geração incondicional resulta no CIFAR-10. O desempenho do Stylegan2 degrada drasticamente, dados menos dados de treinamento. Com o Difflaugment, somos capazes de corresponder aproximadamente ao FID e superar sua pontuação de início (IS) usando apenas 20% de dados de treinamento.
Aumentação diferenciável para treinamento GaN com eficiência de dados
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu e Song Han
MIT, Universidade de Tsinghua, Adobe Research, CMU
arxiv

Visão geral do DiffAugment para atualizar D (esquerda) e G (direita). O DiffAugment aplica o aumento t à amostra real X e à saída gerada G (z). Quando atualizamos G, os gradientes precisam ser propagados em volta através de t (III), que exige t para ser diferenciável da entrada.
Para gerar um vídeo de interpolação usando nossos modelos pré-treinados:
cd DiffAugment-stylegan2
python generate_gif.py -r mit-han-lab:DiffAugment-stylegan2-100-shot-obama.pkl -o obama.gifou para treinar um novo modelo:
python run_low_shot.py --dataset=100-shot-obama --num-gpus=4 Você também pode experimentar 100-shot-grumpy_cat , 100-shot-panda , 100-shot-bridge_of_sighs , 100-shot-medici_fountain , 100-shot-temple_of_heaven , 100-shot-wuzhen , ou a pasta que contém suas próprias imagens de treinamento. Consulte o Readme DiffAugment-Sylegan2 para as dependências e detalhes.
[Novo!] O treinamento Pytorch já está disponível:
cd DiffAugment-stylegan2-pytorch
python train.py --outdir=training-runs --data=https://data-efficient-gans.mit.edu/datasets/100-shot-obama.zip --gpus=1Para executar o StyleGan2 + Difabmentment para geração incondicional nos conjuntos de dados de 100 tiros, CIFAR, FFHQ ou LSUN, consulte o Readme de Difflaugment-Stylegan2 ou a difhagment-Stylegan2-Pytorch para a versão Pytorch.
Consulte o ReadMe DiffAugment-Biggan-Cifar para executar o Biggan + Difflaugment para geração condicional no CIFAR (usando GPUs) e o ReadMe DiffAugment-Biggan-Imagenet para ser executado no ImageNet (usando TPUs).
Para ajudá -lo a usar o Difflaugment em sua própria base de código, fornecemos operações portáteis de difusão das versões Tensorflow e Pytorch em difhaugment_tf.py e difhaugment_pytorch.py. Geralmente, a difusão pode ser facilmente adotada em qualquer modelo substituindo cada d (x) por d (t (x)) , onde x pode ser imagens reais ou imagens falsas, d é o discriminador e t é a operação de difusão. Por exemplo,
from DiffAugment_pytorch import DiffAugment
# from DiffAugment_tf import DiffAugment
policy = 'color,translation,cutout' # If your dataset is as small as ours (e.g.,
# hundreds of images), we recommend using the strongest Color + Translation + Cutout.
# For large datasets, try using a subset of transformations in ['color', 'translation', 'cutout'].
# Welcome to discover more DiffAugment transformations!
...
# Training loop: update D
reals = sample_real_images () # a batch of real images
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
real_scores = Discriminator ( DiffAugment ( reals , policy = policy ))
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating D's loss based on real_scores and fake_scores...
...
...
# Training loop: update G
z = sample_latent_vectors ()
fakes = Generator ( z ) # a batch of fake images
fake_scores = Discriminator ( DiffAugment ( fakes , policy = policy ))
# Calculating G's loss based on fake_scores...
...Implementamos cores, tradução e recutas, conforme visualizado abaixo:

Se você achar esse código útil, cite nosso artigo:
@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Agradecemos ao NSF Career Award #1943349, o MIT-IBM Watson AI Lab, Google, Adobe e Sony por apoiar esta pesquisa. Pesquisas suportadas com TPUs em nuvem da Cloud de pesquisa Tensorflow do Google (TFRC). Agradecemos a William S. Peebles e Yijun Li pelos comentários úteis.


